Lifecycle-Aware code generation: Leveraging Software Engineering Phases in LLMs
作者: Xing Xing, Wei Wang, Lipeng Ma, Weidong Yang, Junjie Zheng
分类: cs.SE, cs.AI
发布日期: 2025-10-28
💡 一句话要点
提出生命周期感知的代码生成框架,提升LLM在软件工程任务中的代码正确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 软件工程 生命周期 状态机建模
📋 核心要点
- 现有代码生成方法通常依赖于从问题描述到代码的直接翻译,忽略了结构化的软件工程实践。
- 该论文提出了一种生命周期感知的框架,将需求分析、状态机建模和伪代码等中间产物融入LLM的训练和推理中。
- 实验表明,该框架显著提高了代码的正确性,并且在数据量较少的情况下依然具有鲁棒性,开源LLM性能甚至超越了预训练模型。
📝 摘要(中文)
本文提出了一种生命周期感知的代码生成框架,该框架将软件工程的各个阶段(如需求分析、状态机建模和伪代码)系统地融入到大型语言模型(LLM)的训练和推理过程中。这种设计使代码生成与标准的软件开发阶段对齐,并实现更结构化的推理。实验表明,生命周期级别的微调使代码正确性比微调前提高了75%。多步推理始终优于单步生成,证明了中间脚手架的有效性。值得注意的是,在我们的框架下微调的开源LLM,可以匹配甚至略微优于在代码上预训练的模型。当应用于DeepSeek-Coder-1.3B时,我们的框架相对于ChatGPT-3.5、ChatGPT-4o-mini、DeepSeek-R1和LLaMA-8B分别产生了34.3%、20.0%、11.2%和22.3%的CodeBLEU相对改进。我们的pipeline在减少高达80%的训练数据的情况下仍然具有鲁棒性。消融研究进一步表明,每个中间工件都对最终代码质量有不同的贡献,其中状态机建模产生的影响最大。
🔬 方法详解
问题定义:现有的大型语言模型在代码生成方面取得了显著进展,但大多数方法采用单步翻译的方式,直接将问题描述转换为代码,忽略了软件工程中结构化的开发流程。这种方式缺乏对问题更深层次的理解和分解,容易导致生成的代码质量不高,难以满足实际需求。现有方法的痛点在于缺乏对软件生命周期各阶段的有效利用,导致代码生成过程不够系统和规范。
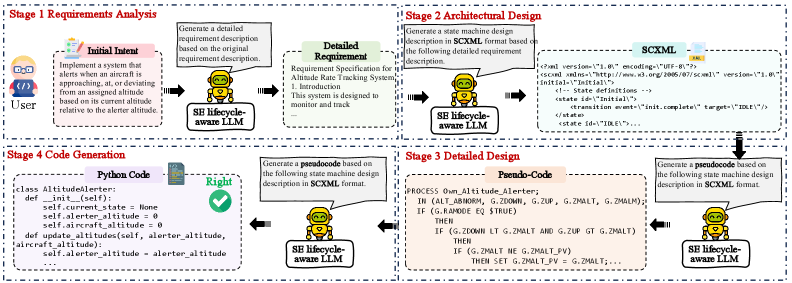
核心思路:本文的核心思路是将软件工程的生命周期阶段融入到代码生成过程中。通过引入需求分析、状态机建模和伪代码等中间产物,将复杂的代码生成任务分解为多个更易于管理的子任务。这种分解能够使模型更好地理解问题的本质,并逐步构建出高质量的代码。核心在于模仿人类软件开发的过程,利用中间产物作为“脚手架”,引导模型进行更结构化的推理。
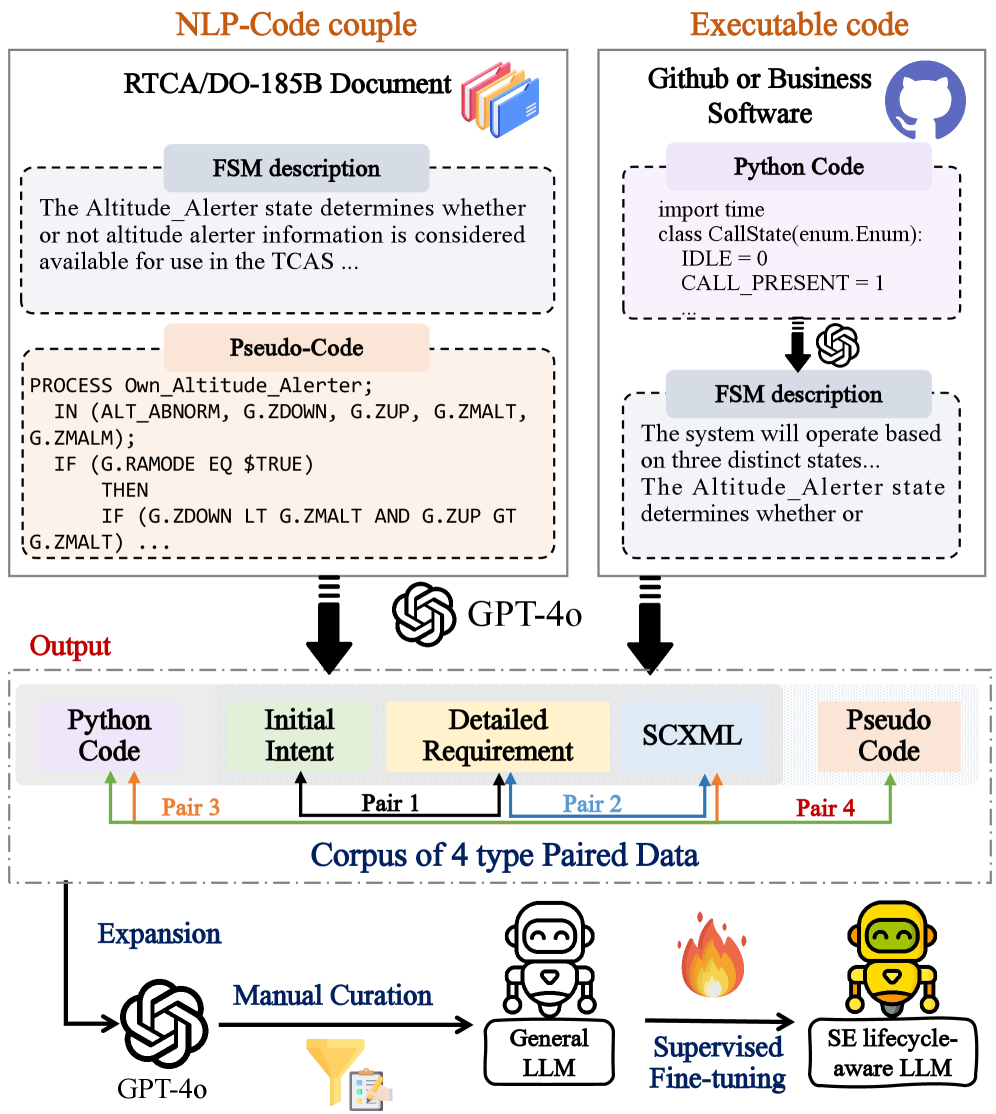
技术框架:该框架包含训练和推理两个阶段。在训练阶段,使用包含问题描述、需求分析、状态机模型、伪代码和最终代码的数据集对LLM进行微调。在推理阶段,首先根据问题描述生成需求分析文档,然后基于需求分析构建状态机模型,接着生成伪代码,最后将伪代码转换为最终代码。整个流程是一个多步骤的迭代过程,每个步骤都依赖于前一个步骤的输出。
关键创新:该论文最重要的技术创新点在于将软件工程的生命周期概念引入到代码生成任务中。通过显式地建模和利用中间产物,使得代码生成过程更加结构化和可控。与传统的单步生成方法相比,该方法能够更好地捕捉问题的复杂性,并生成更准确、更可靠的代码。此外,该框架还能够提高模型的鲁棒性,使其在数据量较少的情况下也能取得良好的性能。
关键设计:在训练阶段,使用了生命周期各个阶段的数据对LLM进行微调,目标是让模型学习如何从一个阶段过渡到下一个阶段。在推理阶段,采用了多步生成的方式,每个步骤都使用LLM生成相应的中间产物。为了评估模型的性能,使用了CodeBLEU等指标来衡量生成代码的质量。此外,还进行了消融研究,以评估每个中间产物对最终代码质量的贡献。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架在代码正确性方面取得了显著提升,最高可达75%。在DeepSeek-Coder-1.3B上应用该框架后,CodeBLEU指标相对于ChatGPT-3.5、ChatGPT-4o-mini、DeepSeek-R1和LLaMA-8B分别提升了34.3%、20.0%、11.2%和22.3%。此外,该框架在减少80%训练数据的情况下仍然表现出良好的鲁棒性,证明了其有效性和实用性。
🎯 应用场景
该研究成果可应用于自动化软件开发、代码辅助生成、软件测试等领域。通过将软件工程的生命周期融入到代码生成过程中,可以提高代码的质量和可靠性,降低开发成本,并加速软件开发周期。未来,该方法有望应用于更复杂的软件系统开发,并与其他AI技术相结合,实现更智能化的软件开发。
📄 摘要(原文)
Recent progress in large language models (LLMs) has advanced automatic code generation, yet most approaches rely on direct, single-step translation from problem descriptions to code, disregarding structured software engineering practices. We introduce a lifecycle-aware framework that systematically incorporates intermediate artifacts such as requirements analysis, state machine modeling, and pseudocode into both the training and inference stages. This design aligns code generation with standard software development phases and enables more structured reasoning. Experiments show that lifecycle-level fine-tuning improves code correctness by up to 75% over the same model before fine-tuning, with performance gains compounding across intermediate stages. Multi-step inference consistently surpasses single-step generation, demonstrating the effectiveness of intermediate scaffolding. Notably, open-source LLMs, once fine-tuned under our framework, match or slightly outperform models pretrained on code. When applied to DeepSeek-Coder-1.3B, our framework yields relative CodeBLEU improvements of 34.3%, 20.0%, 11.2%, and 22.3% over ChatGPT-3.5, ChatGPT-4o-mini, DeepSeek-R1, and LLaMA-8B, respectively. Our pipeline also proves robust with up to 80\% less training data, confirming its resilience. Ablation studies further reveal that each intermediate artifact contributes distinctly to final code quality, with state machine modeling yielding the most substantial impact. Our source code and detailed experimental data are available at https://anonymous.4open.science/r/Lifecycle-Aware-3CCB.