BLM$_1$: A Boundless Large Model for Cross-Space, Cross-Task, and Cross-Embodiment Learning
作者: Wentao Tan, Bowen Wang, Heng Zhi, Chenyu Liu, Zhe Li, Jian Liu, Zengrong Lin, Yukun Dai, Yipeng Chen, Wenjie Yang, Enci Xie, Hao Xue, Baixu Ji, Chen Xu, Zhibin Wang, Tianshi Wang, Lei Zhu, Heng Tao Shen
分类: cs.AI, cs.MM, cs.RO
发布日期: 2025-10-28
💡 一句话要点
提出BLM$_1$以解决跨空间、跨任务和跨体现学习问题
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大型语言模型 跨空间学习 跨任务学习 跨体现泛化 具身知识 智能代理 机器人技术
📋 核心要点
- 现有多模态大型语言模型在数字与物理空间之间的泛化能力不足,导致应用受限。
- BLM$_1$通过两阶段训练,将具身知识注入多模态模型,支持跨空间和跨任务的学习。
- 实验表明,BLM$_1$在数字和物理任务上均显著优于现有模型,提升幅度分别为6%和3%。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在视觉-语言推理方面取得了进展,并逐渐应用于具身代理。然而,现有模型在数字-物理空间和体现之间的泛化能力较差,且具身大型语言模型(ELLMs)主要局限于数字空间,缺乏对物理世界的有效泛化。为此,本文提出了无界大型模型(BLM$_1$),该模型通过两阶段训练范式,整合了跨空间转移、跨任务学习和跨体现泛化的能力,旨在实现数字与物理空间的无缝操作。实验结果表明,BLM$_1$在数字任务和物理任务上分别提升了约6%和3%的性能,超越了多种现有模型。
🔬 方法详解
问题定义:本文旨在解决现有多模态大型语言模型在数字-物理空间和不同体现之间的泛化能力不足的问题。现有模型在具身推理和高层次动作生成方面存在局限,导致其在实际应用中表现不佳。
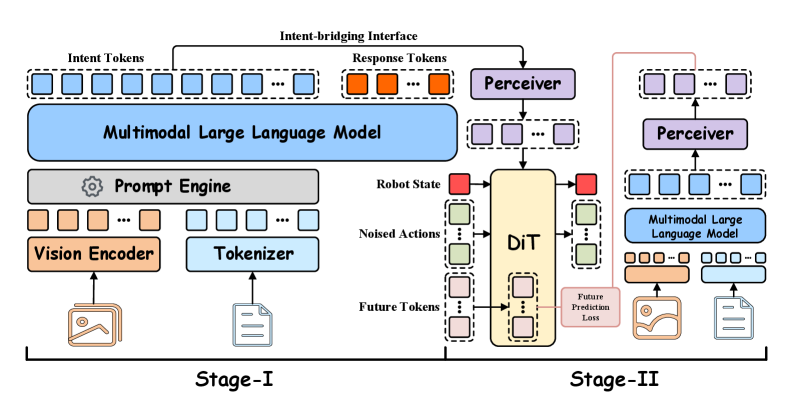
核心思路:BLM$_1$的核心思路是通过两阶段训练范式,首先将具身知识注入多模态模型,然后通过意图桥接接口提取高层语义以指导控制,从而实现跨空间、跨任务和跨体现的学习。
技术框架:BLM$_1$的整体架构包括两个主要阶段:第一阶段通过策划的数字语料库将具身知识注入多模态大型语言模型,同时保持语言能力;第二阶段则训练一个策略模块,通过意图桥接接口提取高层语义,指导控制,而不对多模态模型的主干进行微调。
关键创新:BLM$_1$的主要创新在于其无缝整合了跨空间转移、跨任务学习和跨体现泛化的能力,填补了现有模型在这些方面的空白。
关键设计:在设计上,BLM$_1$采用了自收集的跨体现演示套件,涵盖四种机器人体现和六个逐步挑战的任务,确保了模型的广泛适应性和有效性。
🖼️ 关键图片

📊 实验亮点
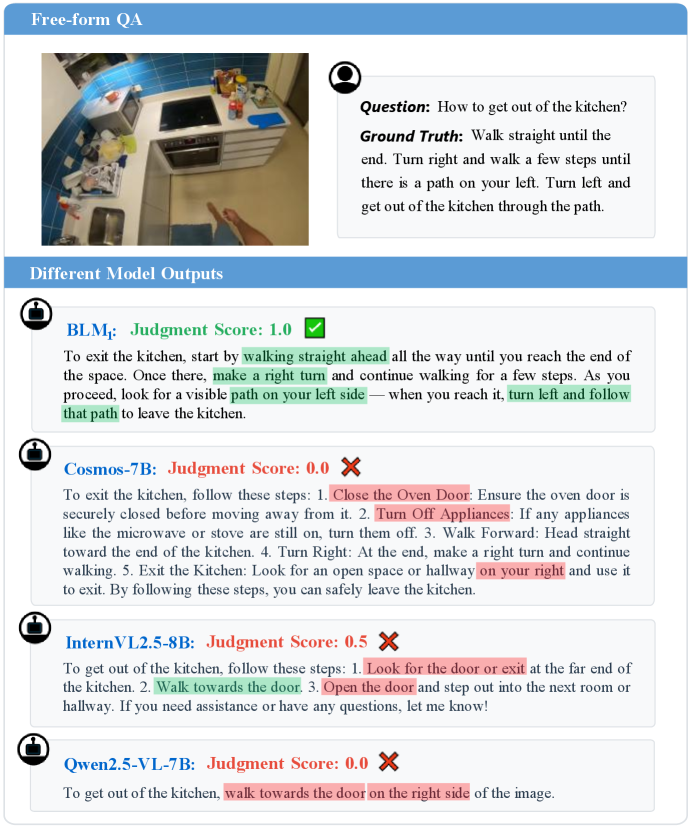
在实验中,BLM$_1$在数字任务上提升了约6%的性能,在物理任务上提升了约3%。该模型超越了四种模型家族,包括多模态大型语言模型(MLLMs)、具身大型语言模型(ELLMs)、视觉-语言-动作模型(VLAs)和生成多模态语言模型(GMLMs),展示了其优越的泛化能力。
🎯 应用场景
BLM$_1$的研究成果在多个领域具有潜在应用价值,包括智能机器人、自动驾驶、虚拟现实和增强现实等。通过提升模型在不同空间和任务之间的泛化能力,BLM$_1$能够更好地支持复杂的交互和决策过程,推动智能代理的实际应用。
📄 摘要(原文)
Multimodal large language models (MLLMs) have advanced vision-language reasoning and are increasingly deployed in embodied agents. However, significant limitations remain: MLLMs generalize poorly across digital-physical spaces and embodiments; vision-language-action models (VLAs) produce low-level actions yet lack robust high-level embodied reasoning; and most embodied large language models (ELLMs) are constrained to digital-space with poor generalization to the physical world. Thus, unified models that operate seamlessly across digital and physical spaces while generalizing across embodiments and tasks remain absent. We introduce the \textbf{Boundless Large Model (BLM$_1$)}, a multimodal spatial foundation model that preserves instruction following and reasoning, incorporates embodied knowledge, and supports robust cross-embodiment control. BLM$_1$ integrates three key capabilities -- \textit{cross-space transfer, cross-task learning, and cross-embodiment generalization} -- via a two-stage training paradigm. Stage I injects embodied knowledge into the MLLM through curated digital corpora while maintaining language competence. Stage II trains a policy module through an intent-bridging interface that extracts high-level semantics from the MLLM to guide control, without fine-tuning the MLLM backbone. This process is supported by a self-collected cross-embodiment demonstration suite spanning four robot embodiments and six progressively challenging tasks. Evaluations across digital and physical benchmarks show that a single BLM$_1$ instance outperforms four model families -- MLLMs, ELLMs, VLAs, and GMLMs -- achieving $\sim!\textbf{6%}$ gains in digital tasks and $\sim!\textbf{3%}$ in physical tasks.