SecureReviewer: Enhancing Large Language Models for Secure Code Review through Secure-aware Fine-tuning
作者: Fang Liu, Simiao Liu, Yinghao Zhu, Xiaoli Lian, Li Zhang
分类: cs.SE, cs.AI, cs.CL
发布日期: 2025-10-30
备注: Accepted by ICSE 2026. Code and data: https://github.com/SIMIAO515/SecureReviewer
💡 一句话要点
SecureReviewer:通过安全感知微调增强大型语言模型以实现安全代码审查
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全代码审查 大型语言模型 安全感知微调 RAG SecureBLEU 软件安全 代码漏洞检测
📋 核心要点
- 现有基于LLM的代码审查方法在识别和解决安全漏洞方面存在不足,缺乏针对安全问题的有效训练和评估。
- SecureReviewer通过构建安全代码审查数据集,并采用安全感知微调策略,提升LLM在安全问题识别和修复建议方面的能力。
- 实验结果表明,SecureReviewer在安全问题检测准确性和审查意见质量方面优于现有方法,证明了其有效性。
📝 摘要(中文)
在开发生命周期的早期识别和解决安全问题对于减轻软件系统的长期负面影响至关重要。代码审查是一种有效的实践,使开发人员能够在集成到代码库之前检查其团队成员的代码。为了简化审查意见的生成,已经提出了各种自动化代码审查方法,其中基于LLM的方法显著提高了自动化审查生成的能力。然而,现有模型主要关注通用代码审查,它们在识别和解决安全相关问题方面的有效性仍未得到充分探索。此外,将现有的代码审查方法应用于安全问题面临着数据稀缺和评估指标不足等重大挑战。为了解决这些限制,我们提出了一种名为SecureReviewer的新方法,旨在增强LLM在代码审查期间识别和解决安全相关问题的能力。具体来说,我们首先构建一个专门用于训练和评估安全代码审查能力的数据集。利用该数据集,我们通过提出的安全感知微调策略对LLM进行微调,以生成能够有效识别安全问题并提供修复建议的代码审查意见。为了减轻LLM中的幻觉并提高其输出的可靠性,我们集成了RAG技术,该技术将生成的意见建立在特定领域的安全知识之上。此外,我们还引入了一种名为SecureBLEU的新评估指标,旨在评估审查意见在解决安全问题方面的有效性。实验结果表明,SecureReviewer在安全问题检测准确性以及生成的审查意见的整体质量和实用性方面均优于最先进的基线。
🔬 方法详解
问题定义:现有基于LLM的代码审查方法主要关注通用代码审查,缺乏对安全漏洞的针对性检测和修复能力。现有方法在数据稀缺和评估指标不足的情况下,难以有效应用于安全代码审查场景。因此,如何提升LLM在安全代码审查中的性能,是一个亟待解决的问题。
核心思路:SecureReviewer的核心思路是通过构建安全代码审查数据集,并采用安全感知微调策略,使LLM能够更好地识别和解决代码中的安全问题。同时,利用RAG技术增强LLM的可靠性,并设计新的评估指标来衡量安全代码审查的效果。
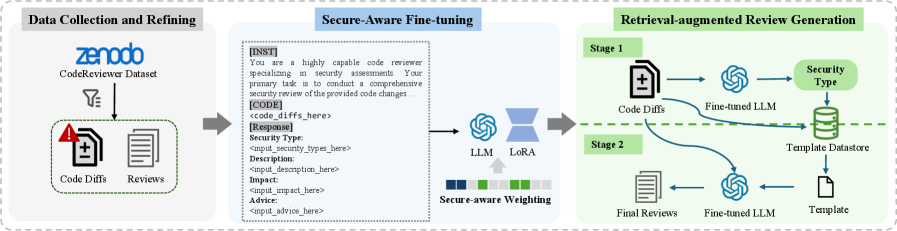
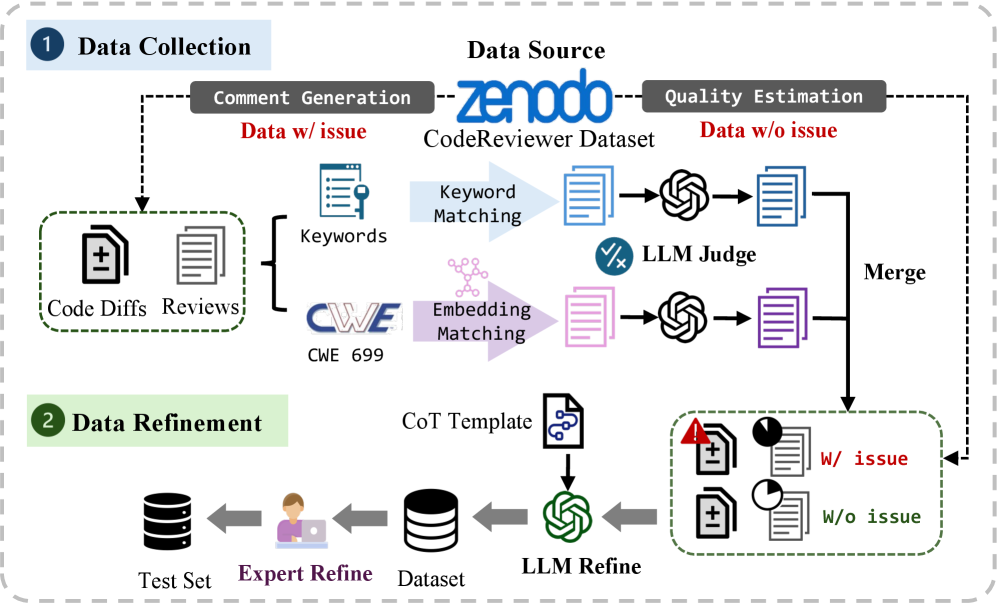
技术框架:SecureReviewer主要包含以下几个模块:1) 安全代码审查数据集构建模块,用于收集和标注安全相关的代码审查数据。2) 安全感知微调模块,用于利用数据集对LLM进行微调,使其具备安全代码审查能力。3) RAG集成模块,用于将领域知识融入LLM的生成过程中,减少幻觉。4) SecureBLEU评估模块,用于评估生成的代码审查意见在解决安全问题方面的有效性。
关键创新:SecureReviewer的关键创新在于:1) 构建了专门用于安全代码审查的数据集,解决了数据稀缺的问题。2) 提出了安全感知微调策略,有效提升了LLM在安全问题识别和修复方面的能力。3) 引入了SecureBLEU评估指标,更准确地衡量了安全代码审查的效果。
关键设计:安全感知微调策略可能包括:1) 使用对比学习方法,区分安全和不安全的代码片段。2) 设计特定的损失函数,例如关注安全漏洞的召回率。3) 调整LLM的参数,使其更关注代码中的安全相关特征。RAG集成可能使用向量数据库存储安全知识,并使用相似度搜索来检索相关信息。
🖼️ 关键图片

📊 实验亮点
SecureReviewer在安全问题检测准确性和审查意见质量方面均优于现有方法。实验结果表明,SecureReviewer在安全漏洞检测方面取得了显著的性能提升,并且生成的代码审查意见更具实用性和可操作性。SecureBLEU评估指标也更准确地反映了安全代码审查的效果。
🎯 应用场景
SecureReviewer可应用于软件开发的安全代码审查环节,帮助开发人员尽早发现和修复安全漏洞,降低软件安全风险。该研究成果有助于提升软件系统的整体安全性,减少因安全问题造成的经济损失和声誉损害。未来,该方法可扩展到其他安全相关的代码分析任务,例如漏洞预测和安全测试。
📄 摘要(原文)
Identifying and addressing security issues during the early phase of the development lifecycle is critical for mitigating the long-term negative impacts on software systems. Code review serves as an effective practice that enables developers to check their teammates' code before integration into the codebase. To streamline the generation of review comments, various automated code review approaches have been proposed, where LLM-based methods have significantly advanced the capabilities of automated review generation. However, existing models primarily focus on general-purpose code review, their effectiveness in identifying and addressing security-related issues remains underexplored. Moreover, adapting existing code review approaches to target security issues faces substantial challenges, including data scarcity and inadequate evaluation metrics. To address these limitations, we propose SecureReviewer, a new approach designed for enhancing LLMs' ability to identify and resolve security-related issues during code review. Specifically, we first construct a dataset tailored for training and evaluating secure code review capabilities. Leveraging this dataset, we fine-tune LLMs to generate code review comments that can effectively identify security issues and provide fix suggestions with our proposed secure-aware fine-tuning strategy. To mitigate hallucination in LLMs and enhance the reliability of their outputs, we integrate the RAG technique, which grounds the generated comments in domain-specific security knowledge. Additionally, we introduce SecureBLEU, a new evaluation metric designed to assess the effectiveness of review comments in addressing security issues. Experimental results demonstrate that SecureReviewer outperforms state-of-the-art baselines in both security issue detection accuracy and the overall quality and practical utility of generated review comments.