Guiding Skill Discovery with Foundation Models
作者: Zhao Yang, Thomas M. Moerland, Mike Preuss, Aske Plaat, Vincent François-Lavet, Edward S. Hu
分类: cs.AI
发布日期: 2025-10-27
💡 一句话要点
提出FoG方法,利用Foundation模型引导技能发现,避免不期望行为。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 技能发现 强化学习 Foundation模型 人类意图 奖励重塑
📋 核心要点
- 现有技能发现方法只关注技能多样性,忽略人类偏好,导致产生不期望甚至危险的行为。
- FoG方法利用Foundation模型提取评分函数,根据人类意图对状态进行评估并重塑技能发现奖励。
- 实验表明,FoG能有效消除不期望行为,避免危险区域,并发现难以定义的行为技能。
📝 摘要(中文)
在下游任务中,无需手动设计的奖励函数即可学习多样化技能,这可以加速强化学习。然而,现有的技能发现方法仅关注最大化技能的多样性,而忽略了人类的偏好,这导致了不良行为,甚至可能产生危险的技能。例如,使用先前方法训练的猎豹机器人学会向各个方向翻滚以最大化技能多样性,但我们更希望它跑步,而不是翻转或进入危险区域。本文提出了一种Foundation模型引导(FoG)的技能发现方法,该方法通过Foundation模型将人类意图融入技能发现中。具体而言,FoG从Foundation模型中提取一个评分函数,以根据人类意图评估状态,对期望的状态赋予更高的值,对不期望的状态赋予更低的值。然后,这些分数用于重新加权技能发现算法的奖励。通过优化重新加权的技能发现奖励,FoG成功地消除了不期望的行为,例如翻转或滚动,并避免了基于状态和基于像素的任务中的危险区域。有趣的是,我们表明FoG可以发现涉及难以定义的行为的技能。
🔬 方法详解
问题定义:现有的技能发现方法主要关注最大化技能的多样性,而忽略了人类的偏好和意图。这导致学习到的技能可能包含不期望的行为,例如机器人翻滚或进入危险区域,从而限制了其在实际应用中的价值。因此,需要一种方法能够在技能发现过程中融入人类的意图,引导学习过程朝着期望的方向发展。
核心思路:FoG的核心思路是利用预训练的Foundation模型来评估环境状态,并根据人类的意图对状态进行评分。这些评分被用来重新加权技能发现算法的奖励函数,从而引导智能体学习更符合人类期望的技能。通过这种方式,FoG能够有效地避免不期望的行为,并发现更有用的技能。
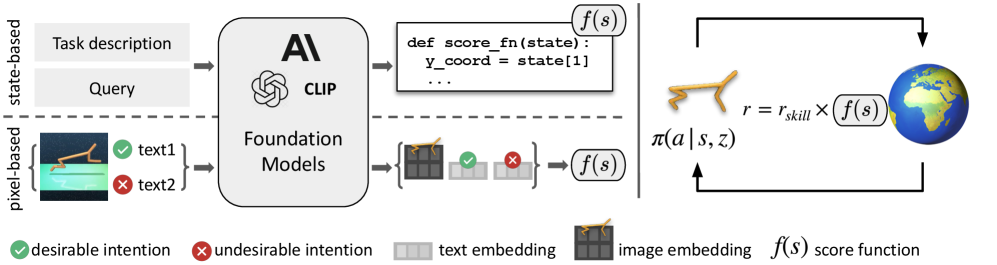
技术框架:FoG方法主要包含以下几个阶段:1) 使用现有的技能发现算法(例如DADS)生成初始技能;2) 利用Foundation模型(例如CLIP)提取环境状态的特征,并根据人类的意图对状态进行评分;3) 使用评分函数重新加权技能发现算法的奖励函数;4) 使用强化学习算法优化重加权后的奖励函数,从而学习更符合人类期望的技能。
关键创新:FoG的关键创新在于将Foundation模型引入到技能发现过程中,从而能够有效地融入人类的意图。与传统的技能发现方法相比,FoG不需要手动设计复杂的奖励函数,而是通过Foundation模型自动学习状态的价值,从而简化了技能发现的过程。此外,FoG还能够发现涉及难以定义的行为的技能,这为解决复杂的强化学习问题提供了新的思路。
关键设计:FoG的关键设计包括:1) 如何选择合适的Foundation模型来提取环境状态的特征;2) 如何设计评分函数来评估状态的价值;3) 如何将评分函数融入到技能发现算法的奖励函数中。论文中使用了CLIP模型来提取图像特征,并使用线性函数将特征映射到评分。奖励函数的重加权方式为将原始奖励与评分函数相加,并通过超参数控制评分函数的影响程度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FoG方法在猎豹跑步任务中能够有效地避免翻滚等不期望行为,并成功地避免了危险区域。在基于像素的任务中,FoG也能够学习到更符合人类期望的技能。与传统的技能发现方法相比,FoG在多个任务中都取得了显著的性能提升,证明了其有效性和泛化能力。
🎯 应用场景
FoG方法可应用于机器人控制、游戏AI等领域,尤其适用于需要安全性和可控性的场景。例如,可以训练机器人完成复杂的任务,同时避免进入危险区域或执行不期望的动作。该方法还可以用于生成更符合人类偏好的游戏AI,提升游戏体验。未来,FoG有望成为一种通用的技能发现方法,加速强化学习在各个领域的应用。
📄 摘要(原文)
Learning diverse skills without hand-crafted reward functions could accelerate reinforcement learning in downstream tasks. However, existing skill discovery methods focus solely on maximizing the diversity of skills without considering human preferences, which leads to undesirable behaviors and possibly dangerous skills. For instance, a cheetah robot trained using previous methods learns to roll in all directions to maximize skill diversity, whereas we would prefer it to run without flipping or entering hazardous areas. In this work, we propose a Foundation model Guided (FoG) skill discovery method, which incorporates human intentions into skill discovery through foundation models. Specifically, FoG extracts a score function from foundation models to evaluate states based on human intentions, assigning higher values to desirable states and lower to undesirable ones. These scores are then used to re-weight the rewards of skill discovery algorithms. By optimizing the re-weighted skill discovery rewards, FoG successfully learns to eliminate undesirable behaviors, such as flipping or rolling, and to avoid hazardous areas in both state-based and pixel-based tasks. Interestingly, we show that FoG can discover skills involving behaviors that are difficult to define. Interactive visualisations are available from https://sites.google.com/view/submission-fog.