Aligning Large Language Models with Procedural Rules: An Autoregressive State-Tracking Prompting for In-Game Trading
作者: Minkyung Kim, Junsik Kim, Woongcheol Yang, Sangdon Park, Sohee Bae
分类: cs.AI
发布日期: 2025-10-28
备注: 8 pages main content, 18 pages supplementary material, 4 figures
💡 一句话要点
提出自回归状态追踪提示ASTP,解决LLM在游戏交易中规则遵循问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 游戏交易 规则遵循 自回归状态追踪 提示工程
📋 核心要点
- 现有LLM在游戏交易中难以遵循程序规则,导致玩家信任度降低,这是核心问题。
- ASTP通过强制LLM显式追踪和报告状态,确保交易流程的正确执行。
- 实验表明,ASTP在保证高状态合规性和计算精度的同时,显著降低了响应时间。
📝 摘要(中文)
大型语言模型(LLM)能够实现动态的游戏交互,但在规则驱动的交易系统中,它们无法遵循必要的程序流程,从而降低玩家的信任度。本研究旨在解决LLM的创造性灵活性与游戏内交易(浏览-报价-审查-确认)的程序性需求之间的核心矛盾。为此,我们引入了自回归状态追踪提示(ASTP),这是一种以策略性编排的提示为中心的方法,该提示强制LLM明确并验证其状态跟踪过程。ASTP不依赖于隐式的上下文理解,而是要求LLM识别并报告前一轮中预定义的状态标签。为了确保交易的完整性,我们使用特定于状态的占位符后处理方法来补充,以实现准确的价格计算。对300个交易对话的评估表明,状态合规性>99%,计算精度为99.3%。值得注意的是,在较小的模型(Gemini-2.5-Flash)上使用带有占位符后处理的ASTP,其性能与较大的模型(Gemini-2.5-Pro)相匹配,同时将响应时间从21.2秒减少到2.4秒,为满足商业游戏的实时需求和资源约束奠定了实践基础。
🔬 方法详解
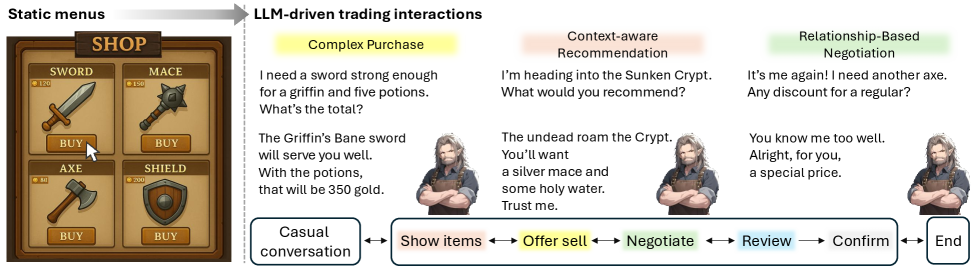
问题定义:论文旨在解决大型语言模型(LLM)在游戏内交易环境中,无法有效遵循预定义的程序规则(如浏览-报价-审查-确认流程)的问题。现有方法依赖于LLM的隐式上下文理解,容易出错,导致交易流程中断或错误,最终损害玩家信任。
核心思路:论文的核心思路是让LLM显式地追踪和报告其当前状态,而不是依赖于隐式的上下文理解。通过策略性设计的提示(Prompt),强制LLM在每一步操作后明确指出其所处的状态,从而使状态转换过程可验证和可控。这种显式状态追踪机制能够显著提高LLM遵循规则的可靠性。
技术框架:整体框架包含以下几个主要步骤:1) 状态定义:预先定义交易流程中的所有可能状态(例如,浏览商品、提出报价、审查报价、确认交易等)。2) 提示工程:设计包含状态追踪指令的提示,要求LLM在每个回合中识别并报告其当前状态。3) LLM推理:LLM接收提示并生成响应,其中包括交易操作和状态报告。4) 状态验证:验证LLM报告的状态是否与交易流程的预期状态一致。5) 占位符后处理:针对特定状态,使用预定义的占位符进行价格计算等操作,确保交易的准确性。
关键创新:最重要的技术创新点是自回归状态追踪提示(ASTP)。与传统的隐式上下文理解方法不同,ASTP强制LLM显式地追踪和报告状态,从而提高了交易流程的可控性和可靠性。此外,结合状态特定的占位符后处理方法,进一步提高了交易的准确性。
关键设计:ASTP的关键设计在于提示工程。提示需要清晰地指示LLM识别和报告状态,并提供足够的信息以支持其决策。占位符后处理的关键在于为每个状态定义合适的占位符,以便进行准确的价格计算和其他必要的操作。论文中没有明确提及损失函数或网络结构等细节,这部分可能依赖于所使用的LLM本身。
🖼️ 关键图片

📊 实验亮点
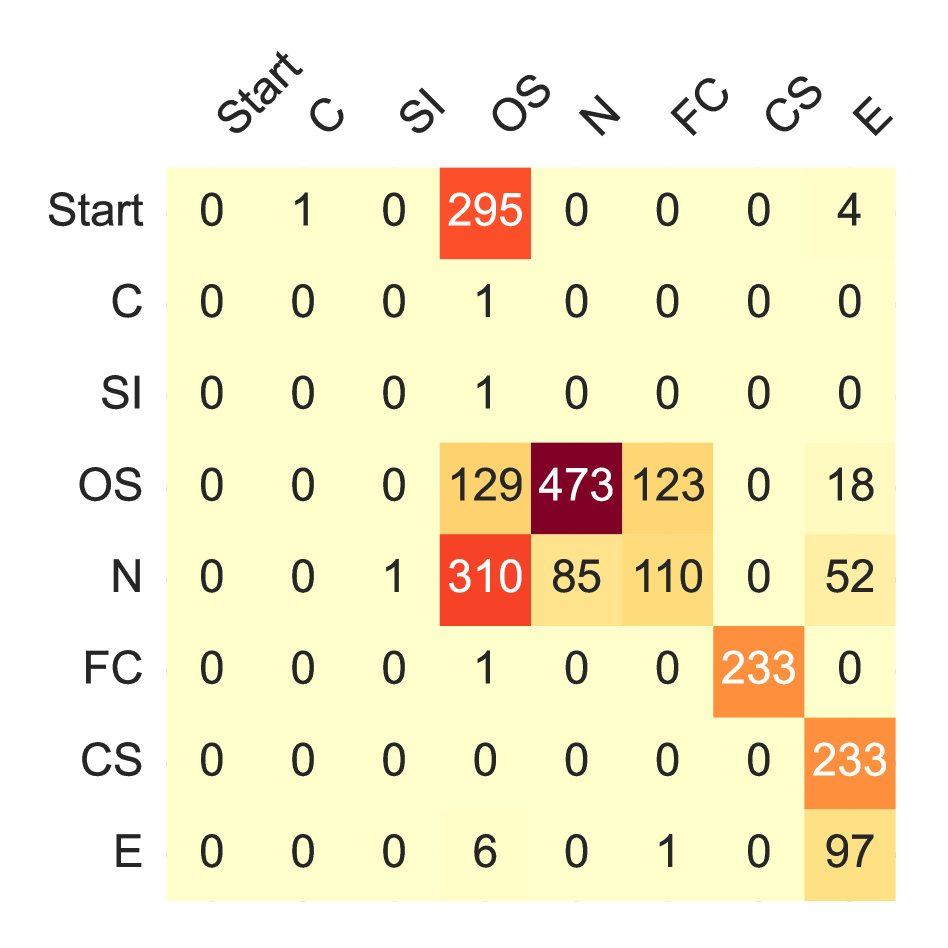
实验结果表明,ASTP能够显著提高LLM在游戏交易中的规则遵循能力。在300个交易对话的评估中,状态合规性超过99%,计算精度达到99.3%。更重要的是,在较小的模型(Gemini-2.5-Flash)上使用ASTP,其性能与较大的模型(Gemini-2.5-Pro)相匹配,同时将响应时间从21.2秒减少到2.4秒,这对于实时性要求高的应用场景具有重要意义。
🎯 应用场景
该研究成果可广泛应用于各类需要规则约束的对话系统中,例如游戏内的交易系统、电商平台的客服机器人、金融领域的智能助手等。通过确保LLM遵循预定义的流程和规则,可以提高系统的可靠性、安全性,并提升用户体验。未来,该方法可以扩展到更复杂的任务中,例如涉及多方交互和复杂规则的场景。
📄 摘要(原文)
Large Language Models (LLMs) enable dynamic game interactions but fail to follow essential procedural flows in rule-governed trading systems, eroding player trust. This work resolves the core tension between the creative flexibility of LLMs and the procedural demands of in-game trading (browse-offer-review-confirm). To this end, Autoregressive State-Tracking Prompting (ASTP) is introduced, a methodology centered on a strategically orchestrated prompt that compels an LLM to make its state-tracking process explicit and verifiable. Instead of relying on implicit contextual understanding, ASTP tasks the LLM with identifying and reporting a predefined state label from the previous turn. To ensure transactional integrity, this is complemented by a state-specific placeholder post-processing method for accurate price calculations. Evaluation across 300 trading dialogues demonstrates >99% state compliance and 99.3% calculation precision. Notably, ASTP with placeholder post-processing on smaller models (Gemini-2.5-Flash) matches larger models' (Gemini-2.5-Pro) performance while reducing response time from 21.2s to 2.4s, establishing a practical foundation that satisfies both real-time requirements and resource constraints of commercial games.