ToolRM: Towards Agentic Tool-Use Reward Modeling
作者: Renhao Li, Jianhong Tu, Yang Su, Yantao Liu, Fei Huang, Hamid Alinejad-Rokny, Derek F. Wong, Junyang Lin, Min Yang
分类: cs.AI, cs.CL
发布日期: 2025-10-30 (更新: 2026-01-13)
💡 一句话要点
提出ToolRM,用于提升Agent在工具使用场景下的奖励建模能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 工具学习 函数调用 Agentic AI 偏好学习
📋 核心要点
- 现有工具学习领域缺乏专门为函数调用任务设计的奖励模型,限制了Agentic AI的发展。
- 提出ToolRM,利用规则评分和多维采样构建高质量成对偏好数据,训练轻量级奖励模型。
- 实验表明,ToolRM在工具调用任务上显著优于现有LLM和RM,并能有效应用于评论任务。
📝 摘要(中文)
奖励模型(RM)在使大型语言模型(LLM)与人类偏好对齐方面起着关键作用。然而,在工具学习领域,缺乏专门为函数调用任务设计的RM限制了更强大的Agentic AI的发展。我们介绍了ToolRM,一个为通用工具使用场景量身定制的轻量级奖励模型系列。为了构建这些模型,我们提出了一种新颖的pipeline,该pipeline使用基于规则的评分和多维采样来构建高质量的成对偏好数据。这产生了ToolPref-Pairwise-30K,一个多样化、平衡且具有挑战性的偏好数据集,支持生成式和判别式奖励建模。我们还引入了TRBench$_{BFCL}$,一个建立在agent评估套件BFCL之上的基准,用于评估RM在工具调用任务上的性能。经过我们构建的数据训练后,来自Qwen3-4B/8B系列的模型的准确率提高了高达17.94%,大大优于前沿LLM和RM在成对奖励判断方面的表现。除了训练目标之外,生成式ToolRM还可以推广到更广泛的评论任务,包括Best-of-N采样和自我纠正。在ACEBench上的实验突出了其有效性和效率,能够在推理时进行扩展,同时减少超过66%的输出token使用量。它对下游RL训练的支持进一步验证了它的实用性。我们发布数据以促进未来的研究。
🔬 方法详解
问题定义:现有奖励模型在工具学习领域,特别是函数调用任务中表现不足,无法有效对齐人类偏好,阻碍了Agentic AI的发展。现有方法难以构建高质量的工具使用偏好数据集,导致奖励模型训练效果不佳。
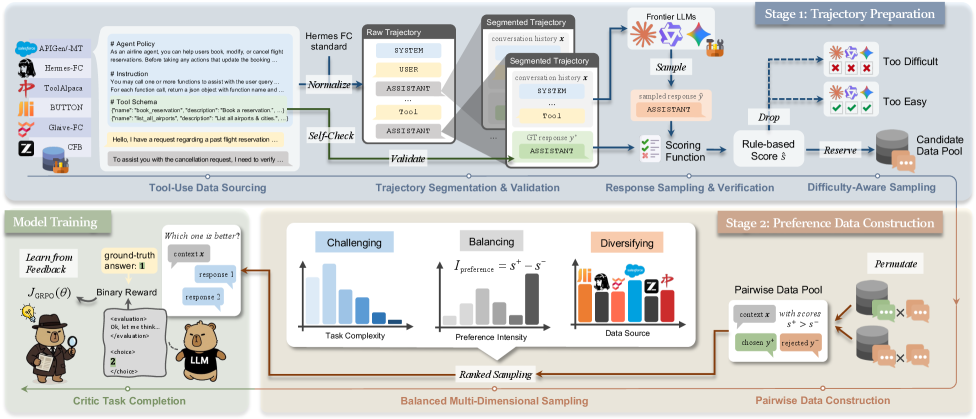
核心思路:ToolRM的核心思路是构建一个专门针对工具使用场景的轻量级奖励模型,并通过新颖的pipeline生成高质量的成对偏好数据进行训练。通过规则评分和多维采样,确保数据集的多样性和平衡性,从而提升奖励模型的性能。
技术框架:ToolRM的整体框架包括数据构建pipeline、奖励模型训练和评估三个主要阶段。数据构建pipeline使用规则评分和多维采样生成ToolPref-Pairwise-30K数据集。奖励模型训练阶段使用Qwen3-4B/8B系列模型,并在ToolPref-Pairwise-30K数据集上进行训练。评估阶段使用TRBench$_{BFCL}$基准评估奖励模型在工具调用任务上的性能。
关键创新:ToolRM的关键创新在于数据构建pipeline,它通过规则评分和多维采样生成高质量的成对偏好数据,解决了现有方法难以构建有效工具使用偏好数据集的问题。此外,ToolRM还展示了生成式奖励模型在更广泛的评论任务中的应用潜力,例如Best-of-N采样和自我纠正。
关键设计:数据构建pipeline的关键设计包括:1) 基于规则的评分函数,用于评估工具使用的质量;2) 多维采样策略,用于确保数据集的多样性和平衡性;3) 成对偏好数据的构建方式,用于训练奖励模型。奖励模型训练的关键设计包括:1) 使用Qwen3-4B/8B系列模型作为基础模型;2) 采用合适的损失函数,例如pairwise ranking loss,来优化奖励模型。
🖼️ 关键图片

📊 实验亮点
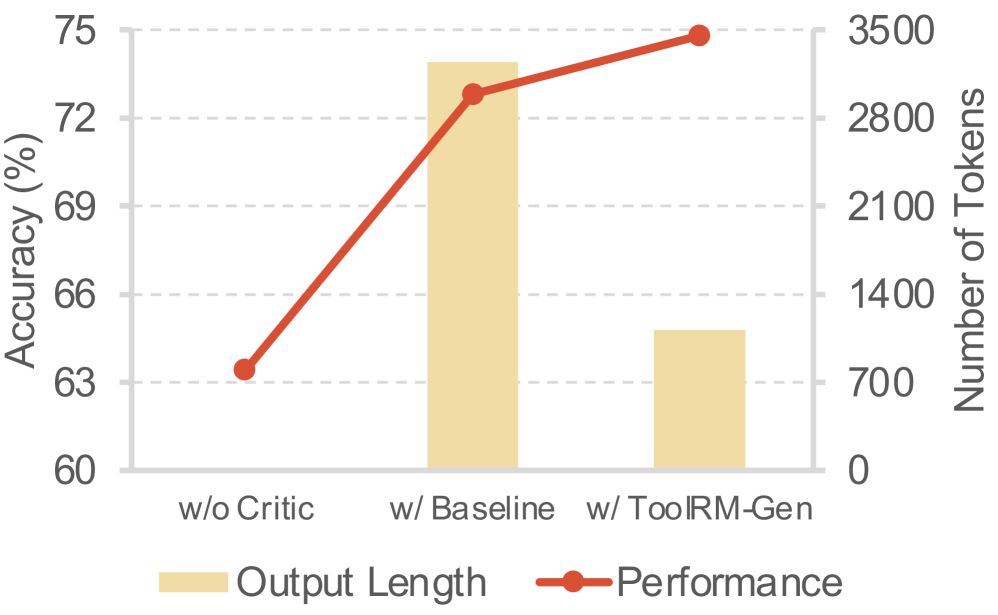
ToolRM在TRBench$_{BFCL}$基准测试中,使用Qwen3-4B/8B系列模型训练后,准确率提高了高达17.94%,显著优于现有LLM和RM。在ACEBench上的实验表明,ToolRM能够在推理时进行扩展,同时减少超过66%的输出token使用量,验证了其有效性和效率。
🎯 应用场景
ToolRM可应用于各种需要Agent进行工具使用的场景,例如智能助手、自动化流程、代码生成等。它可以提升Agent的工具使用能力,使其更好地完成任务,提高效率和准确性。此外,ToolRM还可以用于评估和改进Agent的工具使用策略,促进Agent的持续学习和优化。
📄 摘要(原文)
Reward models (RMs) play a critical role in aligning large language models (LLMs) with human preferences. Yet in the domain of tool learning, the lack of RMs specifically designed for function-calling tasks has limited progress toward more capable agentic AI. We introduce ToolRM, a family of lightweight reward models tailored for general tool-use scenarios. To build these models, we propose a novel pipeline that constructs high-quality pairwise preference data using rule-based scoring and multidimensional sampling. This yields ToolPref-Pairwise-30K, a diverse, balanced, and challenging preference dataset that supports both generative and discriminative reward modeling. We also introduce TRBench$_{BFCL}$, a benchmark built on the agent evaluation suite BFCL to evaluate RMs on tool calling tasks. Trained on our constructed data, models from the Qwen3-4B/8B series achieve up to 17.94% higher accuracy, substantially outperforming frontier LLMs and RMs in pairwise reward judgments. Beyond training objectives, generative ToolRM generalizes to broader critique tasks, including Best-of-N sampling and self-correction. Experiments on ACEBench highlight its effectiveness and efficiency, enabling inference-time scaling while reducing output token usage by over 66%. Its support for downstream RL training further validates its practical utility. We release data to facilitate future research.