RefleXGen:The unexamined code is not worth using
作者: Bin Wang, Hui Li, AoFan Liu, BoTao Yang, Ao Yang, YiLu Zhong, Weixiang Huang, Yanping Zhang, Runhuai Huang, Weimin Zeng
分类: cs.SE, cs.AI, cs.CR
发布日期: 2025-10-27
期刊: ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 2025, pp. 1-5
DOI: 10.1109/ICASSP49660.2025.10890824
💡 一句话要点
RefleXGen:通过自反思提升LLM代码生成的安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 安全性 自反思 检索增强生成 RAG 安全漏洞 迭代优化
📋 核心要点
- 现有代码生成方法依赖微调或特定数据集,成本高昂且泛化性不足,难以有效应对代码安全挑战。
- RefleXGen利用RAG和LLM自反思机制,迭代优化代码生成过程,无需额外资源即可提升安全性。
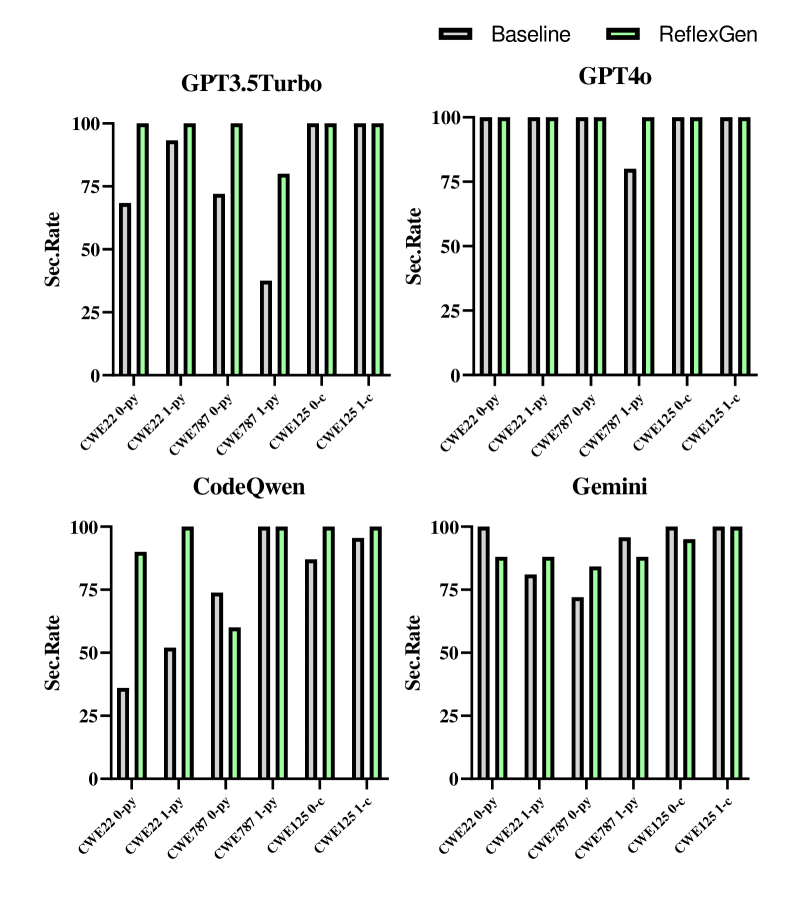
- 实验表明,RefleXGen在多个LLM上显著提升代码安全性,验证了自反思在安全代码生成中的有效性。
📝 摘要(中文)
本文提出了一种名为RefleXGen的创新方法,旨在显著提高大型语言模型(LLM)在代码生成中的安全性。RefleXGen将检索增强生成(RAG)技术与LLM固有的引导式自反思机制相结合。与依赖于微调LLM或开发专用安全代码数据集的传统方法不同,RefleXGen通过自评估和反思迭代优化代码生成过程,无需大量资源。在该框架内,模型不断积累和完善其知识库,从而逐步提高生成代码的安全性。实验结果表明,RefleXGen显著提高了多个模型的代码安全性,GPT-3.5 Turbo提升了13.6%,GPT-4o提升了6.7%,CodeQwen提升了4.5%,Gemini提升了5.8%。研究结果表明,提高模型自反思的质量是加强AI生成代码安全性的有效且实用的策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在代码生成过程中存在的安全性问题。现有方法,如微调LLM或构建专门的安全代码数据集,通常需要大量的计算资源和人工标注,并且可能难以泛化到新的安全漏洞。因此,如何以更高效、更通用的方式提升LLM生成代码的安全性是一个重要的挑战。
核心思路:RefleXGen的核心思路是利用LLM自身的自反思能力,结合检索增强生成(RAG)技术,迭代地改进代码生成过程。通过让LLM对生成的代码进行自我评估,并根据评估结果进行反思和改进,从而逐步提高代码的安全性。这种方法避免了对LLM进行大规模的微调,也无需依赖于特定的安全代码数据集。
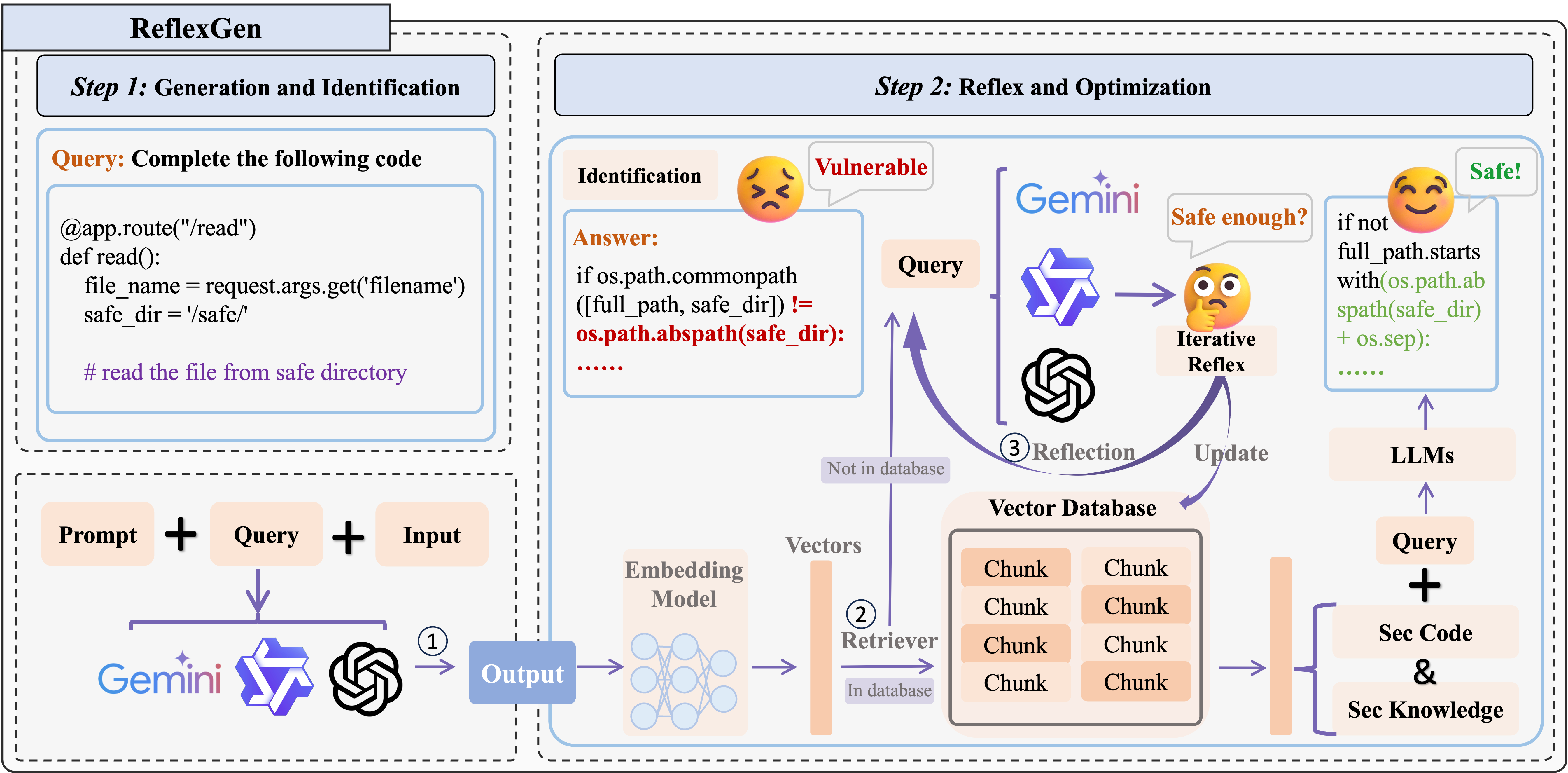
技术框架:RefleXGen的整体框架包含以下几个主要阶段:1) 代码生成:LLM根据给定的任务描述生成初始代码。2) 安全评估:LLM对生成的代码进行安全评估,识别潜在的安全漏洞。3) 反思与改进:LLM根据安全评估的结果,对代码进行反思和改进,修复已识别的安全漏洞。4) 知识积累:将反思和改进的过程中的经验知识积累到知识库中,用于指导后续的代码生成过程。这个过程会迭代进行,直到生成的代码达到预定的安全标准。
关键创新:RefleXGen的关键创新在于将RAG技术与LLM的自反思机制相结合,形成一个闭环的迭代优化过程。与传统的代码生成方法相比,RefleXGen能够更有效地利用LLM自身的知识和能力,从而在无需大量资源的情况下,显著提升代码的安全性。此外,RefleXGen的知识积累机制能够使模型不断学习和进化,从而更好地应对新的安全挑战。
关键设计:RefleXGen的关键设计包括:1) 安全评估指标:用于评估代码安全性的指标,例如是否存在SQL注入、跨站脚本攻击等漏洞。2) 反思策略:指导LLM如何根据安全评估结果进行反思和改进的策略,例如可以采用基于规则的反思策略或基于案例的反思策略。3) 知识库构建:用于存储反思和改进过程中积累的经验知识的知识库,例如可以采用向量数据库或图数据库。4) 迭代停止条件:用于判断迭代过程是否应该停止的条件,例如可以设置最大迭代次数或安全评估指标的阈值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RefleXGen在多个LLM上显著提升了代码安全性。具体来说,GPT-3.5 Turbo的安全性提升了13.6%,GPT-4o提升了6.7%,CodeQwen提升了4.5%,Gemini提升了5.8%。这些结果表明,RefleXGen是一种有效且通用的代码安全提升方法,可以应用于不同的LLM,并且能够取得显著的效果。
🎯 应用场景
RefleXGen可应用于各种需要安全代码生成的场景,例如Web应用开发、移动应用开发、物联网设备开发等。通过提高AI生成代码的安全性,RefleXGen可以降低软件开发的安全风险,减少安全漏洞的修复成本,并提高软件系统的整体安全性。未来,RefleXGen有望成为AI辅助软件开发的重要组成部分,推动软件开发行业的智能化和自动化。
📄 摘要(原文)
Security in code generation remains a pivotal challenge when applying large language models (LLMs). This paper introduces RefleXGen, an innovative method that significantly enhances code security by integrating Retrieval-Augmented Generation (RAG) techniques with guided self-reflection mechanisms inherent in LLMs. Unlike traditional approaches that rely on fine-tuning LLMs or developing specialized secure code datasets - processes that can be resource-intensive - RefleXGen iteratively optimizes the code generation process through self-assessment and reflection without the need for extensive resources. Within this framework, the model continuously accumulates and refines its knowledge base, thereby progressively improving the security of the generated code. Experimental results demonstrate that RefleXGen substantially enhances code security across multiple models, achieving a 13.6% improvement with GPT-3.5 Turbo, a 6.7% improvement with GPT-4o, a 4.5% improvement with CodeQwen, and a 5.8% improvement with Gemini. Our findings highlight that improving the quality of model self-reflection constitutes an effective and practical strategy for strengthening the security of AI-generated code.