GraphCompliance: Aligning Policy and Context Graphs for LLM-Based Regulatory Compliance
作者: Jiseong Chung, Ronny Ko, Wonchul Yoo, Makoto Onizuka, Sungmok Kim, Tae-Wan Kim, Won-Yong Shin
分类: cs.AI, cs.IR
发布日期: 2025-10-30
备注: Under review at The Web Conference 2026 (Semantics & Knowledge track). Code will be released upon acceptance. This arXiv v1 contains no repository links to preserve double-blind review
💡 一句话要点
GraphCompliance:对齐策略图和上下文图,用于LLM的监管合规
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 监管合规 大型语言模型 图神经网络 知识图谱 自然语言处理
📋 核心要点
- 现有方法难以将非结构化运行时上下文与结构化的监管文本对齐,导致监管评估效率低下。
- GraphCompliance框架通过构建策略图和上下文图,并将它们对齐,从而实现监管文本和运行时上下文的语义对齐。
- 实验表明,GraphCompliance在GDPR合规性任务中,相比LLM和RAG基线,Micro-F1指标提升4.1-7.2个百分点。
📝 摘要(中文)
网络规模的合规性带来了实际挑战:每个请求都可能需要监管评估。监管文本(例如,通用数据保护条例,GDPR)是交叉引用的和规范性的,而运行时上下文则以非结构化的自然语言表达。这种背景促使我们将非结构化文本中的语义信息与法规的结构化、规范性要素对齐。为此,我们引入了GraphCompliance框架,该框架将监管文本表示为策略图,将运行时上下文表示为上下文图,并将它们对齐。在这种形式中,策略图编码规范性结构和交叉引用,而上下文图将事件形式化为主语-动作-宾语(SAO)和实体-关系三元组。这种对齐将判断型大型语言模型(LLM)的推理锚定在结构化信息中,并有助于减少监管解释和事件解析的负担,从而能够专注于核心推理步骤。在对300个源自GDPR的真实场景进行的实验中,涵盖五个评估任务,GraphCompliance的micro-F1比仅使用LLM和RAG基线高出4.1-7.2个百分点(pp),减少了欠预测和过度预测,从而提高了召回率并降低了假阳性率。消融研究表明每个图组件都有贡献,表明结构化表示和判断型LLM对于规范性推理是互补的。
🔬 方法详解
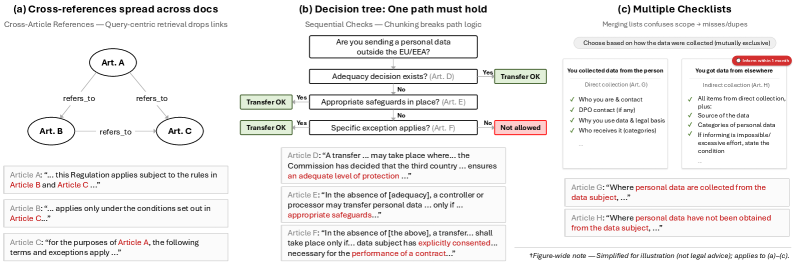
问题定义:论文旨在解决大规模网络环境中,如何高效准确地进行监管合规评估的问题。现有方法,特别是直接使用LLM或基于检索增强生成(RAG)的方法,难以有效处理监管文本的规范性结构和交叉引用,以及运行时上下文的非结构化特性,导致合规评估的准确性和效率较低。
核心思路:论文的核心思路是将监管文本和运行时上下文分别表示为结构化的图,即策略图和上下文图,并通过图对齐的方式,将二者关联起来。这种结构化表示能够更好地捕捉监管文本的规范性语义和上下文事件的关系,从而提升LLM进行合规推理的准确性。
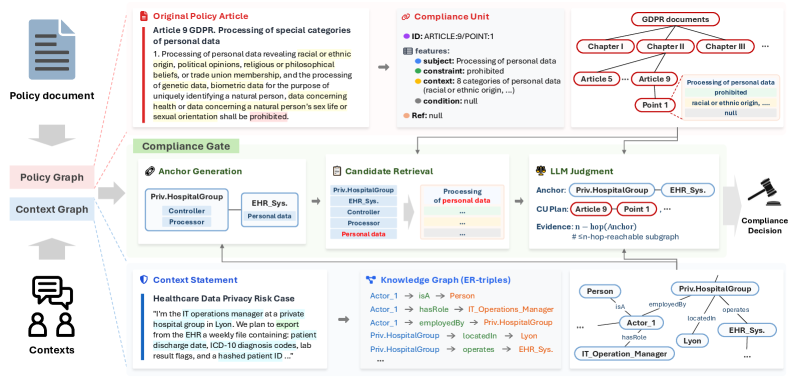
技术框架:GraphCompliance框架包含以下主要模块:1) 策略图构建:将监管文本解析为策略图,节点表示法规条款,边表示条款之间的引用关系。2) 上下文图构建:将运行时上下文解析为主语-动作-宾语(SAO)和实体-关系三元组,构建上下文图。3) 图对齐:将策略图和上下文图进行对齐,建立法规条款和上下文事件之间的关联。4) LLM推理:使用对齐后的图信息,引导LLM进行合规性判断。
关键创新:该论文的关键创新在于提出了基于图结构的监管合规框架,将非结构化的文本信息转化为结构化的图表示,并利用图对齐技术将监管策略和运行时上下文关联起来。这种方法能够有效地利用监管文本的规范性结构和上下文事件的关系,从而提升LLM进行合规推理的准确性和效率。与现有方法相比,GraphCompliance避免了直接对非结构化文本进行推理,而是通过结构化的图表示,降低了LLM的推理难度。
关键设计:策略图的构建依赖于对监管文本的解析,需要准确识别法规条款和条款之间的引用关系。上下文图的构建依赖于对运行时上下文的解析,需要准确提取主语、动作和宾语等信息。图对齐算法的设计需要考虑策略图和上下文图之间的语义相似性,以及法规条款和上下文事件之间的关联性。LLM推理过程需要有效地利用对齐后的图信息,例如,可以使用图神经网络对图节点进行编码,并将编码后的节点表示作为LLM的输入。
🖼️ 关键图片
📊 实验亮点
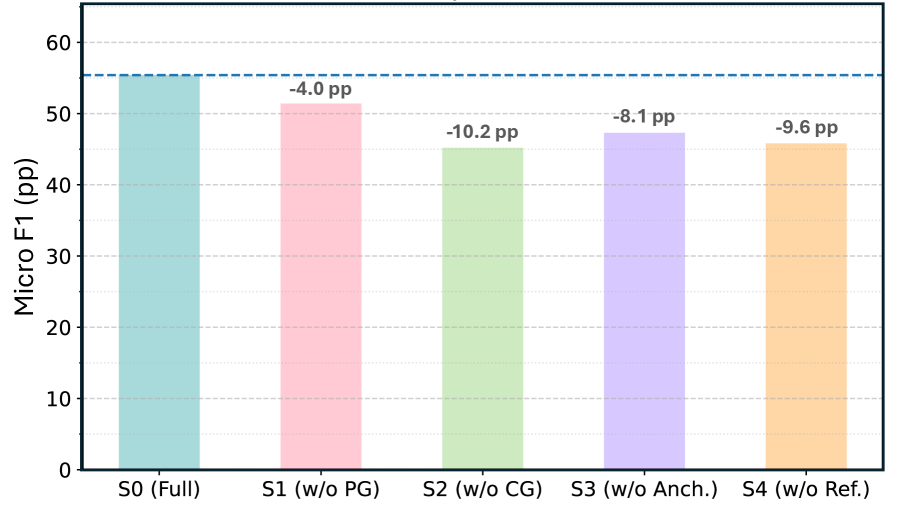
实验结果表明,GraphCompliance在GDPR合规性评估任务中,相比于仅使用LLM和RAG基线,Micro-F1指标提升了4.1-7.2个百分点。同时,GraphCompliance减少了欠预测和过度预测的情况,提高了召回率并降低了假阳性率。消融实验证明了策略图和上下文图的有效性,表明结构化表示和LLM对于规范性推理是互补的。
🎯 应用场景
GraphCompliance可应用于各种需要监管合规的领域,例如数据隐私保护、金融监管、医疗合规等。该框架可以帮助企业自动评估其业务流程和系统是否符合相关法规,降低合规成本,减少违规风险。未来,该研究可以扩展到支持更复杂的监管场景和更灵活的合规策略。
📄 摘要(原文)
Compliance at web scale poses practical challenges: each request may require a regulatory assessment. Regulatory texts (e.g., the General Data Protection Regulation, GDPR) are cross-referential and normative, while runtime contexts are expressed in unstructured natural language. This setting motivates us to align semantic information in unstructured text with the structured, normative elements of regulations. To this end, we introduce GraphCompliance, a framework that represents regulatory texts as a Policy Graph and runtime contexts as a Context Graph, and aligns them. In this formulation, the policy graph encodes normative structure and cross-references, whereas the context graph formalizes events as subject-action-object (SAO) and entity-relation triples. This alignment anchors the reasoning of a judge large language model (LLM) in structured information and helps reduce the burden of regulatory interpretation and event parsing, enabling a focus on the core reasoning step. In experiments on 300 GDPR-derived real-world scenarios spanning five evaluation tasks, GraphCompliance yields 4.1-7.2 percentage points (pp) higher micro-F1 than LLM-only and RAG baselines, with fewer under- and over-predictions, resulting in higher recall and lower false positive rates. Ablation studies indicate contributions from each graph component, suggesting that structured representations and a judge LLM are complementary for normative reasoning.