Emotion-Coherent Reasoning for Multimodal LLMs via Emotional Rationale Verifier
作者: Hyeongseop Rha, Jeong Hun Yeo, Yeonju Kim, Yong Man Ro
分类: cs.AI, cs.HC
发布日期: 2025-10-27 (更新: 2026-01-05)
备注: 15 pages, 11 figures
💡 一句话要点
提出情感推理验证器,提升多模态LLM情感理解与解释一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 情感识别 情感推理 可解释性 人机交互
📋 核心要点
- 现有MLLM在情感理解中,生成的解释与预测的情感不一致,降低了用户信任度。
- 提出情感推理验证器(ERV)和解释奖励,引导模型生成与目标情感一致的推理。
- 实验表明,该方法显著提高了情感解释与预测的一致性,提升了情感识别准确率。
📝 摘要(中文)
多模态大型语言模型(MLLM)的最新进展正在将人机交互(HCI)从表面交流转变为更细致和情感智能的沟通。为了实现这一转变,情感理解变得至关重要,它允许系统捕捉用户意图背后的微妙线索。此外,为预测的情感提供可信的解释对于确保可解释性和建立用户信任至关重要。然而,目前基于MLLM的方法通常会产生与目标标签不同的情感解释,有时甚至与它们自己预测的情感相矛盾。这种不一致性构成了误解的关键风险,并削弱了交互设置中的可靠性。为了解决这个问题,我们提出了一种新颖的方法:情感推理验证器(ERV)和解释奖励。我们的方法引导模型在多模态情感识别期间产生与目标情感明确一致的推理,而无需修改模型架构或需要额外的配对视频-描述注释。我们的方法显着提高了MAFW和DFEW数据集上可信的解释-预测一致性和解释情感准确性。通过广泛的实验和人工评估,我们表明我们的方法不仅增强了解释和预测之间的一致性,而且还使MLLM能够提供情感连贯、值得信赖的交互,标志着朝着真正类人HCI系统迈出的关键一步。
🔬 方法详解
问题定义:现有基于多模态LLM的情感识别方法,在生成情感解释时,经常出现解释与模型预测的情感标签不一致的情况。这种不一致性会降低模型的可信度,阻碍人机交互的自然性和可靠性。现有方法缺乏对情感解释的有效约束,导致模型在生成解释时偏离目标情感。
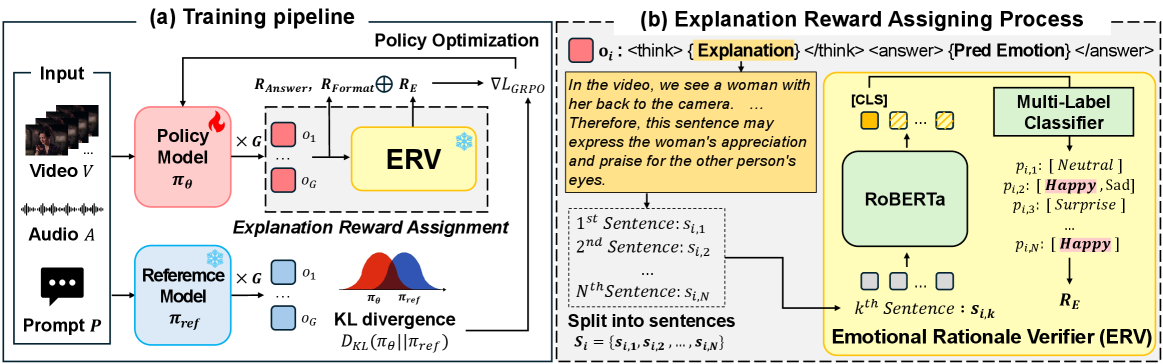
核心思路:论文的核心思路是引入一个情感推理验证器(ERV),用于评估模型生成的情感解释与目标情感标签的一致性。通过ERV的反馈,模型可以学习生成更符合目标情感的解释。此外,论文还提出了一个解释奖励机制,鼓励模型生成更准确、更连贯的情感解释。这种设计旨在增强模型的情感推理能力,提高解释的可信度。
技术框架:整体框架包含多模态LLM、情感推理验证器(ERV)和解释奖励模块。多模态LLM负责接收输入的多模态数据(例如,视频和文本),并预测情感标签和生成情感解释。ERV用于评估生成的情感解释与目标情感标签的一致性,并提供反馈信号。解释奖励模块根据ERV的反馈,对模型生成的情感解释进行奖励或惩罚,从而引导模型学习生成更准确、更连贯的解释。整个流程通过训练,使得MLLM生成的情感解释与预测的情感标签更加一致。
关键创新:论文的关键创新在于提出了情感推理验证器(ERV)和解释奖励机制。ERV能够有效地评估情感解释与目标情感的一致性,并为模型提供有价值的反馈信号。解释奖励机制能够根据ERV的反馈,引导模型学习生成更准确、更连贯的情感解释。这种方法不需要修改模型架构或额外的标注数据,具有很强的实用性。
关键设计:ERV的具体实现方式未知,但其核心功能是判断生成的情感解释是否支持或符合目标情感标签。解释奖励的具体形式也未知,但它应该能够根据ERV的反馈,对模型生成的情感解释进行量化评估,并将其转化为可用于训练的奖励信号。损失函数的设计需要考虑情感预测的准确性和解释的一致性,可能采用交叉熵损失和一致性损失的加权组合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在MAFW和DFEW数据集上显著提高了情感解释与预测的一致性,以及情感解释的准确性。具体性能提升数据未知,但通过人工评估,该方法能够使MLLM提供情感连贯、值得信赖的交互,朝着真正类人HCI系统迈出了关键一步。
🎯 应用场景
该研究成果可应用于情感智能人机交互系统、情感分析、智能客服、心理健康评估等领域。通过提高机器对人类情感的理解和表达能力,可以构建更自然、更流畅、更具同理心的人机交互体验。例如,在智能客服中,系统可以根据用户的情感状态提供个性化的服务,从而提高用户满意度。
📄 摘要(原文)
The recent advancement of Multimodal Large Language Models (MLLMs) is transforming human-computer interaction (HCI) from surface-level exchanges into more nuanced and emotionally intelligent communication. To realize this shift, emotion understanding becomes essential allowing systems to capture subtle cues underlying user intent. Furthermore, providing faithful explanations for predicted emotions is crucial to ensure interpretability and build user trust. However, current MLLM-based methods often generate emotion explanations that diverge from the target labels and sometimes even contradict their own predicted emotions. This inconsistency poses a critical risk for misunderstanding and erodes reliability in interactive settings. To address this, we propose a novel approach: the Emotional Rationale Verifier (ERV) and an Explanation Reward. Our method guides the model to produce reasoning that is explicitly consistent with the target emotion during multimodal emotion recognition without modifying the model architecture or requiring additional paired video-description annotations. Our method significantly improves faithful explanation-prediction consistency and explanation emotion accuracy on the MAFW and DFEW datasets. Through extensive experiments and human evaluations, we show that our approach not only enhances alignment between explanation and prediction but also empowers MLLMs to deliver emotionally coherent, trustworthy interactions, marking a key step toward truly human-like HCI systems.