Approximating Human Preferences Using a Multi-Judge Learned System
作者: Eitán Sprejer, Fernando Avalos, Augusto Bernardi, Jose Pedro Brito de Azevedo Faustino, Jacob Haimes, Narmeen Fatimah Oozeer
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-10-29
💡 一句话要点
提出一种基于多评判器学习系统的人类偏好近似方法,用于校准LLM评判。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人类偏好建模 LLM评判器 规则条件评判 多评判器聚合 广义加性模型 多层感知器 角色偏好 强化学习
📋 核心要点
- 现有LLM评判器存在校准困难、规则敏感、偏差和不稳定性等问题,难以准确反映人类偏好。
- 提出一种框架,通过学习聚合多个规则条件评判器的输出来建模多样化的、基于角色的偏好。
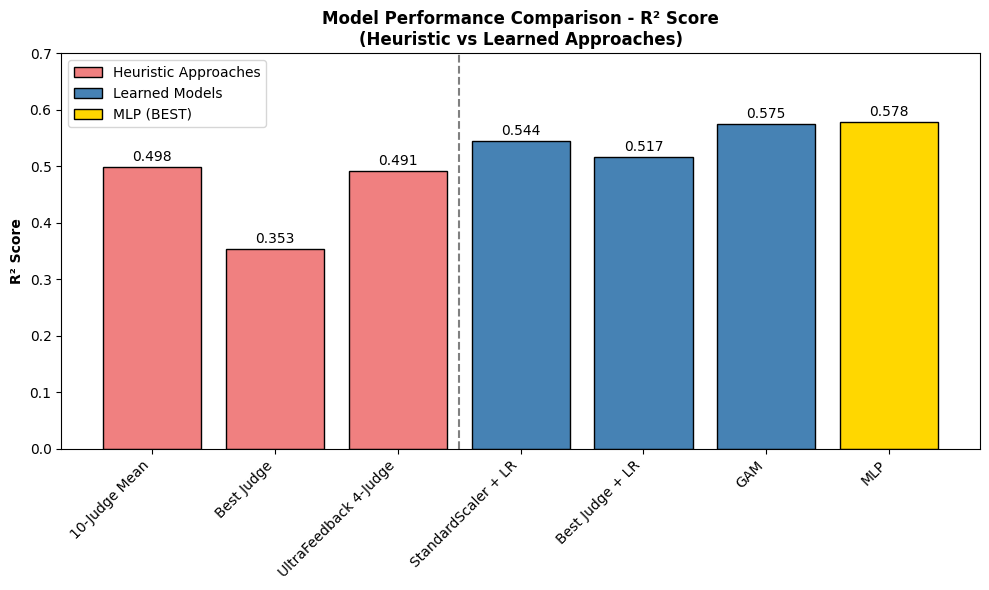
- 通过案例研究验证了该方法对人类和LLM评判器偏差的鲁棒性,并实现了两种聚合器:GAM和MLP。
📝 摘要(中文)
对齐基于LLM的评判器与人类偏好是一个重要的挑战,因为它们难以校准,并且经常受到规则敏感性、偏差和不稳定性的影响。克服这一挑战将推进关键应用,例如为基于人类反馈的强化学习(RLHF)创建可靠的奖励模型,以及构建有效的路由系统,为给定的用户查询选择最合适的模型。在这项工作中,我们提出了一个框架,通过学习聚合来自多个规则条件评判器的输出来建模多样化的、基于角色的偏好。我们研究了这种方法相对于朴素基线的性能,并通过对人类和LLM评判器偏差的案例研究来评估其鲁棒性。我们的主要贡献包括一种大规模合成偏好标签的基于角色的方法,以及我们聚合器的两种不同实现:广义加性模型(GAM)和多层感知器(MLP)。
🔬 方法详解
问题定义:论文旨在解决LLM评判器难以准确对齐人类偏好的问题。现有的LLM评判器存在校准困难、对规则过于敏感、存在偏差以及结果不稳定等痛点,导致其在RLHF奖励模型构建和模型路由系统中的应用受限。
核心思路:论文的核心思路是通过学习聚合多个基于不同规则条件(rubric-conditioned)的评判器的输出来模拟人类偏好。这种方法旨在捕捉人类偏好的多样性和个性化特征,从而提高评判结果的准确性和鲁棒性。通过引入“角色”(persona)的概念,可以模拟不同人群的偏好。
技术框架:该框架包含以下几个主要步骤:1) 定义不同的角色(persona),代表不同的人类偏好;2) 为每个角色生成偏好标签,用于训练聚合器;3) 使用多个规则条件评判器对输入进行评估,每个评判器关注不同的评估维度;4) 使用广义加性模型(GAM)或多层感知器(MLP)作为聚合器,学习将多个评判器的输出组合成最终的偏好预测。
关键创新:该论文的关键创新在于提出了一种基于角色的方法来合成偏好标签,从而能够大规模地训练聚合器。此外,使用多个规则条件评判器并学习如何聚合它们的输出,可以更好地捕捉人类偏好的复杂性和多样性。与直接训练单个LLM评判器相比,该方法更具模块化和可解释性。
关键设计:论文中使用了两种不同的聚合器:GAM和MLP。GAM是一种可解释性较强的模型,可以分析每个评判器对最终预测的贡献。MLP则是一种更灵活的模型,可以学习更复杂的非线性关系。论文中可能还涉及损失函数的设计,例如使用交叉熵损失来训练聚合器预测正确的偏好标签。具体的网络结构和参数设置在论文中应该有详细描述。
🖼️ 关键图片


📊 实验亮点
论文通过案例研究验证了该方法的有效性,表明其能够有效地聚合多个评判器的输出,并对人类和LLM评判器的偏差具有一定的鲁棒性。虽然摘要中没有给出具体的性能数据,但可以推断实验结果表明,所提出的方法优于朴素基线,并且在一定程度上缓解了LLM评判器的偏差问题。
🎯 应用场景
该研究成果可应用于多个领域。在RLHF中,可以利用该方法构建更准确的奖励模型,从而提升强化学习算法的性能。在模型路由系统中,可以根据用户画像选择最合适的LLM模型,提高用户体验。此外,该方法还可以用于评估LLM生成内容的质量,并发现和纠正LLM的偏差。
📄 摘要(原文)
Aligning LLM-based judges with human preferences is a significant challenge, as they are difficult to calibrate and often suffer from rubric sensitivity, bias, and instability. Overcoming this challenge advances key applications, such as creating reliable reward models for Reinforcement Learning from Human Feedback (RLHF) and building effective routing systems that select the best-suited model for a given user query. In this work, we propose a framework for modeling diverse, persona-based preferences by learning to aggregate outputs from multiple rubric-conditioned judges. We investigate the performance of this approach against naive baselines and assess its robustness through case studies on both human and LLM-judges biases. Our primary contributions include a persona-based method for synthesizing preference labels at scale and two distinct implementations of our aggregator: Generalized Additive Model (GAM) and a Multi-Layer Perceptron (MLP).