Quantifying Document Impact in RAG-LLMs
作者: Armin Gerami, Kazem Faghih, Ramani Duraiswami
分类: cs.IR, cs.AI, cs.CL, cs.LG
发布日期: 2025-10-27
💡 一句话要点
提出Influence Score (IS)以量化RAG中单个文档对生成结果的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 大型语言模型 文档影响力 Partial Information Decomposition
📋 核心要点
- 现有RAG评估缺乏量化单个文档对生成结果影响的指标,难以评估系统可信度。
- 论文提出Influence Score (IS),基于Partial Information Decomposition,衡量文档对生成响应的影响。
- 实验表明IS能有效识别恶意文档,且基于IS排序的文档生成的响应更接近原始响应。
📝 摘要(中文)
检索增强生成(RAG)通过将大型语言模型(LLM)连接到外部知识来增强其能力,从而提高准确性并减少过时信息。然而,这也带来了一些挑战,例如事实不一致、来源冲突、偏差传播和安全漏洞,这些问题会降低RAG系统的可信度。当前RAG评估的一个关键差距是缺乏一种指标来量化单个检索文档对最终输出的贡献。为了解决这个问题,我们引入了Influence Score (IS),这是一种基于Partial Information Decomposition的新型指标,用于衡量每个检索文档对生成响应的影响。我们通过两个实验验证了IS。首先,在三个数据集上的中毒攻击模拟表明,IS在86%的情况下正确地将恶意文档识别为最具影响力的文档。其次,一项消融研究表明,仅使用IS排名最高的文档生成的响应,比从剩余文档生成的响应更接近原始响应。这些结果证实了IS在隔离和量化文档影响方面的有效性,为提高RAG系统的透明度和可靠性提供了一个有价值的工具。
🔬 方法详解
问题定义:论文旨在解决RAG系统中,缺乏量化单个检索文档对最终生成结果影响的指标的问题。现有方法难以评估每个文档的贡献,从而难以诊断和解决RAG系统中的事实不一致、来源冲突、偏差传播等问题。这阻碍了RAG系统的可信度和可靠性。
核心思路:论文的核心思路是利用Partial Information Decomposition (PID) 的概念,将生成结果的信息分解为来自不同检索文档的独立贡献和冗余贡献。通过计算每个文档对生成结果的独立信息贡献,可以量化该文档的影响力。影响力越大,说明该文档对生成结果的贡献越大。
技术框架:该方法主要包含以下几个步骤:1)使用RAG系统生成响应;2)利用Partial Information Decomposition (PID) 将生成结果的信息分解为来自不同检索文档的独立贡献和冗余贡献;3)计算每个文档的Influence Score (IS),即该文档对生成结果的独立信息贡献。IS越高,表示该文档的影响力越大。
关键创新:该论文的关键创新在于提出了Influence Score (IS) 这一新型指标,并将其应用于RAG系统的文档影响力评估。与现有方法相比,IS能够量化单个文档对生成结果的独立贡献,从而更准确地评估文档的影响力。此外,IS基于Partial Information Decomposition,能够区分独立贡献和冗余贡献,从而更全面地理解文档之间的关系。
关键设计:论文中,Partial Information Decomposition的具体实现方式以及如何将PID的结果转化为Influence Score是关键设计。具体而言,论文可能需要选择合适的PID算法(例如,基于Shannon信息论的PID方法),并定义如何将PID分解出的独立信息量作为Influence Score。此外,如何处理文本数据,例如使用词嵌入或语言模型来表示文本,也是需要考虑的关键技术细节。
🖼️ 关键图片
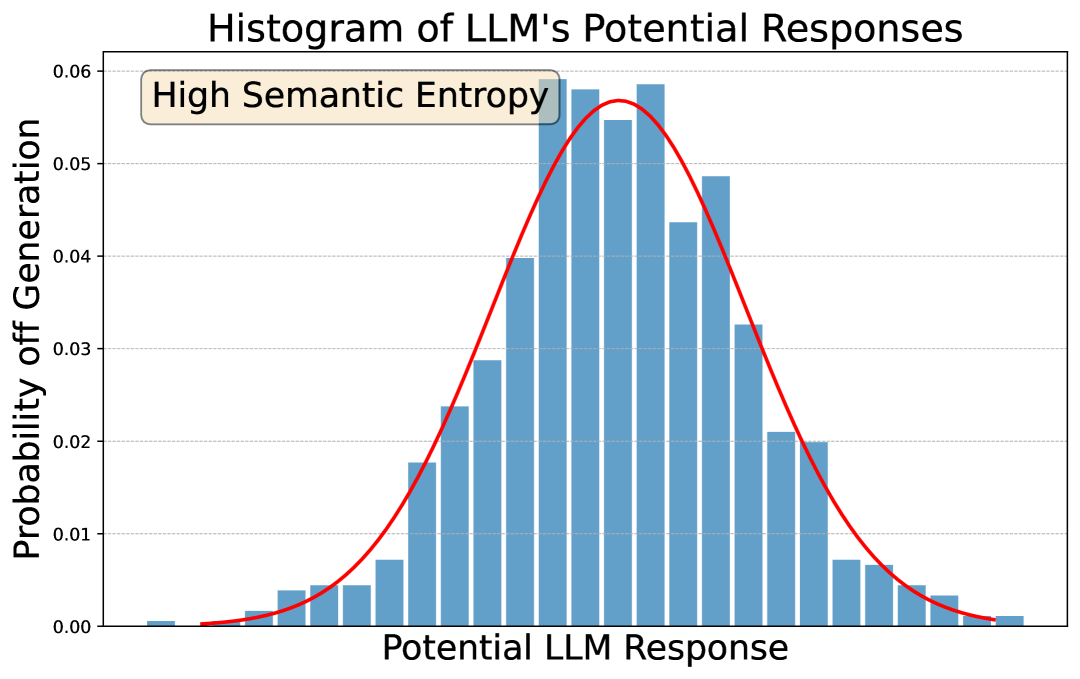
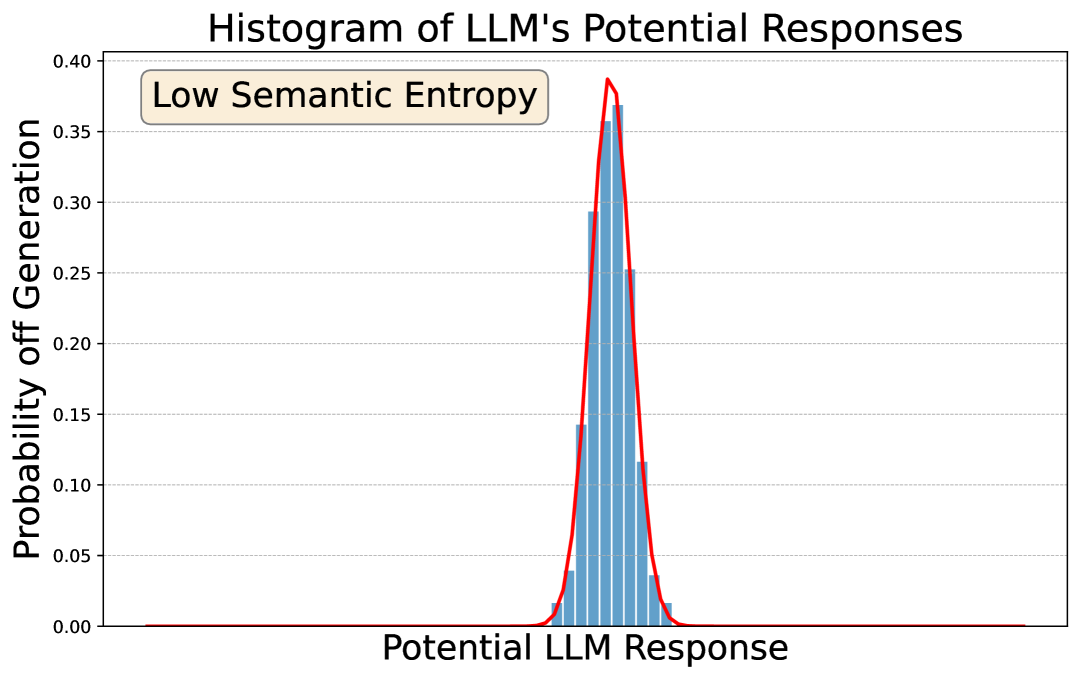
📊 实验亮点
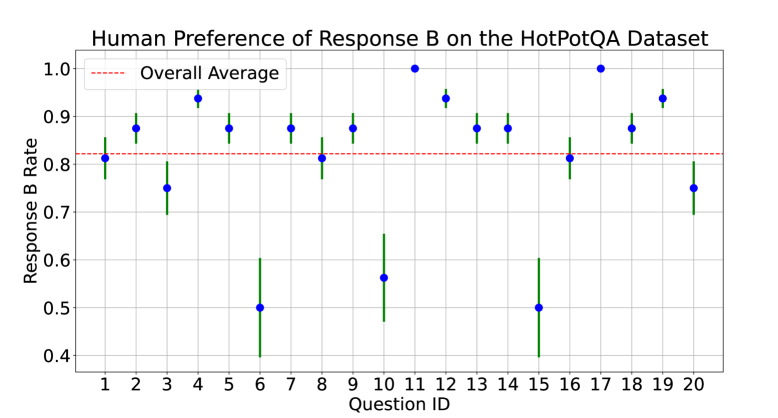
实验结果表明,Influence Score (IS) 在中毒攻击模拟中,能够以86%的准确率识别出恶意文档。消融实验表明,使用IS排序最高的文档生成的响应,比使用剩余文档生成的响应更接近原始响应。这些结果验证了IS在量化文档影响力方面的有效性。
🎯 应用场景
该研究成果可应用于提升RAG系统的透明度和可靠性,例如,可以用于识别和过滤恶意文档,减少RAG系统中的事实错误和偏见。此外,该方法还可以用于优化RAG系统的检索策略,选择更具影响力的文档,从而提高生成结果的质量。该研究对于构建可信赖的AI系统具有重要意义。
📄 摘要(原文)
Retrieval Augmented Generation (RAG) enhances Large Language Models (LLMs) by connecting them to external knowledge, improving accuracy and reducing outdated information. However, this introduces challenges such as factual inconsistencies, source conflicts, bias propagation, and security vulnerabilities, which undermine the trustworthiness of RAG systems. A key gap in current RAG evaluation is the lack of a metric to quantify the contribution of individual retrieved documents to the final output. To address this, we introduce the Influence Score (IS), a novel metric based on Partial Information Decomposition that measures the impact of each retrieved document on the generated response. We validate IS through two experiments. First, a poison attack simulation across three datasets demonstrates that IS correctly identifies the malicious document as the most influential in $86\%$ of cases. Second, an ablation study shows that a response generated using only the top-ranked documents by IS is consistently judged more similar to the original response than one generated from the remaining documents. These results confirm the efficacy of IS in isolating and quantifying document influence, offering a valuable tool for improving the transparency and reliability of RAG systems.