LLMs are Overconfident: Evaluating Confidence Interval Calibration with FermiEval
作者: Elliot L. Epstein, John Winnicki, Thanawat Sornwanee, Rajat Dwaraknath
分类: stat.ME, cs.AI, cs.LG
发布日期: 2025-10-30
备注: 8 pages
💡 一句话要点
FermiEval评估LLM置信区间校准,揭示其过度自信问题并提出校正方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 置信区间 不确定性量化 费米估计 共形预测 校准 过度自信
📋 核心要点
- 现有LLM在数值估计中无法准确量化不确定性,导致置信区间不可靠。
- 论文提出FermiEval基准,并结合共形预测等方法校正LLM的置信区间。
- 实验表明,校正后的置信区间覆盖率显著提升,Winkler得分降低54%。
📝 摘要(中文)
大型语言模型(LLM)在数值估计方面表现出色,但在正确量化不确定性方面存在困难。本文研究了LLM构建其答案置信区间的准确性,发现它们系统性地过度自信。为了评估这种行为,我们引入了FermiEval,这是一个费米式估计问题基准,具有严格的置信区间覆盖率和锐度评分规则。在几个现代模型中,标称99%的置信区间平均仅覆盖真实答案的65%。通过基于共形预测的方法调整区间,我们获得了准确的99%观测覆盖率,Winkler区间得分降低了54%。我们还提出了直接对数概率引出和分位数调整方法,进一步降低了高置信水平下的过度自信。最后,我们提出了一个感知隧道理论,解释了LLM表现出过度自信的原因:在不确定性下进行推理时,它们表现得好像是从其推断分布的截断区域进行采样,忽略了尾部。
🔬 方法详解
问题定义:论文关注LLM在数值估计任务中置信区间的校准问题。现有LLM虽然在数值估计上表现良好,但无法准确估计答案的不确定性,导致生成的置信区间往往过于自信,实际覆盖率远低于标称覆盖率。这种过度自信会影响LLM在实际应用中的可靠性。
核心思路:论文的核心思路是通过校准方法调整LLM生成的置信区间,使其更准确地反映答案的不确定性。具体来说,论文探索了基于共形预测、直接对数概率引出和分位数调整等方法来校正LLM的置信区间,使其覆盖率更接近标称覆盖率。
技术框架:论文主要包含以下几个阶段:1) 提出FermiEval基准,用于评估LLM置信区间的校准情况;2) 使用FermiEval评估现有LLM的置信区间校准情况,发现其存在过度自信问题;3) 提出基于共形预测、直接对数概率引出和分位数调整等方法来校正LLM的置信区间;4) 在FermiEval上评估校正方法的有效性。
关键创新:论文的关键创新在于:1) 提出了FermiEval基准,为评估LLM置信区间校准提供了一个标准化的平台;2) 探索了多种校正方法,包括基于共形预测的非参数方法和基于概率引出的参数方法,为解决LLM过度自信问题提供了多种选择;3) 提出了感知隧道理论,尝试解释LLM过度自信的原因。
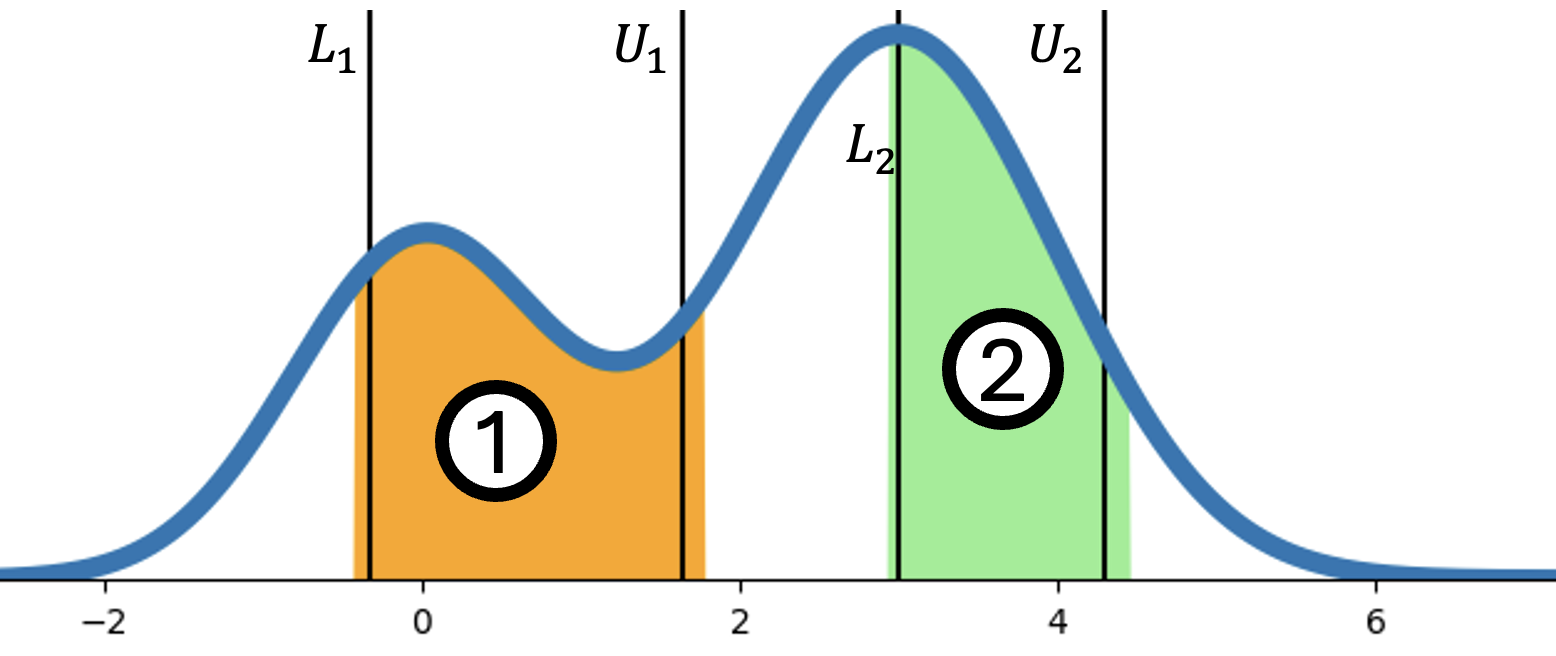
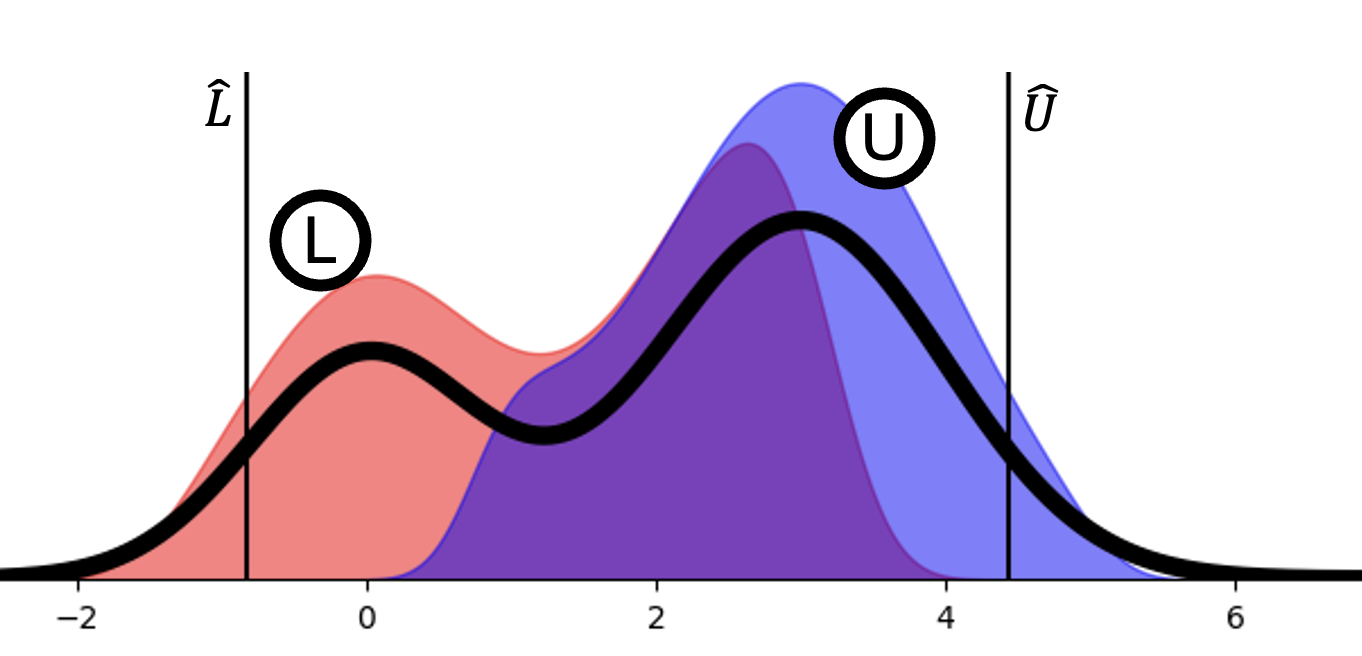
关键设计:FermiEval基准包含一系列费米式估计问题,每个问题都有一个真实答案。论文使用Winkler区间得分来评估置信区间的质量,该得分同时考虑了置信区间的覆盖率和锐度。共形预测方法通过调整置信区间的上下界来保证覆盖率,而直接对数概率引出方法则通过调整LLM的概率分布来降低过度自信。分位数调整方法则是直接调整预测的分位数,使其更符合真实分布。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有LLM在FermiEval基准上表现出显著的过度自信,标称99%的置信区间平均仅覆盖真实答案的65%。通过基于共形预测的方法进行校正后,置信区间的覆盖率可以达到99%,Winkler区间得分降低了54%。直接对数概率引出和分位数调整方法也能够在高置信水平下有效降低过度自信。
🎯 应用场景
该研究成果可应用于需要可靠数值估计的场景,例如金融预测、风险评估、科学计算等。通过校准LLM的置信区间,可以提高其在这些领域的应用价值,并降低因过度自信而导致的决策风险。未来,该研究可以扩展到其他类型的不确定性估计任务,例如图像识别中的不确定性量化。
📄 摘要(原文)
Large language models (LLMs) excel at numerical estimation but struggle to correctly quantify uncertainty. We study how well LLMs construct confidence intervals around their own answers and find that they are systematically overconfident. To evaluate this behavior, we introduce FermiEval, a benchmark of Fermi-style estimation questions with a rigorous scoring rule for confidence interval coverage and sharpness. Across several modern models, nominal 99\% intervals cover the true answer only 65\% of the time on average. With a conformal prediction based approach that adjusts the intervals, we obtain accurate 99\% observed coverage, and the Winkler interval score decreases by 54\%. We also propose direct log-probability elicitation and quantile adjustment methods, which further reduce overconfidence at high confidence levels. Finally, we develop a perception-tunnel theory explaining why LLMs exhibit overconfidence: when reasoning under uncertainty, they act as if sampling from a truncated region of their inferred distribution, neglecting its tails.