Chain-of-Thought Hijacking
作者: Jianli Zhao, Tingchen Fu, Rylan Schaeffer, Mrinank Sharma, Fazl Barez
分类: cs.AI
发布日期: 2025-10-30 (更新: 2026-02-03)
💡 一句话要点
提出CoT Hijacking攻击,揭示思维链推理中大型语言模型的安全漏洞
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链推理 大型语言模型 安全漏洞 越狱攻击 CoT Hijacking
📋 核心要点
- 现有大型推理模型依赖思维链提升性能,但安全性并未同步提升,存在被攻击利用的风险。
- 提出思维链劫持(CoT Hijacking)攻击,通过良性推理序列弱化模型的安全检查机制。
- 实验表明,CoT Hijacking在多个主流LLM上实现了极高的攻击成功率,揭示了思维链推理的潜在安全隐患。
📝 摘要(中文)
大型推理模型(LRMs)通过扩展推理过程来提高任务性能。虽然先前研究表明这应增强安全性,但我们发现证据表明情况恰恰相反。长的推理序列可被利用来系统性地削弱模型的安全性。我们引入了思维链劫持(Chain-of-Thought Hijacking),这是一种越狱攻击,通过在有害指令前添加良性的谜题推理序列来实现。在HarmBench上,CoT Hijacking在Gemini 2.5 Pro、ChatGPT o4 Mini、Grok 3 Mini和Claude 4 Sonnet上的攻击成功率分别达到99%、94%、100%和94%。为了理解这种机制,我们应用了激活探测、注意力分析和因果干预。我们发现拒绝响应取决于一个低维安全信号,该信号随着推理的增长而被稀释:中间层编码安全检查的强度,而后期层编码拒绝响应的结果。这些发现表明,当与答案提示线索结合使用时,显式的思维链推理会引入系统性的漏洞。我们发布了所有评估材料,以方便复现。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在思维链(Chain-of-Thought, CoT)推理过程中存在的安全漏洞问题。现有方法虽然通过CoT提升了模型性能,但忽略了由此带来的安全风险,即攻击者可以通过精心设计的CoT序列绕过模型的安全检查机制,诱导模型生成有害内容。
核心思路:论文的核心思路是利用良性的、无害的推理过程来“稀释”或“削弱”模型内部的安全信号,从而使得模型更容易接受后续的有害指令。这种攻击方式类似于“温水煮青蛙”,通过逐步引导模型偏离安全状态,最终达到攻击目的。
技术框架:CoT Hijacking攻击主要包含以下几个阶段:1) 良性推理序列生成:生成一段看似无害的推理过程,例如解决数学难题或逻辑谜题。2) 有害指令注入:在良性推理序列之后,注入包含有害内容的指令。3) 模型推理与响应:将包含良性推理序列和有害指令的输入提供给LLM,观察模型的响应。4) 攻击成功率评估:评估模型生成有害内容的概率,以此衡量攻击的有效性。
关键创新:该论文的关键创新在于发现了CoT推理过程中的一个系统性漏洞,即通过延长推理链条,可以有效地削弱模型的安全检查机制。这种攻击方式不同于传统的prompt injection攻击,它不是直接攻击模型的输入,而是通过操纵模型的推理过程来实现攻击目的。
关键设计:论文使用了HarmBench数据集来评估攻击的有效性。同时,论文还采用了激活探测、注意力分析和因果干预等技术手段,深入分析了CoT Hijacking攻击的内在机制。具体来说,激活探测用于识别模型内部与安全相关的神经元;注意力分析用于观察模型在推理过程中对不同输入的关注程度;因果干预用于验证安全信号与拒绝响应之间的因果关系。
🖼️ 关键图片


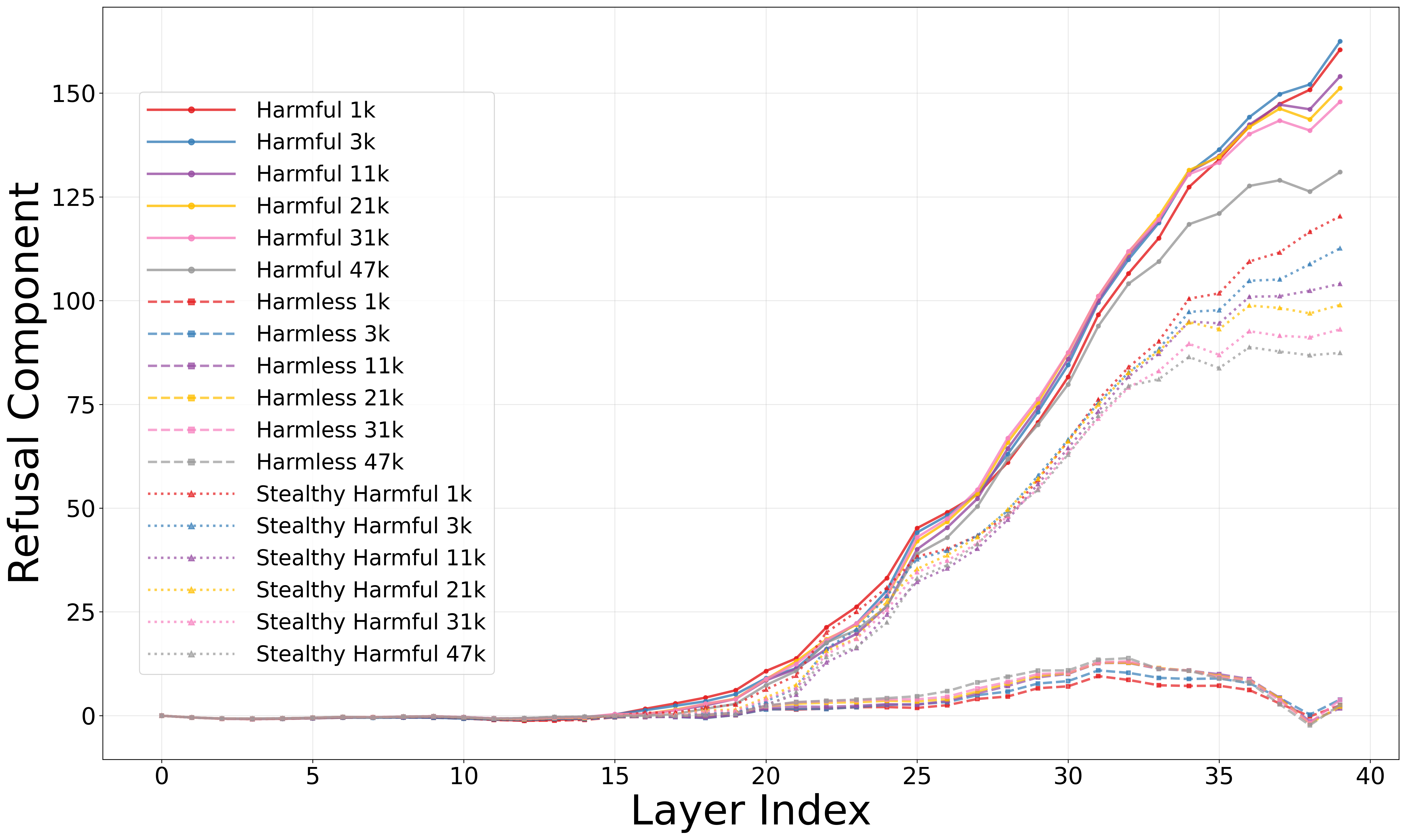
📊 实验亮点
实验结果表明,CoT Hijacking攻击在多个主流LLM上取得了显著的成功,包括Gemini 2.5 Pro (99%)、ChatGPT o4 Mini (94%)、Grok 3 Mini (100%)和Claude 4 Sonnet (94%)。这些结果表明,CoT Hijacking是一种有效的攻击手段,能够绕过现有LLM的安全机制,揭示了思维链推理的潜在安全风险。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性,尤其是在涉及思维链推理的场景下。通过模拟CoT Hijacking攻击,可以发现模型潜在的安全漏洞,并有针对性地进行防御。此外,该研究也为开发更安全的推理模型提供了新的思路,例如,可以设计更鲁棒的安全检查机制,防止安全信号被稀释。
📄 摘要(原文)
Large Reasoning Models (LRMs) improve task performance through extended inference-time reasoning. While prior work suggests this should strengthen safety, we find evidence to the contrary. Long reasoning sequences can be exploited to systematically weaken them. We introduce Chain-of-Thought Hijacking, a jailbreak attack that prepends harmful instructions with extended sequences of benign puzzle reasoning. Across HarmBench, CoT Hijacking achieves attack success rates of 99\%, 94\%, 100\%, and 94\% on Gemini 2.5 Pro, ChatGPT o4 Mini, Grok 3 Mini, and Claude 4 Sonnet. To understand this mechanism, we apply activation probing, attention analysis, and causal interventions. We find that refusal depends on a low-dimensional safety signal that becomes diluted as reasoning grows: mid-layers encode the strength of safety checking, while late layers encode the refusal outcome. These findings demonstrate that explicit chain-of-thought reasoning introduces a systematic vulnerability when combined with answer-prompting cues. We release all evaluation materials to facilitate replication.