ReCAP: Recursive Context-Aware Reasoning and Planning for Large Language Model Agents
作者: Zhenyu Zhang, Tianyi Chen, Weiran Xu, Alex Pentland, Jiaxin Pei
分类: cs.AI
发布日期: 2025-10-27
期刊: 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
💡 一句话要点
ReCAP:用于大语言模型Agent的递归上下文感知推理与规划
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 长程推理 递归规划 上下文感知 Agent
📋 核心要点
- 现有大语言模型在长程任务中面临上下文漂移和目标信息丢失等问题,导致推理和规划能力受限。
- ReCAP通过提前规划分解、父计划结构化再注入和内存高效执行,实现跨层级上下文一致性。
- 实验表明,ReCAP在Robotouille等长程推理任务中显著提升了子目标对齐和成功率。
📝 摘要(中文)
长程任务需要多步推理和动态重规划,这对大型语言模型(LLM)来说仍然具有挑战性。顺序提示方法容易出现上下文漂移、目标信息丢失和循环失败,而分层提示方法通常会削弱跨层连续性或产生大量的运行时开销。我们引入了ReCAP(递归上下文感知推理与规划),这是一个具有共享上下文的分层框架,用于LLM中的推理和规划。ReCAP结合了三个关键机制:(i)提前规划分解,模型生成完整的子任务列表,执行第一个项目,并改进其余项目;(ii)父计划的结构化再注入,在递归返回期间保持一致的多层上下文;(iii)内存高效执行,限制活动提示,使成本随任务深度线性扩展。这些机制共同将高层目标与低层动作对齐,减少冗余提示,并在递归中保持连贯的上下文更新。实验表明,ReCAP显著提高了各种长程推理基准测试中的子目标对齐和成功率,在同步Robotouille上实现了32%的提升,在严格的pass@1协议下,异步Robotouille上实现了29%的提升。
🔬 方法详解
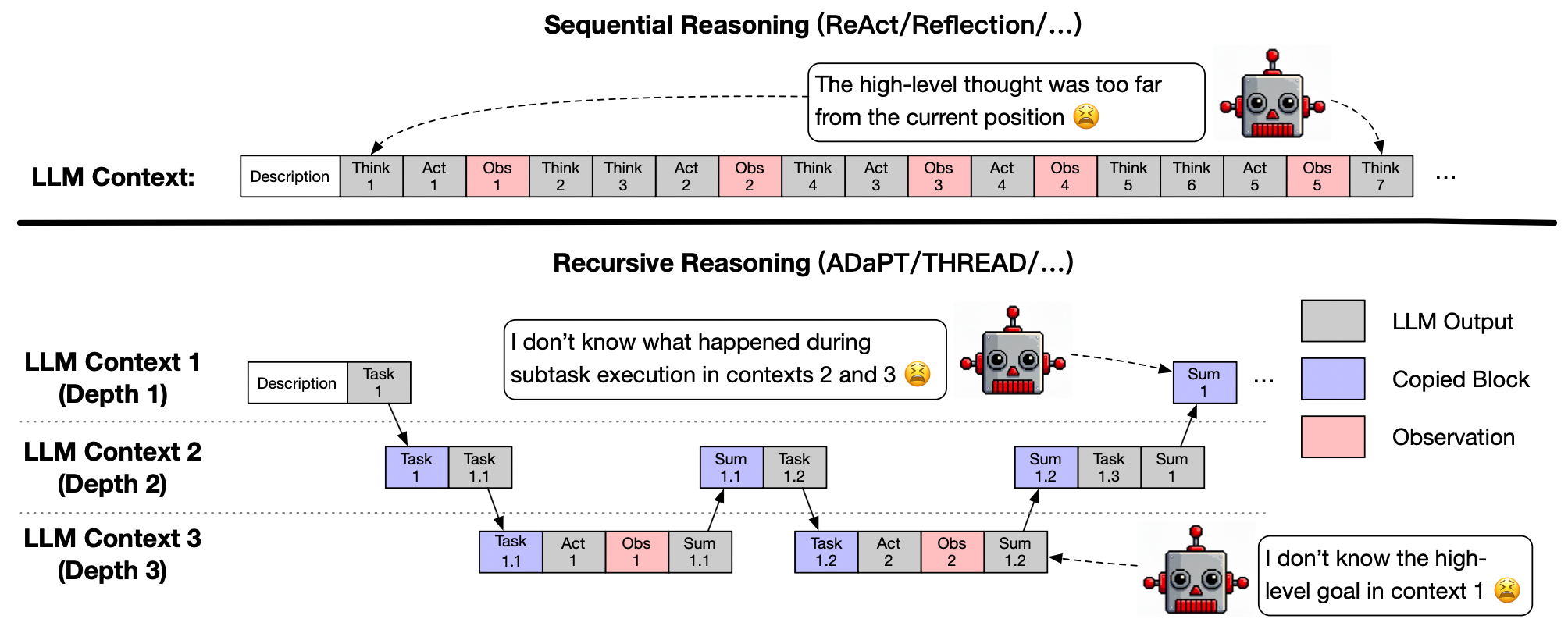
问题定义:论文旨在解决大型语言模型(LLM)在长程任务中进行多步推理和动态重规划时遇到的困难。现有方法,如顺序提示,容易出现上下文漂移、目标信息丢失和循环失败。分层提示虽然试图解决这些问题,但往往会削弱跨层级的连续性,或者引入过高的运行时开销。这些问题限制了LLM在复杂任务中的应用能力。
核心思路:ReCAP的核心思路是构建一个递归的、上下文感知的推理和规划框架,通过共享上下文来保持高层目标和低层动作之间的一致性。该框架通过提前规划分解任务,并在递归过程中不断更新和优化计划,从而避免上下文漂移和目标信息丢失。同时,通过内存高效的执行机制,降低了运行时开销。
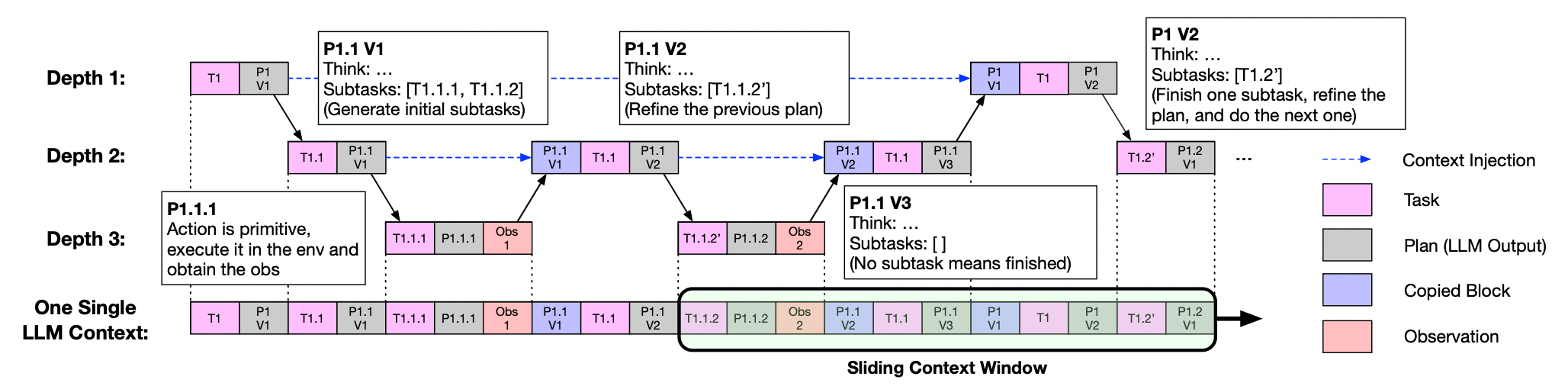
技术框架:ReCAP框架包含三个主要模块:(1)提前规划分解:模型首先生成一个完整的子任务列表,然后执行第一个子任务,并根据执行结果改进剩余的子任务列表。(2)父计划结构化再注入:在递归返回时,将父计划的信息结构化地注入到子任务的上下文中,以保持多层上下文的一致性。(3)内存高效执行:通过限制活动提示的长度,使计算成本随任务深度线性增长,从而提高效率。
关键创新:ReCAP的关键创新在于其递归的上下文感知机制,它能够有效地将高层目标与低层动作对齐,减少冗余提示,并在递归过程中保持连贯的上下文更新。与传统的顺序提示和分层提示方法相比,ReCAP能够更好地处理长程任务中的复杂依赖关系和动态变化。
关键设计:ReCAP的关键设计包括:子任务分解的粒度控制(未知),父计划再注入的具体格式(未知),以及活动提示长度的限制策略(未知)。这些设计细节直接影响着ReCAP的性能和效率,需要在实际应用中进行仔细调整。
🖼️ 关键图片

📊 实验亮点
ReCAP在Robotouille基准测试中表现出色,在同步Robotouille上实现了32%的提升,在异步Robotouille上实现了29%的提升(pass@1)。这些结果表明,ReCAP能够显著提高LLM在长程推理任务中的子目标对齐和成功率,优于现有的顺序提示和分层提示方法。
🎯 应用场景
ReCAP框架可应用于需要长期规划和复杂推理的各种任务,例如机器人导航、任务调度、游戏AI和智能助手。通过提高LLM在长程任务中的推理和规划能力,ReCAP可以帮助实现更智能、更自主的智能体,从而在自动化、决策支持和人机交互等领域发挥重要作用。
📄 摘要(原文)
Long-horizon tasks requiring multi-step reasoning and dynamic re-planning remain challenging for large language models (LLMs). Sequential prompting methods are prone to context drift, loss of goal information, and recurrent failure cycles, while hierarchical prompting methods often weaken cross-level continuity or incur substantial runtime overhead. We introduce ReCAP (Recursive Context-Aware Reasoning and Planning), a hierarchical framework with shared context for reasoning and planning in LLMs. ReCAP combines three key mechanisms: (i) plan-ahead decomposition, in which the model generates a full subtask list, executes the first item, and refines the remainder; (ii) structured re-injection of parent plans, maintaining consistent multi-level context during recursive return; and (iii) memory-efficient execution, bounding the active prompt so costs scale linearly with task depth. Together these mechanisms align high-level goals with low-level actions, reduce redundant prompting, and preserve coherent context updates across recursion. Experiments demonstrate that ReCAP substantially improves subgoal alignment and success rates on various long-horizon reasoning benchmarks, achieving a 32% gain on synchronous Robotouille and a 29% improvement on asynchronous Robotouille under the strict pass@1 protocol.