Think before Recommendation: Autonomous Reasoning-enhanced Recommender
作者: Xiaoyu Kong, Junguang Jiang, Bin Liu, Ziru Xu, Han Zhu, Jian Xu, Bo Zheng, Jiancan Wu, Xiang Wang
分类: cs.IR, cs.AI
发布日期: 2025-10-27
备注: NeurIPS 2025 poster
💡 一句话要点
RecZero:提出基于强化学习的自主推理增强推荐系统,摆脱传统蒸馏范式。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推荐系统 大型语言模型 强化学习 自主推理 评分预测
📋 核心要点
- 现有基于蒸馏的推荐方法存在教师模型能力不足、监督成本高、推理能力传递不充分等问题。
- RecZero提出一种基于强化学习的推荐范式,通过纯RL训练单个LLM,使其自主学习推理能力。
- 实验结果表明,RecZero和RecOne在多个数据集上显著优于现有方法,验证了RL范式的有效性。
📝 摘要(中文)
推荐系统的核心任务是从历史用户-物品交互中学习用户偏好。随着大型语言模型(LLMs)的快速发展,最近的研究探索了利用LLMs的推理能力来增强评分预测任务。然而,现有的基于蒸馏的方法存在教师模型推荐能力不足、监督成本高昂且静态、以及推理能力传递肤浅等局限性。为了解决这些问题,本文提出RecZero,一种基于强化学习(RL)的推荐范式,它放弃了传统的多模型和多阶段蒸馏方法。相反,RecZero通过纯RL训练单个LLM,以自主开发用于评分预测的推理能力。RecZero由两个关键组件组成:(1)“推荐前思考”提示构建,它采用结构化的推理模板来指导模型逐步分析用户兴趣、物品特征和用户-物品兼容性;(2)基于规则的奖励建模,它采用群体相对策略优化(GRPO)来计算推理轨迹的奖励并优化LLM。此外,本文还探索了一种混合范式RecOne,它将监督微调与RL相结合,使用冷启动推理样本初始化模型,并通过RL进一步优化。实验结果表明,RecZero和RecOne在多个基准数据集上显著优于现有的基线方法,验证了RL范式在实现自主推理增强推荐系统方面的优越性。
🔬 方法详解
问题定义:论文旨在解决现有基于蒸馏的推荐方法的不足,这些方法依赖于教师模型,存在推荐能力有限、监督信号静态且成本高昂、以及推理能力传递不充分的问题。这些问题限制了LLM在推荐系统中的应用潜力。
核心思路:论文的核心思路是放弃传统的蒸馏范式,转而采用强化学习(RL)来训练单个LLM,使其能够自主地学习推理能力,从而进行更准确的评分预测。通过RL,模型可以根据自身的行为和环境反馈来不断优化推理策略,避免了对教师模型的依赖和静态监督的限制。
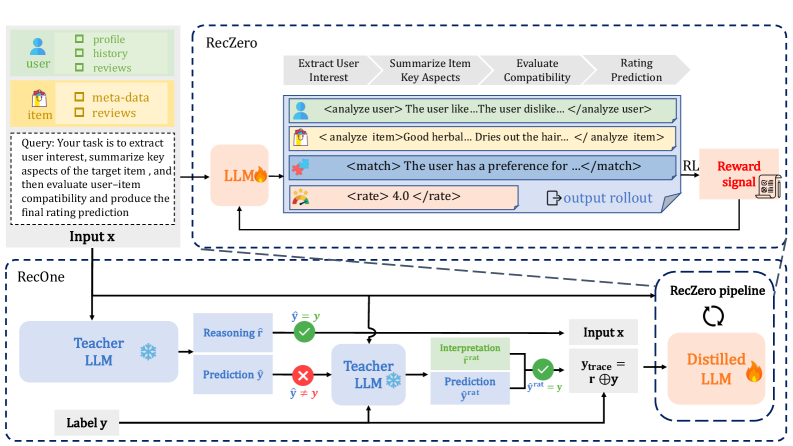
技术框架:RecZero的技术框架主要包含两个关键组件:(1)“推荐前思考”提示构建:利用结构化的推理模板,引导LLM逐步分析用户兴趣、物品特征以及用户-物品的兼容性,从而进行更深入的推理。(2)基于规则的奖励建模:采用群体相对策略优化(GRPO)来计算推理轨迹的奖励,并利用这些奖励来优化LLM。此外,论文还提出了RecOne,一种混合范式,它结合了监督微调和RL,首先使用冷启动推理样本初始化模型,然后通过RL进行进一步优化。
关键创新:论文最重要的技术创新点在于提出了基于强化学习的自主推理增强推荐范式,摆脱了对教师模型的依赖,使LLM能够自主地学习推理能力。与现有方法相比,RecZero能够更有效地利用LLM的潜力,实现更准确的评分预测。
关键设计:在“推荐前思考”提示构建中,论文设计了结构化的推理模板,引导模型进行多步骤的分析。在奖励建模中,采用了群体相对策略优化(GRPO),通过比较不同推理轨迹的质量来计算奖励,从而更有效地优化LLM。具体的参数设置和网络结构细节在论文中进行了详细描述,但此处未提供具体数值。
🖼️ 关键图片

📊 实验亮点
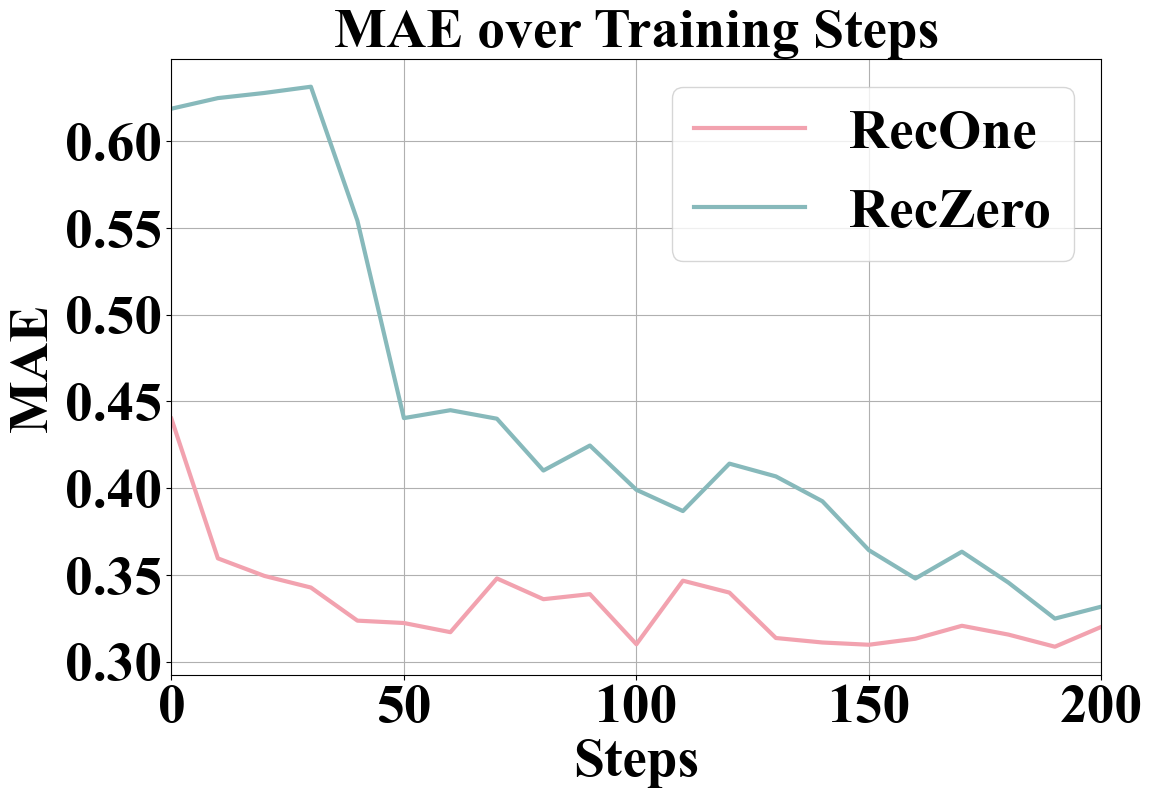
实验结果表明,RecZero和RecOne在多个基准数据集上显著优于现有的基线方法。例如,在某些数据集上,RecZero的性能提升超过了10%。这些结果验证了RL范式在实现自主推理增强推荐系统方面的优越性,并表明该方法具有很强的实际应用潜力。
🎯 应用场景
该研究成果可应用于各种推荐系统场景,例如电商、电影、音乐等。通过提升推荐系统的准确性和个性化程度,可以提高用户满意度和平台收益。此外,该研究也为其他需要利用LLM进行推理的任务提供了新的思路和方法。
📄 摘要(原文)
The core task of recommender systems is to learn user preferences from historical user-item interactions. With the rapid development of large language models (LLMs), recent research has explored leveraging the reasoning capabilities of LLMs to enhance rating prediction tasks. However, existing distillation-based methods suffer from limitations such as the teacher model's insufficient recommendation capability, costly and static supervision, and superficial transfer of reasoning ability. To address these issues, this paper proposes RecZero, a reinforcement learning (RL)-based recommendation paradigm that abandons the traditional multi-model and multi-stage distillation approach. Instead, RecZero trains a single LLM through pure RL to autonomously develop reasoning capabilities for rating prediction. RecZero consists of two key components: (1) "Think-before-Recommendation" prompt construction, which employs a structured reasoning template to guide the model in step-wise analysis of user interests, item features, and user-item compatibility; and (2) rule-based reward modeling, which adopts group relative policy optimization (GRPO) to compute rewards for reasoning trajectories and optimize the LLM. Additionally, the paper explores a hybrid paradigm, RecOne, which combines supervised fine-tuning with RL, initializing the model with cold-start reasoning samples and further optimizing it with RL. Experimental results demonstrate that RecZero and RecOne significantly outperform existing baseline methods on multiple benchmark datasets, validating the superiority of the RL paradigm in achieving autonomous reasoning-enhanced recommender systems.