How Similar Are Grokipedia and Wikipedia? A Multi-Dimensional Textual and Structural Comparison
作者: Taha Yasseri, Saeedeh Mohammadi
分类: cs.CY, cs.AI, cs.SI
发布日期: 2025-10-30 (更新: 2026-01-31)
备注: 20 pages, 7 figures, updated with a larger sample size of 20,000 articles, better text cleaning procedure + Reference analysis, topical analysis
💡 一句话要点
对比Grokipedia与维基百科:多维度文本与结构分析揭示AI生成百科全书的潜在偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成内容 百科全书 知识治理 文本分析 偏见检测
📋 核心要点
- 维基百科被认为存在意识形态和结构性偏见,而Grokipedia旨在通过AI生成“真实”条目来解决这一问题,但其能否避免偏见仍是核心问题。
- 本研究通过大规模计算比较,从词汇、结构、语义等多维度评估Grokipedia与维基百科的相似性,分析AI生成内容与既定编辑规范的差异。
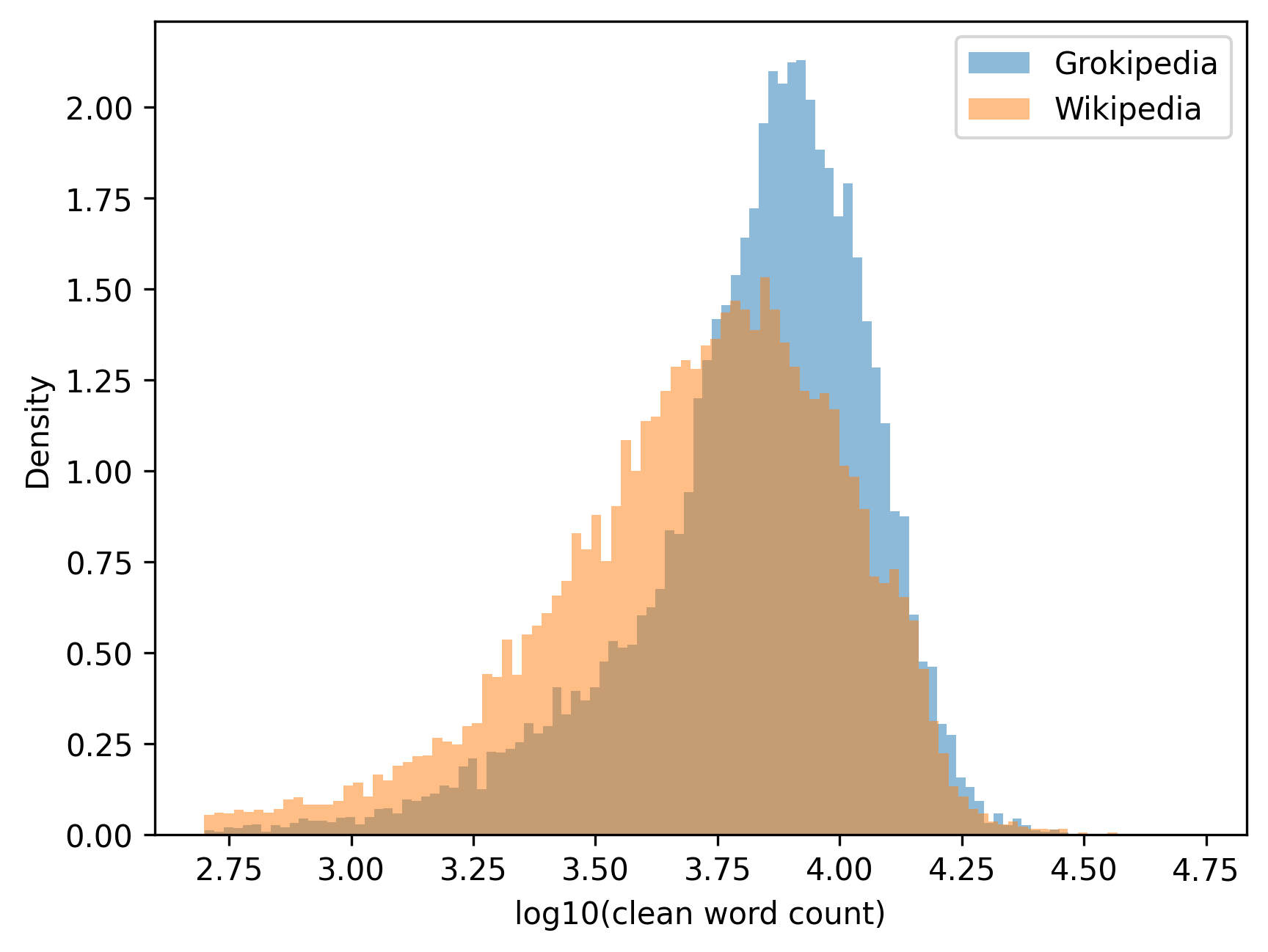
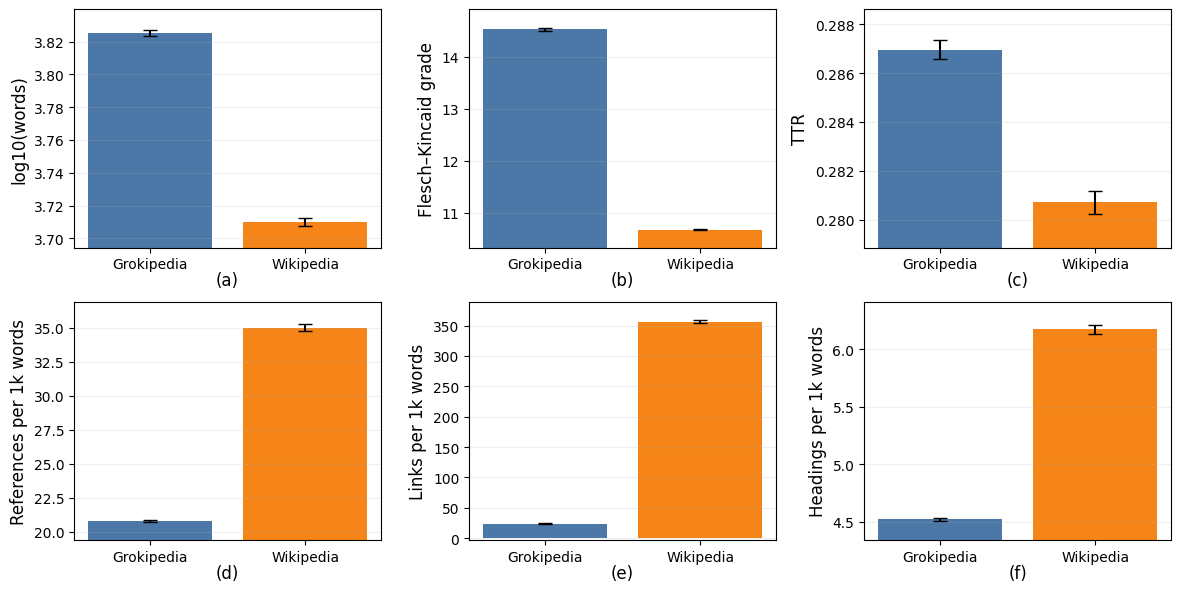
- 实验发现Grokipedia文章更长但参考文献更少,且部分文章在政治偏见上存在右倾,尤其在政治、历史和宗教相关条目中。
📝 摘要(中文)
Grokipedia是由埃隆·马斯克的xAI开发的AI生成百科全书,旨在回应维基百科中被认为存在的意识形态和结构性偏见,目标是使用Grok大型语言模型生成“真实”的条目。然而,AI驱动的替代方案是否能够摆脱人工编辑平台的偏见和局限性仍不清楚。本研究对来自编辑次数最多的20000个英文维基百科页面中的17790个匹配文章对进行了大规模计算比较。通过词汇丰富度、可读性、参考文献密度、结构特征和语义相似性等指标,评估了两个平台在形式和内容上的相似程度。研究发现,Grokipedia的文章明显更长,但每个单词包含的参考文献明显更少。此外,Grokipedia的内容分为两个不同的组:一组在语义和风格上与维基百科保持一致,另一组则截然不同。在不相似的文章中,我们观察到引用的来源在政治偏见上存在系统性的右倾,主要集中在与政治、历史和宗教相关的条目中。更广泛地说,研究结果表明,AI生成的百科全书内容偏离了既定的编辑规范,倾向于叙述扩展而非基于引用的验证,从而引发了对自动化信息系统中知识的透明度、来源和治理的质疑。
🔬 方法详解
问题定义:论文旨在评估由AI生成的百科全书Grokipedia与人工编辑的维基百科在内容和结构上的相似性,并探究Grokipedia是否能够避免维基百科中存在的偏见。现有方法的痛点在于缺乏对AI生成百科全书的系统性评估,无法量化其与传统百科全书的差异和潜在偏见。
核心思路:论文的核心思路是通过多维度的量化指标,对Grokipedia和维基百科的大量文章进行对比分析。这些指标涵盖了文本的词汇丰富度、可读性、参考文献密度、结构特征以及语义相似性,从而全面评估两个平台在内容和形式上的差异。通过分析这些差异,可以揭示AI生成内容是否偏离了既定的编辑规范,以及是否存在潜在的偏见。
技术框架:研究的技术框架主要包括以下几个阶段: 1. 数据收集与匹配:从维基百科中选取编辑次数最多的20000个英文页面,并与Grokipedia中对应的17790个文章对进行匹配。 2. 特征提取:针对每个文章对,提取词汇丰富度、可读性、参考文献密度、结构特征和语义相似性等多个维度的特征。 3. 统计分析:对提取的特征进行统计分析,比较Grokipedia和维基百科在各个维度上的差异。 4. 偏见分析:针对语义差异较大的文章,分析其引用的来源,评估是否存在政治偏见。
关键创新:论文最重要的技术创新点在于其多维度的量化评估方法,能够全面地比较AI生成百科全书与人工编辑百科全书的差异。与现有方法相比,该方法不仅关注文本的语义相似性,还考虑了词汇、结构和参考文献等多个维度,从而更全面地评估了AI生成内容的质量和潜在偏见。
关键设计:论文的关键设计包括: * 词汇丰富度:使用Type-Token Ratio (TTR) 等指标衡量。 * 可读性:使用Flesch Reading Ease等指标衡量。 * 参考文献密度:计算每词的参考文献数量。 * 结构特征:分析文章的章节数量、标题长度等。 * 语义相似性:使用预训练语言模型(如BERT)计算文章的语义向量,并计算余弦相似度。 * 偏见分析:分析引用的来源的政治倾向,例如使用AllSides等工具。
🖼️ 关键图片
📊 实验亮点
研究发现,Grokipedia的文章长度显著增加,但参考文献密度降低。语义分析表明,Grokipedia的内容分为两组,一组与维基百科相似,另一组则差异较大。在差异较大的文章中,引用的来源在政治偏见上存在右倾现象,尤其是在政治、历史和宗教相关条目中。这些结果表明,AI生成内容可能偏离既定的编辑规范,更倾向于叙述而非引用。
🎯 应用场景
该研究成果可应用于评估和改进AI生成内容的质量和可靠性,尤其是在知识密集型领域,如百科全书、新闻报道和教育资源。通过量化AI生成内容与人工编辑内容的差异,可以帮助开发者识别和纠正AI模型的偏见,提高其生成内容的准确性和客观性。此外,该研究也为自动化信息系统的知识治理提供了参考。
📄 摘要(原文)
The launch of Grokipedia, an AI-generated encyclopedia developed by Elon Musk's xAI, was presented as a response to perceived ideological and structural biases in Wikipedia, aiming to produce "truthful" entries using the Grok large language model. Yet whether an AI-driven alternative can escape the biases and limitations of human-edited platforms remains unclear. This study conducts a large-scale computational comparison of 17,790 matched article pairs from the 20,000 most-edited English Wikipedia pages. Using metrics spanning lexical richness, readability, reference density, structural features, and semantic similarity, we assess how closely the two platforms align in form and substance. We find that Grokipedia articles are substantially longer and contain significantly fewer references per word. Moreover, Grokipedia's content divides into two distinct groups: one that remains semantically and stylistically aligned with Wikipedia, and another that diverges sharply. Among the dissimilar articles, we observe a systematic rightward shift in the political bias of cited sources, concentrated primarily in entries related to politics, history, and religion. More broadly, the findings indicate that AI-generated encyclopedic content departs from established editorial norms, favoring narrative expansion over citation-based verification, raising questions about transparency, provenance, and the governance of knowledge in automated information systems.