Human-Like Goalkeeping in a Realistic Football Simulation: a Sample-Efficient Reinforcement Learning Approach
作者: Alessandro Sestini, Joakim Bergdahl, Jean-Philippe Barrette-LaPierre, Florian Fuchs, Brady Chen, Michael Jones, Linus Gisslén
分类: cs.AI, cs.LG
发布日期: 2025-10-27 (更新: 2025-10-30)
💡 一句话要点
提出一种高效强化学习方法,用于在真实足球游戏中训练类人守门员AI。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 样本效率 类人AI 足球游戏 守门员AI
📋 核心要点
- 现有深度强化学习方法训练超人智能体,模型庞大,不适用于资源有限的游戏工作室,难以实现类人AI。
- 该论文提出一种样本高效的深度强化学习方法,通过利用预收集数据和增加网络可塑性来提升训练效率。
- 实验结果表明,该方法训练的守门员AI在EA SPORTS FC 25中扑救率超过内置AI 10%,训练速度提升50%。
📝 摘要(中文)
本文提出了一种高效的深度强化学习(DRL)方法,专门用于在视频游戏行业等工业环境中训练和微调AI智能体,使其行为更贴近人类。现有研究侧重于训练具有大型模型的超人智能体,这对于资源有限且旨在创建类人智能体的游戏工作室来说是不切实际的。该方法通过利用预收集的数据和增加网络可塑性来提高基于价值的DRL的样本效率。我们在EA SPORTS FC 25中训练守门员智能体来评估该方法。结果表明,我们的智能体在扑救率方面优于游戏内置AI 10%。消融研究表明,与标准DRL方法相比,我们的方法训练智能体的速度提高了50%。领域专家的定性评估表明,与手工制作的智能体相比,我们的方法创造了更像人类的游戏体验。该方法已被用于该系列的最新版本。
🔬 方法详解
问题定义:论文旨在解决在真实足球模拟游戏中,如何高效地训练出行为更像人类的守门员AI的问题。现有方法通常需要大量数据和计算资源来训练超人级别的AI,这对于游戏公司来说成本过高,并且训练出的AI行为模式与人类差异较大,影响游戏体验。
核心思路:论文的核心思路是通过提高深度强化学习的样本效率,从而在有限的资源下训练出类人AI。具体来说,通过利用预收集的数据进行预训练,以及增加神经网络的可塑性,使得智能体能够更快地学习到有效的策略。
技术框架:整体框架包括以下几个阶段:1) 预收集人类玩家的守门员数据;2) 使用预收集的数据对深度强化学习模型进行预训练;3) 在游戏环境中,使用改进的深度强化学习算法对模型进行微调;4) 通过领域专家的定性评估和定量指标来评估智能体的性能。
关键创新:论文的关键创新在于提出了一个样本高效的深度强化学习方法,该方法结合了预收集数据和增加网络可塑性两种技术。预收集数据可以提供有用的先验知识,加速学习过程;增加网络可塑性可以使得智能体更容易适应新的环境和任务。
关键设计:论文中使用了基于价值的深度强化学习算法,例如DQN。关键的设计包括:1) 使用预收集的数据进行行为克隆,初始化Q函数;2) 使用较小的神经网络结构,以提高训练速度和泛化能力;3) 设计合适的奖励函数,鼓励智能体做出符合人类直觉的动作;4) 使用经验回放和目标网络等技术来稳定训练过程。
🖼️ 关键图片


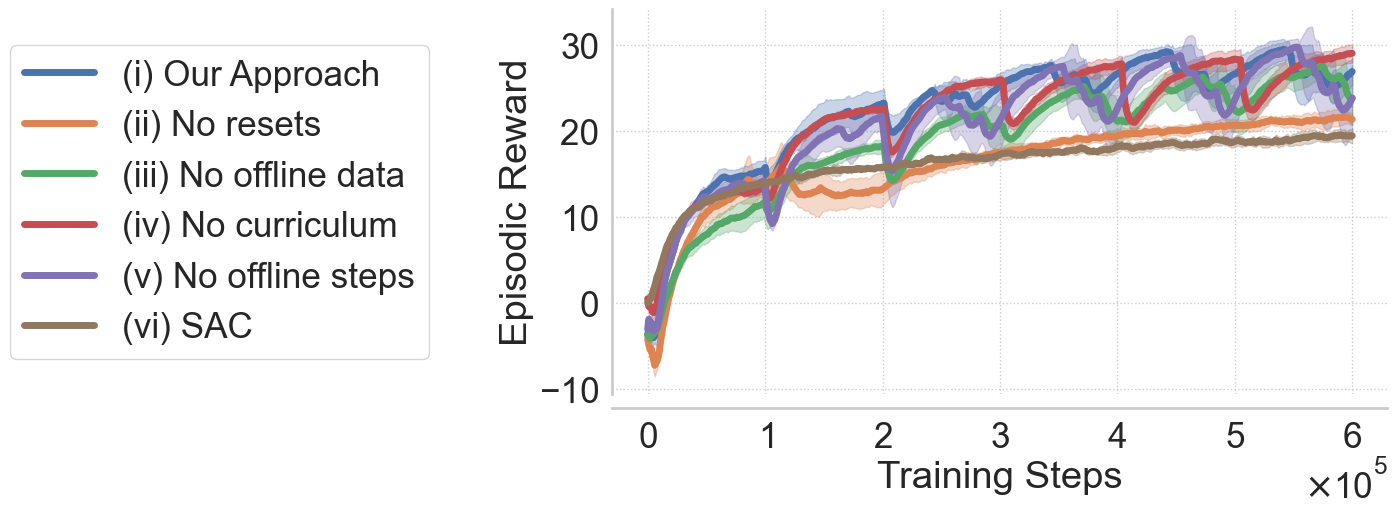
📊 实验亮点
实验结果表明,该方法训练的守门员AI在EA SPORTS FC 25中扑救率超过游戏内置AI 10%。消融研究表明,与标准DRL方法相比,该方法的训练速度提高了50%。领域专家的定性评估也表明,该方法创造的AI行为更像人类,游戏体验更佳。该方法已被应用于EA SPORTS FC系列的最新版本。
🎯 应用场景
该研究成果可应用于各种需要类人AI的游戏场景,例如体育游戏、角色扮演游戏等。通过该方法,游戏开发者可以更高效地创建出行为更自然、更符合玩家预期的AI角色,从而提升游戏的沉浸感和趣味性。此外,该方法也可以推广到其他需要人机协作的领域,例如机器人控制、自动驾驶等。
📄 摘要(原文)
While several high profile video games have served as testbeds for Deep Reinforcement Learning (DRL), this technique has rarely been employed by the game industry for crafting authentic AI behaviors. Previous research focuses on training super-human agents with large models, which is impractical for game studios with limited resources aiming for human-like agents. This paper proposes a sample-efficient DRL method tailored for training and fine-tuning agents in industrial settings such as the video game industry. Our method improves sample efficiency of value-based DRL by leveraging pre-collected data and increasing network plasticity. We evaluate our method training a goalkeeper agent in EA SPORTS FC 25, one of the best-selling football simulations today. Our agent outperforms the game's built-in AI by 10% in ball saving rate. Ablation studies show that our method trains agents 50% faster compared to standard DRL methods. Finally, qualitative evaluation from domain experts indicates that our approach creates more human-like gameplay compared to hand-crafted agents. As a testament to the impact of the approach, the method has been adopted for use in the most recent release of the series.