Cross-Platform Evaluation of Reasoning Capabilities in Foundation Models
作者: J. de Curtò, I. de Zarzà, Pablo García, Jordi Cabot
分类: cs.AI, cs.CL
发布日期: 2025-10-30
💡 一句话要点
跨平台评估基础模型推理能力,揭示训练数据质量的重要性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 基础模型 推理能力 跨平台评估 基准测试 训练数据质量 模型选择 HPC 云平台
📋 核心要点
- 现有基础模型推理能力的评估缺乏统一的跨平台基准,难以在不同计算资源上进行有效比较和选择。
- 论文构建了一个与基础设施无关的基准,在HPC、云平台和大学集群上评估了多个基础模型在不同学术领域的推理能力。
- 实验结果表明,训练数据质量对模型推理能力的影响大于模型规模,并为不同应用场景的模型选择提供了指导。
📝 摘要(中文)
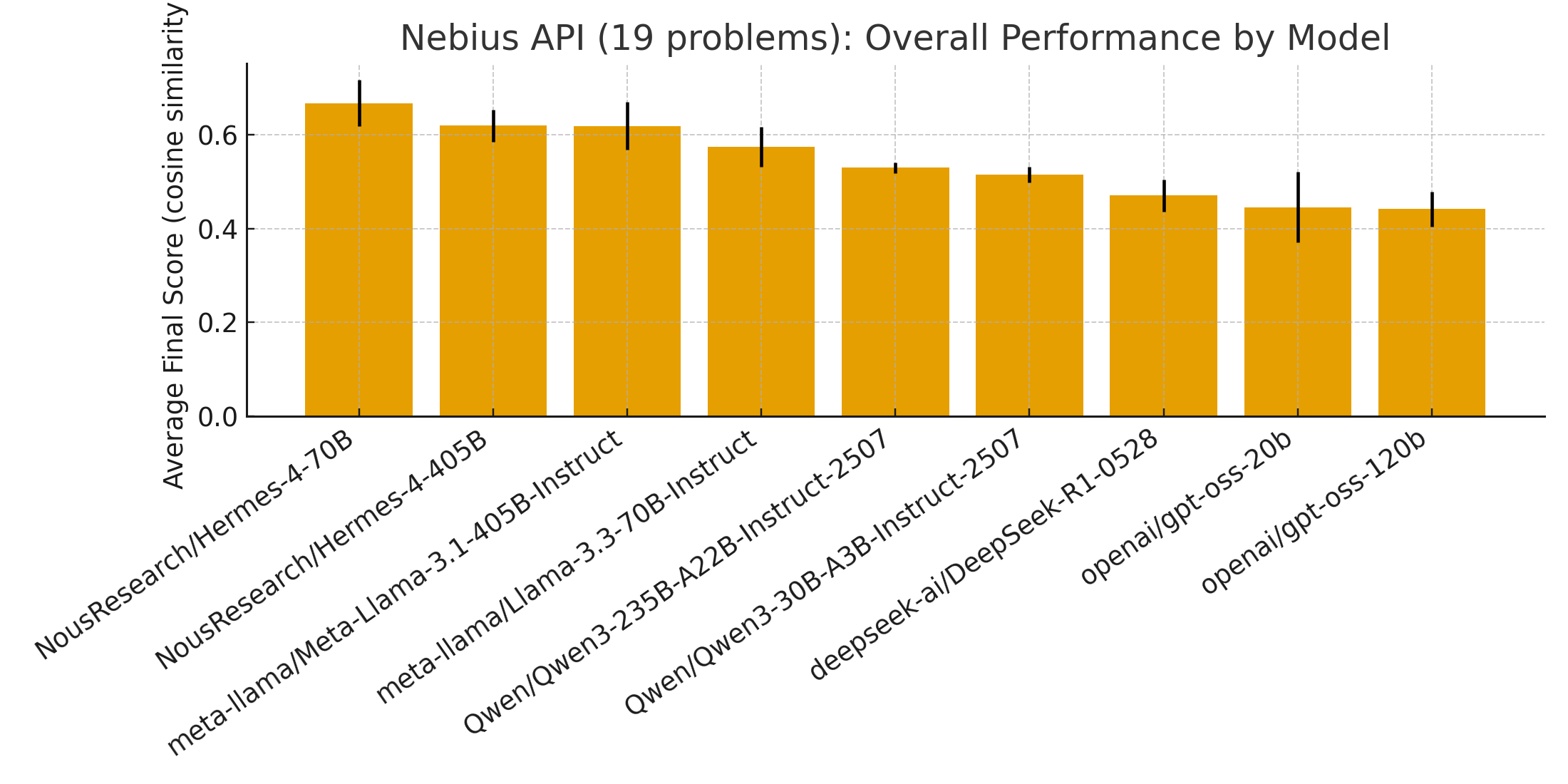
本文对当前基础模型的推理能力进行了全面的跨平台评估,建立了一个与基础设施无关的基准,涵盖三种计算范式:HPC超级计算(MareNostrum 5)、云平台(Nebius AI Studio)和大学集群(配备八个H200 GPU的节点)。我们评估了15个基础模型在79个问题上的表现,这些问题涵盖八个学术领域(物理、数学、化学、经济学、生物学、统计学、微积分和优化),通过三个实验阶段进行:(1)基线建立:在MareNostrum 5上评估六个模型(Mixtral-8x7B、Phi-3、LLaMA 3.1-8B、Gemma-2-9b、Mistral-7B、OLMo-7B)在19个问题上的表现,建立方法论和参考性能;(2)基础设施验证:在大学集群(七个模型,包括Falcon-Mamba状态空间架构)和Nebius AI Studio(九个最先进的模型:Hermes-4 70B/405B、LLaMA 3.1-405B/3.3-70B、Qwen3 30B/235B、DeepSeek-R1、GPT-OSS 20B/120B)上重复19个问题的基准测试,以确认与基础设施无关的可重复性;(3)扩展评估:在大学集群和Nebius平台上进行完整的79个问题的评估,以大规模地探测跨架构多样性的泛化能力。研究结果挑战了传统的缩放假设,确定训练数据质量比模型大小更重要,并为教育、生产和研究环境中的模型选择提供了可操作的指导。三基础设施方法和79个问题的基准测试能够纵向跟踪基础模型演进过程中的推理能力。
🔬 方法详解
问题定义:论文旨在解决基础模型推理能力评估缺乏统一标准和跨平台比较的问题。现有方法通常依赖于特定硬件或平台,难以推广到不同计算资源环境,并且对模型性能的评估不够全面,无法有效指导实际应用中的模型选择。
核心思路:论文的核心思路是建立一个与基础设施无关的基准,通过在不同的计算平台上(HPC、云平台、大学集群)对多个基础模型进行统一的评估,从而消除硬件差异带来的影响,更客观地反映模型的真实推理能力。同时,选择涵盖多个学术领域的79个问题,以更全面地评估模型的泛化能力。
技术框架:论文的评估框架包含三个主要阶段:(1)基线建立:选择MareNostrum 5作为基准平台,评估六个模型的性能,建立评估方法和参考性能。(2)基础设施验证:在大学集群和Nebius AI Studio上重复基准测试,验证评估结果的可重复性,确保评估框架与基础设施无关。(3)扩展评估:在大学集群和Nebius平台上进行完整的79个问题的评估,考察模型在不同架构和规模下的泛化能力。
关键创新:论文的关键创新在于提出了一个与基础设施无关的评估方法,能够更客观地评估基础模型的推理能力。此外,通过大规模的实验,揭示了训练数据质量对模型性能的重要性,挑战了传统的模型规模越大性能越好的假设。
关键设计:论文的关键设计包括:(1)选择涵盖多个学术领域的79个问题,以全面评估模型的泛化能力。(2)在不同的计算平台上进行评估,消除硬件差异的影响。(3)采用统一的评估指标,确保评估结果的可比性。(4)对评估结果进行深入分析,揭示影响模型性能的关键因素。
🖼️ 关键图片


📊 实验亮点
实验结果表明,训练数据质量对模型推理能力的影响大于模型规模。例如,某些小规模模型在特定任务上的表现甚至优于大规模模型。此外,该研究还为不同应用场景的模型选择提供了指导,例如,对于计算资源有限的环境,可以选择训练数据质量高的轻量级模型。
🎯 应用场景
该研究成果可应用于教育、生产和研究等多个领域。在教育领域,可以帮助学生和教师选择合适的模型进行学习和研究。在生产领域,可以指导企业选择合适的模型来解决实际问题,提高生产效率。在研究领域,可以为研究人员提供一个统一的基准,用于评估和比较不同模型的性能,推动基础模型的发展。
📄 摘要(原文)
This paper presents a comprehensive cross-platform evaluation of reasoning capabilities in contemporary foundation models, establishing an infrastructure-agnostic benchmark across three computational paradigms: HPC supercomputing (MareNostrum 5), cloud platforms (Nebius AI Studio), and university clusters (a node with eight H200 GPUs). We evaluate 15 foundation models across 79 problems spanning eight academic domains (Physics, Mathematics, Chemistry, Economics, Biology, Statistics, Calculus, and Optimization) through three experimental phases: (1) Baseline establishment: Six models (Mixtral-8x7B, Phi-3, LLaMA 3.1-8B, Gemma-2-9b, Mistral-7B, OLMo-7B) evaluated on 19 problems using MareNostrum 5, establishing methodology and reference performance; (2) Infrastructure validation: The 19-problem benchmark repeated on university cluster (seven models including Falcon-Mamba state-space architecture) and Nebius AI Studio (nine state-of-the-art models: Hermes-4 70B/405B, LLaMA 3.1-405B/3.3-70B, Qwen3 30B/235B, DeepSeek-R1, GPT-OSS 20B/120B) to confirm infrastructure-agnostic reproducibility; (3) Extended evaluation: Full 79-problem assessment on both university cluster and Nebius platforms, probing generalization at scale across architectural diversity. The findings challenge conventional scaling assumptions, establish training data quality as more critical than model size, and provide actionable guidelines for model selection across educational, production, and research contexts. The tri-infrastructure methodology and 79-problem benchmark enable longitudinal tracking of reasoning capabilities as foundation models evolve.