Model-Guided Dual-Role Alignment for High-Fidelity Open-Domain Video-to-Audio Generation
作者: Kang Zhang, Trung X. Pham, Suyeon Lee, Axi Niu, Arda Senocak, Joon Son Chung
分类: cs.SD, cs.AI, cs.MM, eess.AS
发布日期: 2025-10-28
备注: accepted by NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
MGAudio:提出模型引导的双重角色对齐方法,用于高保真开放域视频到音频生成。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 视频到音频生成 跨模态学习 生成模型 Transformer模型 流模型 模型引导 双重角色对齐
📋 核心要点
- 现有视频到音频生成方法依赖于分类器引导或无分类器引导,限制了生成模型自主学习跨模态关系的能力。
- MGAudio通过模型引导的双重角色对齐机制,使生成模型能够通过专门设计的训练目标自主学习视频条件下的音频生成。
- MGAudio在VGGSound和UnAV-100等基准测试中取得了显著的性能提升,证明了其有效性和泛化能力。
📝 摘要(中文)
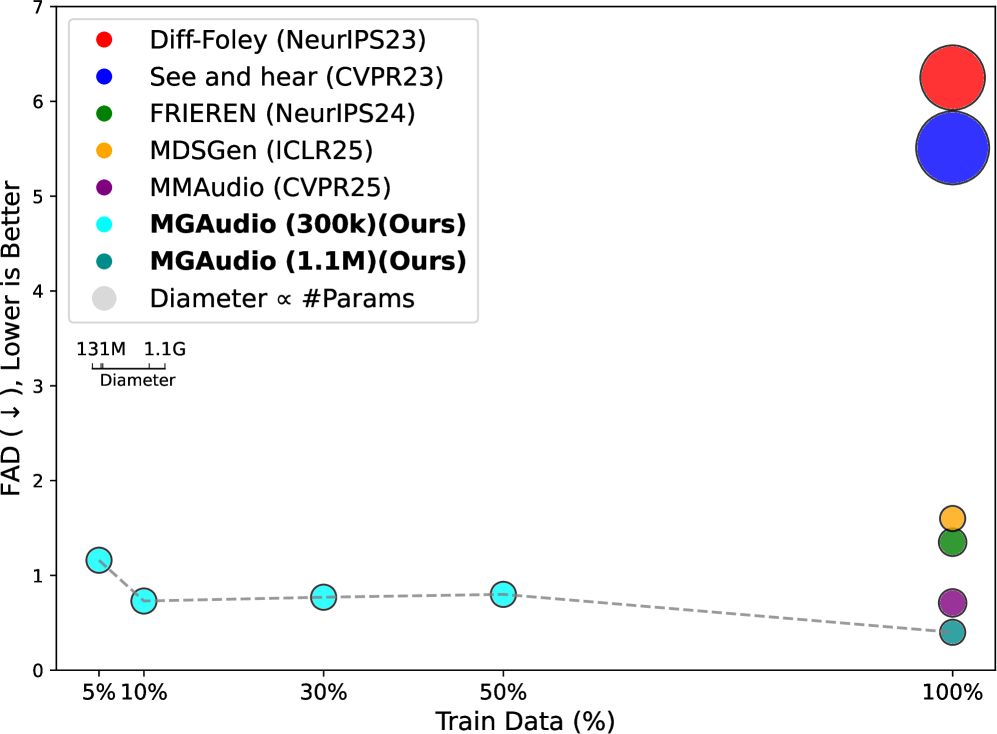
本文提出了一种名为MGAudio的新型基于流的开放域视频到音频生成框架,该框架引入了模型引导的双重角色对齐作为核心设计原则。与依赖于基于分类器的或无分类器引导的先前方法不同,MGAudio使生成模型能够通过专为视频条件音频生成设计的训练目标来引导自身。该框架集成了三个主要组件:(1)可扩展的基于流的Transformer模型,(2)双重角色对齐机制,其中视听编码器既充当条件模块,又充当特征对齐器以提高生成质量,以及(3)模型引导的目标,可增强跨模态一致性和音频真实感。MGAudio在VGGSound上实现了最先进的性能,将FAD降低至0.40,大大超过了最佳的无分类器引导基线,并且在FD、IS和对齐指标上始终优于现有方法。它还可以很好地推广到具有挑战性的UnAV-100基准。这些结果表明,模型引导的双重角色对齐是条件视频到音频生成的一种强大且可扩展的范例。代码可在https://github.com/pantheon5100/mgaudio获得。
🔬 方法详解
问题定义:论文旨在解决开放域视频到音频生成问题,即根据给定的视频内容生成与之对应的音频。现有方法主要依赖于分类器引导或无分类器引导,这些方法的缺点在于需要额外的分类器或复杂的超参数调整,并且可能无法充分利用视频信息来指导音频生成,导致生成的音频与视频内容缺乏一致性和真实感。
核心思路:论文的核心思路是提出一种模型引导的双重角色对齐机制。该机制允许生成模型通过自身学习到的知识来指导音频生成过程,而无需依赖外部分类器。双重角色指的是视听编码器既作为条件模块提供视频信息,又作为特征对齐器,确保生成的音频特征与视频特征对齐。
技术框架:MGAudio框架包含三个主要组成部分:(1) 一个可扩展的基于流的Transformer模型,用于生成音频;(2) 一个双重角色对齐机制,利用视听编码器进行条件输入和特征对齐;(3) 一个模型引导的目标函数,用于增强跨模态一致性和音频真实感。整体流程是,首先使用视听编码器提取视频特征,然后将这些特征作为条件输入到基于流的Transformer模型中,生成音频。同时,视听编码器也用于对齐生成的音频特征和视频特征,确保两者的一致性。
关键创新:MGAudio的关键创新在于模型引导的双重角色对齐机制。与传统的分类器引导或无分类器引导方法不同,MGAudio允许生成模型自主学习跨模态关系,从而生成更真实、更符合视频内容的音频。这种自引导的方式避免了对外部分类器的依赖,简化了训练过程,并提高了生成质量。
关键设计:在技术细节上,MGAudio采用了基于流的Transformer模型作为生成器,这种模型具有强大的生成能力和可逆性。视听编码器可能采用预训练的视觉和音频模型,例如VGGish或ResNet。模型引导的目标函数可能包含多种损失项,例如对抗损失、重构损失和跨模态对齐损失。具体的参数设置和损失函数权重需要根据实验结果进行调整。
🖼️ 关键图片


📊 实验亮点
MGAudio在VGGSound数据集上取得了显著的性能提升,将FAD指标降低至0.40,大幅超越了现有的无分类器引导方法。此外,在FD、IS和对齐指标上,MGAudio也始终优于其他方法。在更具挑战性的UnAV-100数据集上,MGAudio也表现出良好的泛化能力,证明了其在复杂场景下的有效性。
🎯 应用场景
MGAudio具有广泛的应用前景,包括电影制作、游戏开发、虚拟现实、视频编辑和内容创作等领域。它可以用于自动生成视频的背景音乐、音效和对话,提高内容制作效率和质量。此外,该技术还可以应用于辅助听觉障碍人士理解视频内容,提升他们的生活质量。未来,MGAudio有望成为多媒体内容生成的重要工具。
📄 摘要(原文)
We present MGAudio, a novel flow-based framework for open-domain video-to-audio generation, which introduces model-guided dual-role alignment as a central design principle. Unlike prior approaches that rely on classifier-based or classifier-free guidance, MGAudio enables the generative model to guide itself through a dedicated training objective designed for video-conditioned audio generation. The framework integrates three main components: (1) a scalable flow-based Transformer model, (2) a dual-role alignment mechanism where the audio-visual encoder serves both as a conditioning module and as a feature aligner to improve generation quality, and (3) a model-guided objective that enhances cross-modal coherence and audio realism. MGAudio achieves state-of-the-art performance on VGGSound, reducing FAD to 0.40, substantially surpassing the best classifier-free guidance baselines, and consistently outperforms existing methods across FD, IS, and alignment metrics. It also generalizes well to the challenging UnAV-100 benchmark. These results highlight model-guided dual-role alignment as a powerful and scalable paradigm for conditional video-to-audio generation. Code is available at: https://github.com/pantheon5100/mgaudio