Unveiling Intrinsic Text Bias in Multimodal Large Language Models through Attention Key-Space Analysis
作者: Xinhan Zheng, Huyu Wu, Xueting Wang, Haiyun Jiang
分类: cs.AI, cs.MM
发布日期: 2025-10-30
💡 一句话要点
通过注意力键空间分析揭示多模态大语言模型中固有的文本偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 文本偏见 注意力机制 键空间分析 视觉-语言推理
📋 核心要点
- 多模态大语言模型在视觉-语言任务中过度依赖文本输入,忽略视觉信息,导致推理能力受限。
- 该研究提出文本偏见源于模型内部架构,即视觉键向量在文本键空间中是分布外的。
- 通过分析LLaVA和Qwen2.5-VL的键向量分布,验证了视觉键和文本键占据不同子空间,证实了内在不对齐是文本偏见的根源。
📝 摘要(中文)
多模态大语言模型(MLLMs)在处理视觉-语言数据时,表现出对文本输入的明显偏好,这限制了它们从视觉证据中进行有效推理的能力。与先前将这种文本偏见归因于数据不平衡或指令微调等外部因素的研究不同,本文提出该偏见源于模型的内部架构。具体而言,我们假设视觉键向量(Visual Keys)相对于仅在语言预训练期间学习的文本键空间而言是分布外的(OOD)。因此,这些视觉键在注意力计算期间接收到系统性地较低的相似度分数,导致它们在上下文表示中未被充分利用。为了验证这一假设,我们从LLaVA和Qwen2.5-VL中提取了键向量,并使用定性(t-SNE)和定量(Jensen-Shannon散度)方法分析了它们的分布结构。结果提供了直接证据,表明视觉键和文本键在注意力空间内占据着明显不同的子空间。模态间差异在统计上显著,超过模态内变化几个数量级。这些发现表明,文本偏见源于注意力键空间内的内在不对齐,而不仅仅是来自外部数据因素。
🔬 方法详解
问题定义:多模态大语言模型在处理视觉-语言任务时,存在严重的文本偏见问题,即模型更倾向于依赖文本信息进行推理,而忽略视觉信息。现有的研究通常将这种偏见归因于外部因素,例如训练数据的不平衡或者指令微调过程中的偏差。然而,这些解释并不能完全解释文本偏见的内在机制。
核心思路:本文的核心思路是认为文本偏见源于多模态大语言模型内部的注意力机制。具体来说,视觉信息经过编码后得到的视觉键向量,与模型在纯文本预训练阶段学习到的文本键空间存在分布上的差异。这种差异导致视觉键向量在注意力计算过程中获得的相似度分数较低,从而使得视觉信息在最终的上下文表示中被弱化。
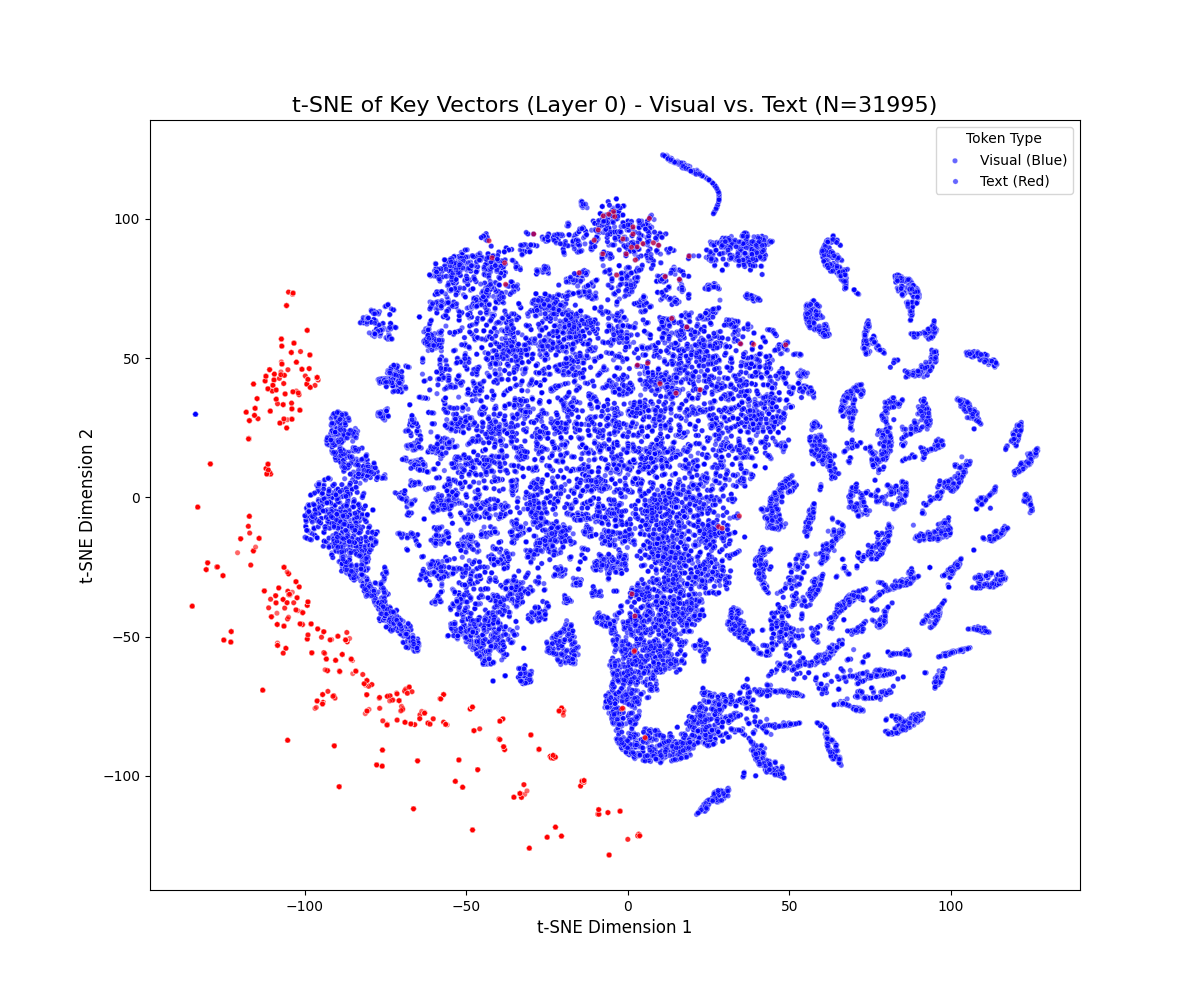
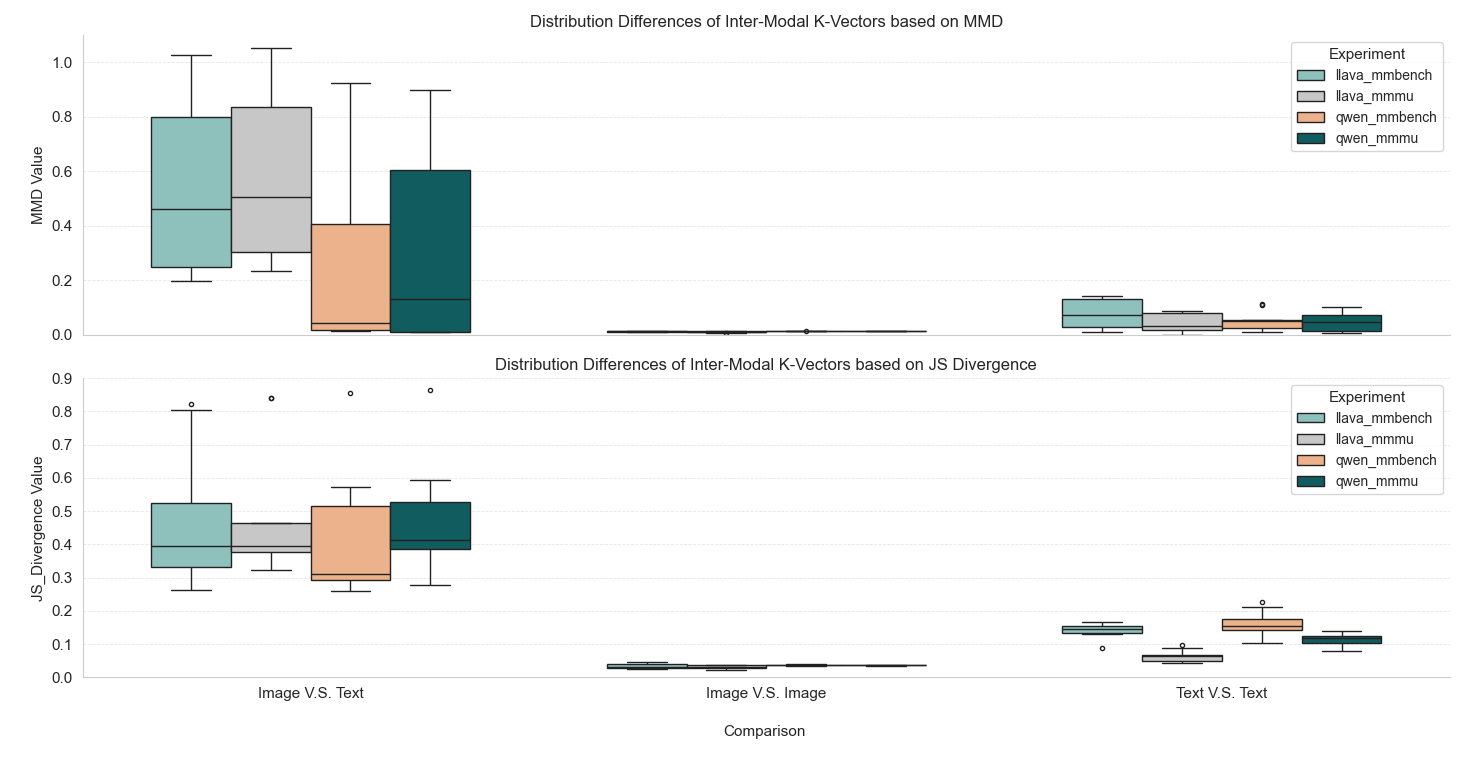
技术框架:本文的技术框架主要包括以下几个步骤:首先,从预训练好的多模态大语言模型(例如LLaVA和Qwen2.5-VL)中提取注意力层的键向量,包括文本键向量和视觉键向量。然后,使用t-SNE等降维方法对这些键向量进行可视化,从而定性地观察它们的分布情况。此外,使用Jensen-Shannon散度等指标来定量地衡量文本键空间和视觉键空间之间的差异。
关键创新:本文最重要的技术创新在于提出了文本偏见源于模型内部注意力机制的假设,并通过实验验证了视觉键向量和文本键向量在注意力空间中存在显著的分布差异。这种内在不对齐是导致文本偏见的关键因素,而不仅仅是外部数据因素。
关键设计:本文的关键设计包括:1) 选择LLaVA和Qwen2.5-VL作为研究对象,因为它们是具有代表性的多模态大语言模型。2) 使用t-SNE进行定性分析,直观地展示键向量的分布情况。3) 使用Jensen-Shannon散度进行定量分析,精确地衡量模态间和模态内的差异。4) 通过比较模态间和模态内的差异,验证了模态间差异的显著性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,视觉键和文本键在注意力空间内占据着明显不同的子空间,模态间差异的Jensen-Shannon散度显著高于模态内差异,超过模态内变化几个数量级。这为文本偏见源于注意力键空间内的内在不对齐提供了直接证据,挑战了以往认为文本偏见主要源于外部数据因素的观点。
🎯 应用场景
该研究成果有助于改进多模态大语言模型的设计,减少文本偏见,提升模型对视觉信息的利用率,从而提高模型在视觉问答、图像描述、视觉推理等任务上的性能。此外,该研究也为理解多模态模型内部机制提供了新的视角,有助于开发更可靠、更公平的多模态人工智能系统。
📄 摘要(原文)
Multimodal large language models (MLLMs) exhibit a pronounced preference for textual inputs when processing vision-language data, limiting their ability to reason effectively from visual evidence. Unlike prior studies that attribute this text bias to external factors such as data imbalance or instruction tuning, we propose that the bias originates from the model's internal architecture. Specifically, we hypothesize that visual key vectors (Visual Keys) are out-of-distribution (OOD) relative to the text key space learned during language-only pretraining. Consequently, these visual keys receive systematically lower similarity scores during attention computation, leading to their under-utilization in the context representation. To validate this hypothesis, we extract key vectors from LLaVA and Qwen2.5-VL and analyze their distributional structures using qualitative (t-SNE) and quantitative (Jensen-Shannon divergence) methods. The results provide direct evidence that visual and textual keys occupy markedly distinct subspaces within the attention space. The inter-modal divergence is statistically significant, exceeding intra-modal variation by several orders of magnitude. These findings reveal that text bias arises from an intrinsic misalignment within the attention key space rather than solely from external data factors.