Beyond Synthetic Benchmarks: Evaluating LLM Performance on Real-World Class-Level Code Generation
作者: Musfiqur Rahman, SayedHassan Khatoonabadi, Emad Shihab
分类: cs.SE, cs.AI, cs.LG
发布日期: 2025-10-30 (更新: 2025-11-04)
备注: Pre-print submitted for reviwer to TOSEM
💡 一句话要点
提出真实类级别代码生成基准,评估LLM在实际场景下的性能瓶颈与改进策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 真实数据基准 类级别代码 检索增强 错误分析 软件工程
📋 核心要点
- 现有LLM在函数级代码生成表现良好,但在实际类级别代码生成中面临挑战,无法很好地泛化到真实项目。
- 论文提出一个基于真实开源项目的类级别代码生成基准,用于评估LLM在实际场景下的性能。
- 实验表明,LLM在真实类级别任务上的性能远低于合成基准,检索增强能有效提升性能。
📝 摘要(中文)
大型语言模型(LLM)在函数级别的代码生成基准上表现出色,但实际软件开发需要类级别的实现,这涉及到在真实项目上下文中集成多个方法、属性和依赖项。基准性能与实际效用之间的差距引发了关于LLM在生产代码辅助方面的准备情况的关键问题,特别是它们在熟悉和新代码库中泛化的能力。我们引入了一个源自真实开源存储库的基准,包含分为已见和未见分区的类,以评估实际条件下的泛化能力。我们系统地研究了输入规范完整性和检索增强生成如何影响多个最先进LLM的类级别正确性。评估显示存在显著的性能差距:LLM在合成基准上达到84%到89%的正确率,但在真实类任务上仅达到25%到34%,熟悉和新代码库之间的差异很小。全面的文档提供了边际改进(1%到3%),而检索增强通过提供具体的实现模式产生了更大的收益(4%到7%)。错误分析表明AttributeError、TypeError和AssertionError是主要的失败模式,合成和真实场景之间存在不同的模式。这些发现为增强生产代码辅助工具中的上下文建模、文档策略和检索集成提供了可操作的见解。
🔬 方法详解
问题定义:论文旨在解决LLM在真实软件开发场景中类级别代码生成能力不足的问题。现有方法主要在合成数据集上评估LLM的性能,无法反映LLM在处理复杂依赖关系和真实项目上下文时的实际表现。现有方法的痛点在于无法准确评估LLM在实际生产环境中的可用性。
核心思路:论文的核心思路是构建一个基于真实开源项目的类级别代码生成基准,并系统地评估LLM在不同条件下的性能。通过分析LLM在真实场景下的错误类型,为改进LLM的代码生成能力提供指导。论文认为,通过更全面的文档和检索增强,可以提升LLM在真实场景下的代码生成性能。
技术框架:论文的技术框架主要包括以下几个部分:1) 构建真实类级别代码生成基准,该基准包含从开源项目中提取的类,并将其分为已见和未见两部分,用于评估LLM的泛化能力。2) 设计实验,系统地评估LLM在不同输入规范完整性和检索增强条件下的性能。3) 对LLM生成的代码进行评估,并分析错误类型。4) 提出改进LLM代码生成能力的建议。
关键创新:论文最重要的技术创新点在于构建了一个基于真实开源项目的类级别代码生成基准。与现有的合成基准相比,该基准更能够反映LLM在实际软件开发场景中的性能。此外,论文还系统地研究了输入规范完整性和检索增强对LLM性能的影响,并分析了LLM在真实场景下的错误类型。
关键设计:论文的关键设计包括:1) 基准的构建方法,如何从开源项目中提取类,并保证其代表性。2) 实验的设计,如何控制输入规范的完整性和检索增强的程度。3) 评估指标的选择,如何准确评估LLM生成的代码的正确性。4) 错误分析的方法,如何识别和分类LLM生成的代码中的错误。
🖼️ 关键图片
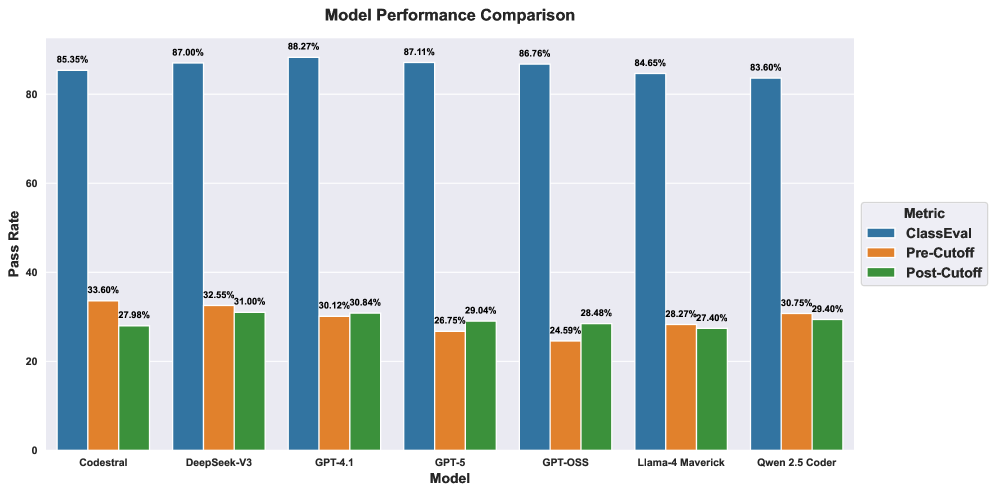


📊 实验亮点
实验结果表明,LLM在合成基准上能达到84%-89%的正确率,但在真实类级别任务上仅为25%-34%。检索增强策略能带来4%-7%的性能提升,而更全面的文档仅带来1%-3%的提升。错误分析显示,AttributeError、TypeError和AssertionError是主要错误类型。
🎯 应用场景
该研究成果可应用于提升代码自动生成工具的性能,帮助开发者更高效地编写代码。通过改进LLM的上下文建模能力和检索集成策略,可以提高LLM在实际项目中的代码生成质量,降低开发成本,加速软件开发流程。未来,该研究可以扩展到更复杂的软件开发任务,例如模块级别的代码生成和系统级别的代码集成。
📄 摘要(原文)
Large language models (LLMs) have demonstrated strong performance on function-level code generation benchmarks, yet real-world software development increasingly demands class-level implementations that integrate multiple methods, attributes, and dependencies within authentic project contexts. This gap between benchmark performance and practical utility raises critical questions about LLMs' readiness for production code assistance, particularly regarding their ability to generalize across familiar and novel codebases. We introduce a benchmark derived from real-world open-source repositories, comprising classes divided into seen and unseen partitions to evaluate generalization under practical conditions. We systematically examine how input specification completeness and retrieval-augmented generation affect class-level correctness across multiple state-of-the-art LLMs. Our evaluation reveals a substantial performance gap: while LLMs achieve 84 to 89% correctness on synthetic benchmarks, they attain only 25 to 34% on real-world class tasks, with minimal distinction between familiar and novel codebases. Comprehensive documentation provides marginal improvements (1 to 3%), whereas retrieval augmentation yields greater gains (4 to 7%) by supplying concrete implementation patterns. Error analysis identifies AttributeError, TypeError, and AssertionError as dominant failure modes, with distinct patterns between synthetic and real-world scenarios. These findings provide actionable insights for enhancing context modelling, documentation strategies, and retrieval integration in production code assistance tools.