Game-TARS: Pretrained Foundation Models for Scalable Generalist Multimodal Game Agents
作者: Zihao Wang, Xujing Li, Yining Ye, Junjie Fang, Haoming Wang, Longxiang Liu, Shihao Liang, Junting Lu, Zhiyong Wu, Jiazhan Feng, Wanjun Zhong, Zili Li, Yu Wang, Yu Miao, Bo Zhou, Yuanfan Li, Hao Wang, Zhongkai Zhao, Faming Wu, Zhengxuan Jiang, Weihao Tan, Heyuan Yao, Shi Yan, Xiangyang Li, Yitao Liang, Yujia Qin, Guang Shi
分类: cs.AI
发布日期: 2025-10-27
💡 一句话要点
Game-TARS:基于预训练通用多模态游戏Agent,实现跨域可扩展性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 通用游戏Agent 多模态预训练 键盘鼠标控制 跨域学习 强化学习 大规模预训练 稀疏推理
📋 核心要点
- 现有游戏Agent依赖API或GUI,限制了其在异构环境中的通用性和可扩展性,难以进行大规模预训练。
- Game-TARS采用统一的、与人类对齐的键盘鼠标动作空间,并结合衰减持续损失和稀疏思考策略,实现跨域大规模预训练。
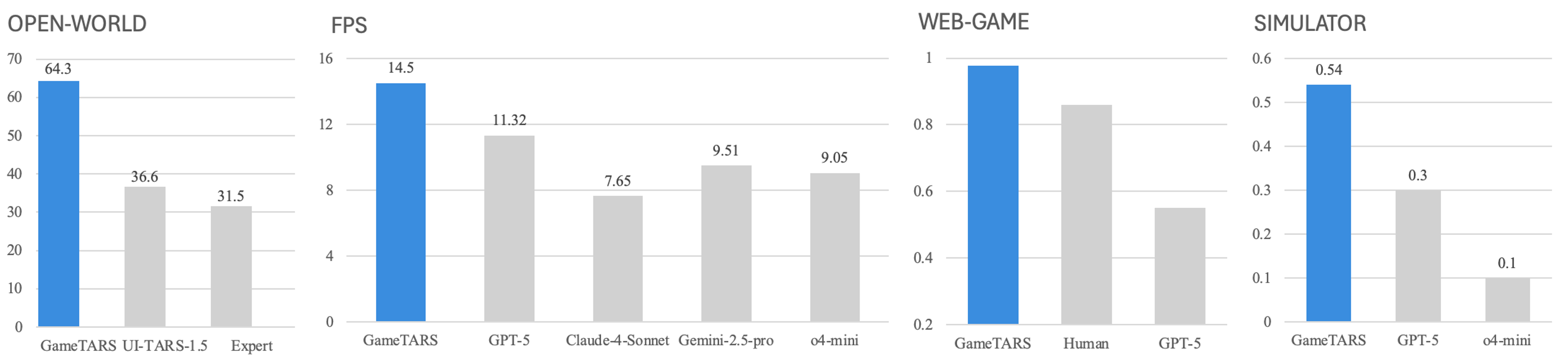
- 实验表明,Game-TARS在多个游戏任务中显著优于现有模型,包括Minecraft、Web游戏和FPS游戏,验证了其通用性和可扩展性。
📝 摘要(中文)
本文提出了Game-TARS,一种通用的游戏Agent,它使用统一的、可扩展的动作空间,该空间锚定于与人类对齐的原始键盘鼠标输入。与基于API或GUI的方法不同,这种范式支持跨异构领域(包括操作系统、Web和模拟游戏)的大规模持续预训练。Game-TARS在超过5000亿tokens的多样化轨迹和多模态数据上进行预训练。关键技术包括用于减少因果混淆的衰减持续损失和平衡推理深度与推理成本的高效稀疏思考策略。实验表明,Game-TARS在开放世界Minecraft任务上的成功率是先前SOTA模型的约2倍,在未见过的Web 3D游戏中接近新手的通用性,并且在FPS基准测试中优于GPT-5、Gemini-2.5-Pro和Claude-4-Sonnet。训练时间和测试时间的扩展结果证实,统一的动作空间在扩展到跨游戏和多模态数据时能够保持改进。我们的结果表明,简单、可扩展的动作表示与大规模预训练相结合,为具有广泛计算机使用能力的通用Agent提供了一条有希望的途径。
🔬 方法详解
问题定义:现有游戏Agent通常依赖于特定游戏或环境的API或GUI接口,这限制了它们在不同游戏和环境之间的迁移能力。此外,这种依赖性使得难以进行大规模的、跨领域的预训练,因为不同游戏的API和GUI接口差异很大。因此,如何设计一种通用的、可扩展的游戏Agent,使其能够在各种不同的游戏和环境中表现良好,是一个重要的挑战。
核心思路:Game-TARS的核心思路是使用统一的、与人类对齐的键盘鼠标动作空间作为Agent的输出。这种动作空间具有通用性,可以应用于各种不同的游戏和环境。此外,通过大规模的预训练,Agent可以学习到通用的游戏策略和技能,从而在不同的游戏和环境中表现良好。为了解决大规模持续预训练中的因果混淆问题,论文还提出了衰减持续损失。
技术框架:Game-TARS的整体框架包括以下几个主要模块:1) 多模态输入编码器:用于将游戏画面、音频和文本等信息编码成向量表示。2) 动作预测器:用于根据当前的输入向量预测Agent的动作。3) 衰减持续损失:用于减少大规模持续预训练中的因果混淆问题。4) 稀疏思考策略:用于平衡推理深度和推理成本。
关键创新:Game-TARS最重要的技术创新点在于其统一的、与人类对齐的键盘鼠标动作空间。与传统的基于API或GUI的动作空间相比,这种动作空间具有通用性和可扩展性,可以应用于各种不同的游戏和环境。此外,衰减持续损失和稀疏思考策略也是重要的创新点,它们分别解决了大规模持续预训练中的因果混淆问题和推理成本问题。
关键设计:Game-TARS的关键设计包括:1) 统一的键盘鼠标动作空间:包括鼠标移动、键盘按键等操作。2) 衰减持续损失:通过对不同时间步的损失进行加权,减少因果混淆。3) 稀疏思考策略:根据当前的状态动态调整推理深度,平衡推理成本和性能。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
Game-TARS在开放世界Minecraft任务上的成功率是先前SOTA模型的约2倍。在未见过的Web 3D游戏中,Game-TARS的表现接近新手的水平,展示了其强大的泛化能力。在FPS基准测试中,Game-TARS优于GPT-5、Gemini-2.5-Pro和Claude-4-Sonnet等大型语言模型,证明了其在特定任务上的竞争力。这些实验结果充分验证了Game-TARS的有效性和优越性。
🎯 应用场景
Game-TARS的潜在应用领域包括游戏AI、自动化测试、人机交互等。它可以用于开发更智能、更通用的游戏Agent,提高游戏体验。此外,它还可以用于自动化测试,减少人工测试的成本。在人机交互方面,它可以用于开发更自然、更高效的人机交互界面,提高用户体验。未来,Game-TARS有望成为通用人工智能的重要组成部分。
📄 摘要(原文)
We present Game-TARS, a generalist game agent trained with a unified, scalable action space anchored to human-aligned native keyboard-mouse inputs. Unlike API- or GUI-based approaches, this paradigm enables large-scale continual pre-training across heterogeneous domains, including OS, web, and simulation games. Game-TARS is pre-trained on over 500B tokens with diverse trajectories and multimodal data. Key techniques include a decaying continual loss to reduce causal confusion and an efficient Sparse-Thinking strategy that balances reasoning depth and inference cost. Experiments show that Game-TARS achieves about 2 times the success rate over the previous sota model on open-world Minecraft tasks, is close to the generality of fresh humans in unseen web 3d games, and outperforms GPT-5, Gemini-2.5-Pro, and Claude-4-Sonnet in FPS benchmarks. Scaling results on training-time and test-time confirm that the unified action space sustains improvements when scaled to cross-game and multimodal data. Our results demonstrate that simple, scalable action representations combined with large-scale pre-training provide a promising path toward generalist agents with broad computer-use abilities.