Efficient and Encrypted Inference using Binarized Neural Networks within In-Memory Computing Architectures
作者: Gokulnath Rajendran, Suman Deb, Anupam Chattopadhyay
分类: cs.CR, cs.AI
发布日期: 2025-10-27
备注: to be published in: 7th International Conference on Emerging Electronics (ICEE 2025)
💡 一句话要点
提出一种基于PUF密钥的BNN加密推理方法,用于内存计算架构的安全加速。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 二值化神经网络 内存计算 物理不可克隆函数 模型安全 加密推理
📋 核心要点
- 现有内存计算架构中,BNN模型参数的加密存储和运行时解密引入了显著的计算开销,抵消了内存计算的优势。
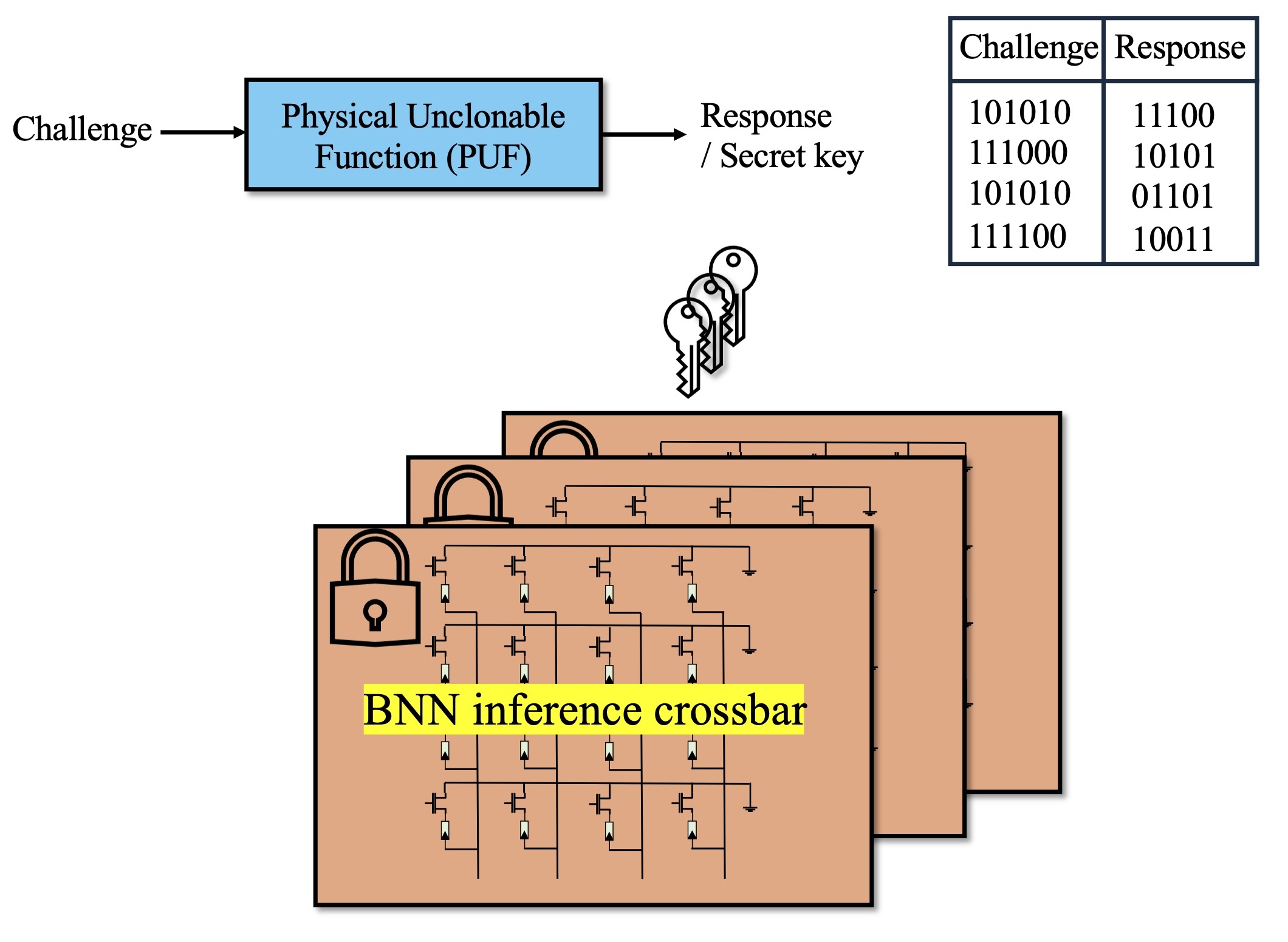
- 该论文提出一种基于物理不可克隆函数(PUF)密钥的加密方法,在加密域直接进行BNN推理,降低运行时开销。
- 实验结果表明,该方法在保护BNN模型参数的同时,保持了较高的计算效率,无密钥推理准确率低于15%。
📝 摘要(中文)
二值化神经网络(BNNs)是一类旨在利用最少计算资源的深度神经网络,这推动了它们在各种应用中的普及。最近的研究强调了将BNN模型参数映射到新兴非易失性存储技术的潜力,特别是使用交叉开关架构,与传统的CMOS实现相比,可以提高推理性能。然而,通过以加密格式存储模型参数并在运行时解密来保护模型参数免受盗窃攻击的常见做法会带来显著的计算开销,从而破坏了旨在集成计算和存储的内存计算的核心原则。本文提出了一种强大的策略来保护BNN模型参数,特别是在内存计算框架中。我们的方法利用从物理不可克隆函数导出的密钥来转换存储在交叉开关中的模型参数。随后,在加密的权重上执行推理操作,实现了一种非常特殊的完全同态加密(FHE),且运行时开销极小。我们的分析表明,在没有密钥的情况下进行推理会导致性能急剧下降,准确率降至15%以下。这些结果验证了我们的保护策略在内存计算架构中保护BNN的同时保持计算效率的有效性。
🔬 方法详解
问题定义:论文旨在解决在内存计算架构中,二值化神经网络(BNN)模型参数的安全存储和高效推理问题。现有方法通常采用加密存储和运行时解密的方式保护模型参数,但解密过程引入了额外的计算开销,降低了内存计算的效率优势。因此,如何在保护模型安全的同时,避免额外的解密开销是本论文要解决的核心问题。
核心思路:论文的核心思路是在加密域直接进行BNN的推理计算,避免运行时解密。具体而言,利用物理不可克隆函数(PUF)生成密钥,对BNN的模型参数进行加密转换,使得推理过程可以直接在加密后的参数上进行。这种方法类似于一种特殊的完全同态加密(FHE),但具有更低的计算复杂度。
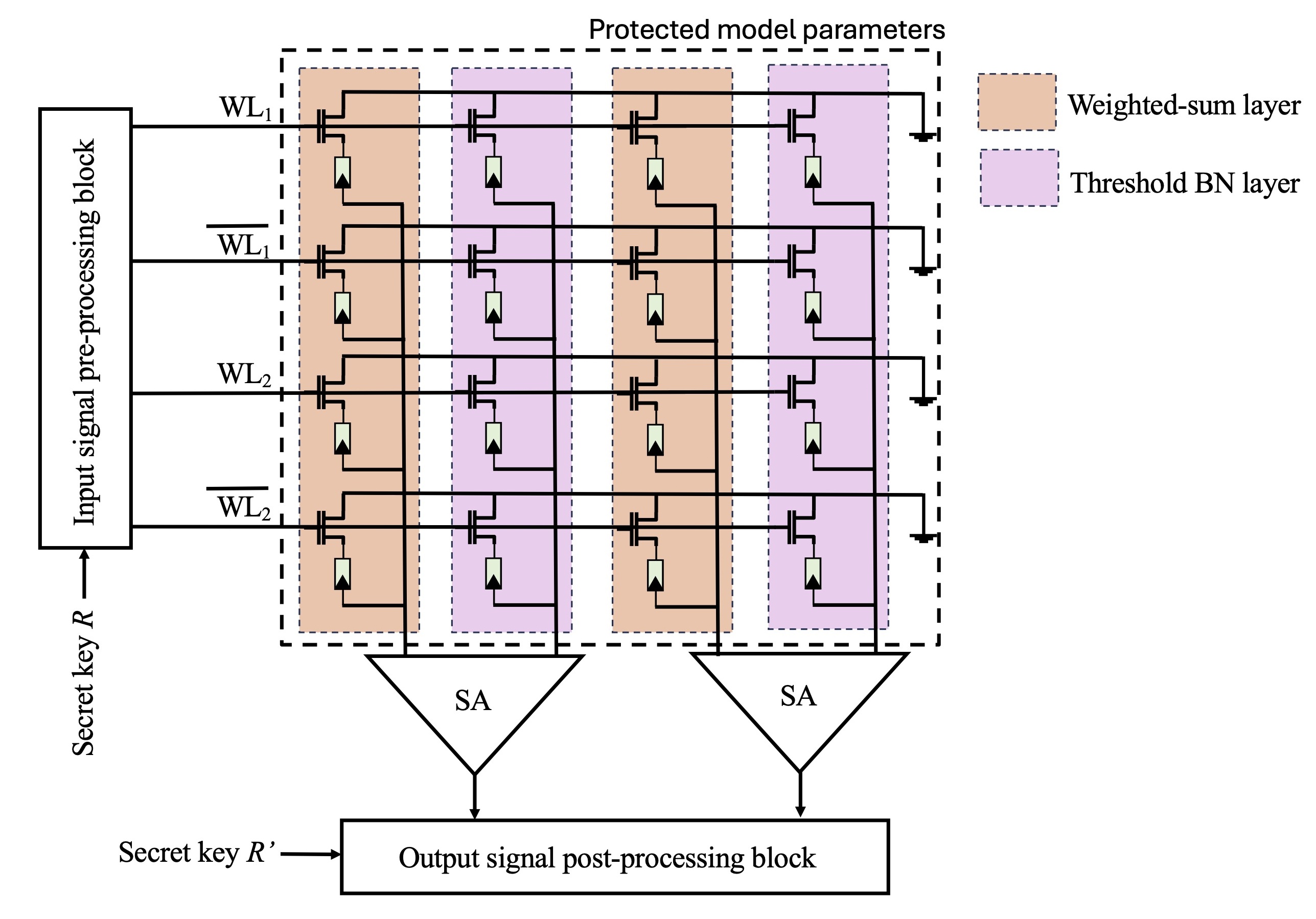
技术框架:该方法主要包含以下几个阶段:1) 使用PUF生成密钥;2) 使用密钥对BNN模型参数进行加密转换;3) 将加密后的模型参数存储在交叉开关架构的非易失性存储器中;4) 在加密的权重上直接进行推理计算。整个框架的关键在于加密转换的设计,需要保证推理计算在加密域的正确性。
关键创新:该论文的关键创新在于提出了一种基于PUF密钥的轻量级加密方案,能够在内存计算架构中实现BNN的安全高效推理。与传统的加密方法相比,该方法避免了运行时的解密操作,从而显著降低了计算开销。此外,利用PUF生成密钥,提高了密钥的安全性,防止模型被非法访问。
关键设计:论文中关键的设计在于如何利用PUF密钥对BNN的二值化权重进行转换,并保证转换后的权重仍然可以进行有效的推理计算。具体的转换方式和数学原理在论文中应该有详细的描述(未知)。此外,交叉开关架构的具体参数设置,例如电阻值等,也会影响推理的精度和效率(未知)。
🖼️ 关键图片

📊 实验亮点
该论文的主要实验结果表明,在没有密钥的情况下进行推理会导致性能急剧下降,准确率降至15%以下。这验证了所提出的保护策略在保护BNN模型参数方面的有效性。同时,该方法在保持计算效率方面也表现良好,与传统的加密方法相比,显著降低了计算开销。具体的性能数据和对比基线需要在论文中进一步查找(未知)。
🎯 应用场景
该研究成果可应用于各种资源受限的边缘设备和物联网应用中,例如智能传感器、可穿戴设备和移动设备。通过在内存计算架构中安全高效地部署BNN,可以实现本地化的智能分析,降低对云端服务器的依赖,提高数据隐私和安全性。此外,该方法还可以应用于对安全性要求较高的场景,例如金融交易和身份认证。
📄 摘要(原文)
Binarized Neural Networks (BNNs) are a class of deep neural networks designed to utilize minimal computational resources, which drives their popularity across various applications. Recent studies highlight the potential of mapping BNN model parameters onto emerging non-volatile memory technologies, specifically using crossbar architectures, resulting in improved inference performance compared to traditional CMOS implementations. However, the common practice of protecting model parameters from theft attacks by storing them in an encrypted format and decrypting them at runtime introduces significant computational overhead, thus undermining the core principles of in-memory computing, which aim to integrate computation and storage. This paper presents a robust strategy for protecting BNN model parameters, particularly within in-memory computing frameworks. Our method utilizes a secret key derived from a physical unclonable function to transform model parameters prior to storage in the crossbar. Subsequently, the inference operations are performed on the encrypted weights, achieving a very special case of Fully Homomorphic Encryption (FHE) with minimal runtime overhead. Our analysis reveals that inference conducted without the secret key results in drastically diminished performance, with accuracy falling below 15%. These results validate the effectiveness of our protection strategy in securing BNNs within in-memory computing architectures while preserving computational efficiency.