Decentralized Multi-Agent Goal Assignment for Path Planning using Large Language Models
作者: Murad Ismayilov, Edwin Meriaux, Shuo Wen, Gregory Dudek
分类: cs.AI
发布日期: 2025-10-27
备注: Accepted at MIT URTC 2025
💡 一句话要点
利用大语言模型实现去中心化多智能体目标分配与路径规划
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 目标分配 路径规划 大语言模型 去中心化 机器人 人工智能
📋 核心要点
- 现有去中心化多智能体目标分配方法缺乏有效利用环境信息的机制,导致次优的整体性能。
- 论文提出利用大语言模型(LLM)理解环境信息并生成目标偏好,从而实现更智能的目标分配。
- 实验表明,在适当提示下,基于LLM的智能体在makespan指标上接近最优,显著优于传统启发式算法。
📝 摘要(中文)
本文研究了去中心化条件下多智能体共享环境中的目标分配问题,这是机器人和人工智能领域长期存在的挑战。论文提出一种基于大语言模型(LLM)的去中心化多智能体路径规划目标分配方法。智能体基于环境的结构化表示(包括网格可视化和场景数据)独立生成排序后的目标偏好。在推理阶段后,智能体交换目标排序,并通过固定的确定性冲突解决规则(例如,智能体索引排序)确定分配,无需协商或迭代协调。论文在完全可观察的网格世界环境中系统地比较了贪婪启发式算法、最优分配算法和基于LLM的智能体。结果表明,当提供精心设计的提示和相关的定量信息时,基于LLM的智能体可以实现接近最优的makespan,并且始终优于传统的启发式算法。这些发现强调了语言模型在多智能体路径规划中去中心化目标分配方面的潜力,并突出了信息结构在此类系统中的重要性。
🔬 方法详解
问题定义:论文旨在解决去中心化多智能体路径规划中的目标分配问题。传统方法,如贪婪算法,通常无法充分利用环境信息,导致智能体选择次优目标,从而影响整体任务效率。现有方法缺乏有效的沟通和协商机制,容易陷入局部最优解。
核心思路:论文的核心思路是利用大语言模型(LLM)的强大推理能力,使每个智能体能够根据环境信息(如网格地图和场景描述)生成更合理的、排序后的目标偏好。通过让智能体交换这些偏好,即使在没有集中协调的情况下,也能实现更优的目标分配。
技术框架:整体框架包含以下几个阶段:1) 环境感知:每个智能体获取局部环境信息,包括网格地图和场景数据。2) 目标偏好生成:智能体使用LLM,基于环境信息生成排序后的目标偏好列表。LLM通过精心设计的prompt进行引导,prompt中包含环境描述和目标相关信息。3) 目标偏好交换:智能体之间交换各自的目标偏好列表。4) 目标分配:根据预定义的冲突解决规则(例如,智能体ID优先级),确定每个智能体的最终目标。
关键创新:最重要的创新在于利用LLM进行去中心化的目标偏好生成。与传统启发式算法相比,LLM能够更好地理解环境信息,并生成更符合全局最优的目标偏好。此外,该方法无需智能体之间的迭代协商,降低了通信成本和计算复杂度。
关键设计:关键设计包括:1) Prompt设计:prompt需要包含清晰的环境描述、目标相关信息以及对LLM的指令,以引导LLM生成合理的目标偏好。2) 冲突解决规则:论文采用简单的智能体ID优先级规则,但也可以探索更复杂的规则,例如基于目标价值或智能体能力的规则。3) LLM的选择和微调:选择合适的LLM,并根据具体任务进行微调,可以进一步提升目标分配的性能。
🖼️ 关键图片
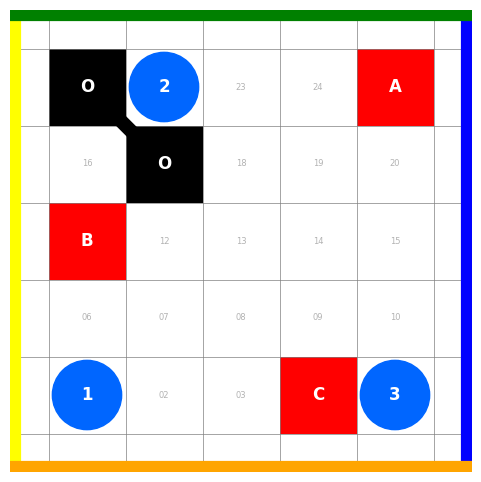
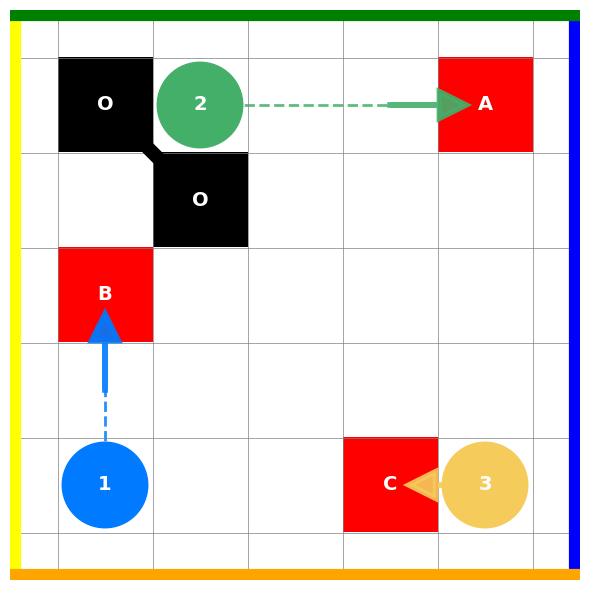
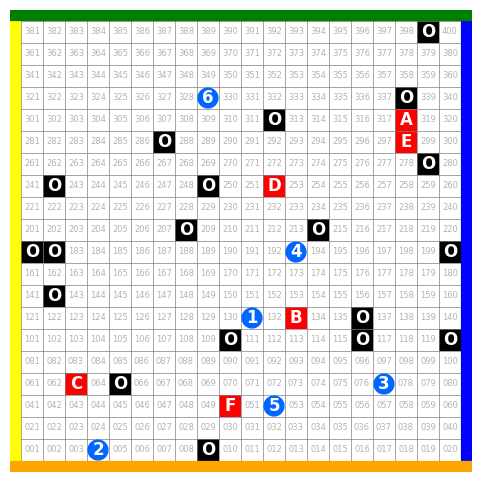
📊 实验亮点
实验结果表明,在网格世界环境中,基于LLM的智能体在makespan指标上显著优于传统的贪婪启发式算法,并且能够达到接近最优的性能。具体而言,在某些场景下,LLM智能体的makespan比贪婪算法降低了10%-20%。这表明LLM在去中心化多智能体目标分配方面具有巨大的潜力。
🎯 应用场景
该研究成果可应用于仓库机器人、自动驾驶车队、无人机集群等领域。在这些场景中,多个智能体需要在去中心化的条件下协同完成任务,例如货物搬运、交通调度、环境监测等。利用该方法,可以提高任务效率、降低运营成本,并增强系统的鲁棒性。
📄 摘要(原文)
Coordinating multiple autonomous agents in shared environments under decentralized conditions is a long-standing challenge in robotics and artificial intelligence. This work addresses the problem of decentralized goal assignment for multi-agent path planning, where agents independently generate ranked preferences over goals based on structured representations of the environment, including grid visualizations and scenario data. After this reasoning phase, agents exchange their goal rankings, and assignments are determined by a fixed, deterministic conflict-resolution rule (e.g., agent index ordering), without negotiation or iterative coordination. We systematically compare greedy heuristics, optimal assignment, and large language model (LLM)-based agents in fully observable grid-world settings. Our results show that LLM-based agents, when provided with well-designed prompts and relevant quantitative information, can achieve near-optimal makespans and consistently outperform traditional heuristics. These findings underscore the potential of language models for decentralized goal assignment in multi-agent path planning and highlight the importance of information structure in such systems.