USF-MAE: Ultrasound Self-Supervised Foundation Model with Masked Autoencoding
作者: Youssef Megahed, Robin Ducharme, Aylin Erman, Mark Walker, Steven Hawken, Adrian D. C. Chan
分类: eess.IV, cs.AI, cs.CV
发布日期: 2025-10-27 (更新: 2025-11-07)
备注: 18 pages, 8 figures, 2 tables
💡 一句话要点
USF-MAE:基于掩码自编码器的超声自监督预训练模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超声图像 自监督学习 掩码自编码器 Vision Transformer 医学影像分析
📋 核心要点
- 现有深度学习方法受限于缺乏大型标注超声数据集,以及通用图像和超声图像之间的领域差距,导致模型迁移能力受限。
- USF-MAE通过掩码自编码器在大量未标注超声数据上进行预训练,学习特定于超声模态的表征,从而提升模型性能。
- 实验表明,USF-MAE在多个超声图像分类任务中优于传统CNN和ViT模型,并展现出良好的跨解剖区域泛化能力。
📝 摘要(中文)
本文提出了一种基于掩码自编码器的超声自监督基础模型USF-MAE,这是首个完全基于超声数据进行大规模自监督MAE预训练的框架。该模型使用来自46个开源数据集(OpenUS-46)的37万张2D和3D超声图像进行预训练,这些数据涵盖了20多个解剖区域,并已公开以促进研究和可重复性。USF-MAE采用Vision Transformer编码器-解码器架构,通过重建被掩盖的图像块,直接从无标签数据中学习丰富的、特定于模态的表征。预训练的编码器在三个公共下游分类基准(BUS-BRA、MMOTU-2D和GIST514-DB)上进行了微调。在所有任务中,USF-MAE始终优于传统的CNN和ViT基线,分别实现了81.6%、79.6%和82.4%的F1分数。尽管在预训练期间未使用标签,但USF-MAE在乳腺癌分类方面接近了有监督的基础模型UltraSam的性能,并在其他任务上超过了它,展示了强大的跨解剖泛化能力。
🔬 方法详解
问题定义:论文旨在解决超声图像分析中,由于缺乏大规模标注数据和领域迁移性差导致的深度学习模型性能瓶颈问题。现有方法在处理超声图像时,往往受到噪声大、操作者依赖性强、视野有限等因素的影响,导致诊断结果存在较大的观察者间差异。
核心思路:论文的核心思路是利用自监督学习方法,通过掩码自编码器(MAE)在大量未标注的超声图像数据上进行预训练,从而学习到特定于超声模态的、鲁棒的图像表征。这种方法避免了对大量标注数据的依赖,并能有效提升模型在下游任务中的泛化能力。
技术框架:USF-MAE的整体架构是一个基于Vision Transformer(ViT)的编码器-解码器结构。首先,输入超声图像被分割成多个图像块(patches),然后随机掩盖掉一部分图像块。编码器负责提取未被掩盖的图像块的特征表示。解码器则利用编码器的输出,重建被掩盖的图像块。通过最小化重建误差,模型学习到图像的内在结构和特征。预训练完成后,将编码器部分迁移到下游任务中进行微调。
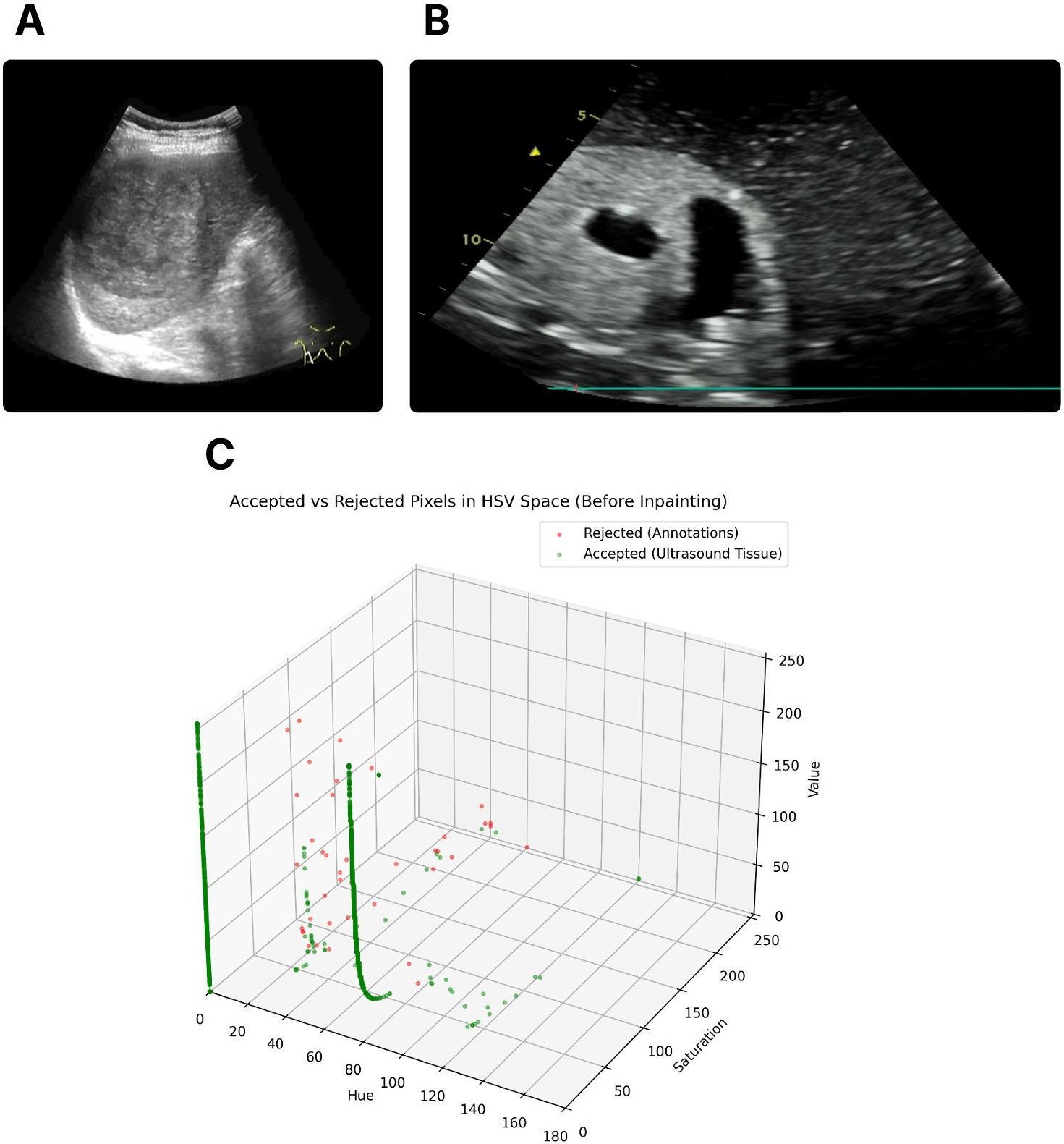
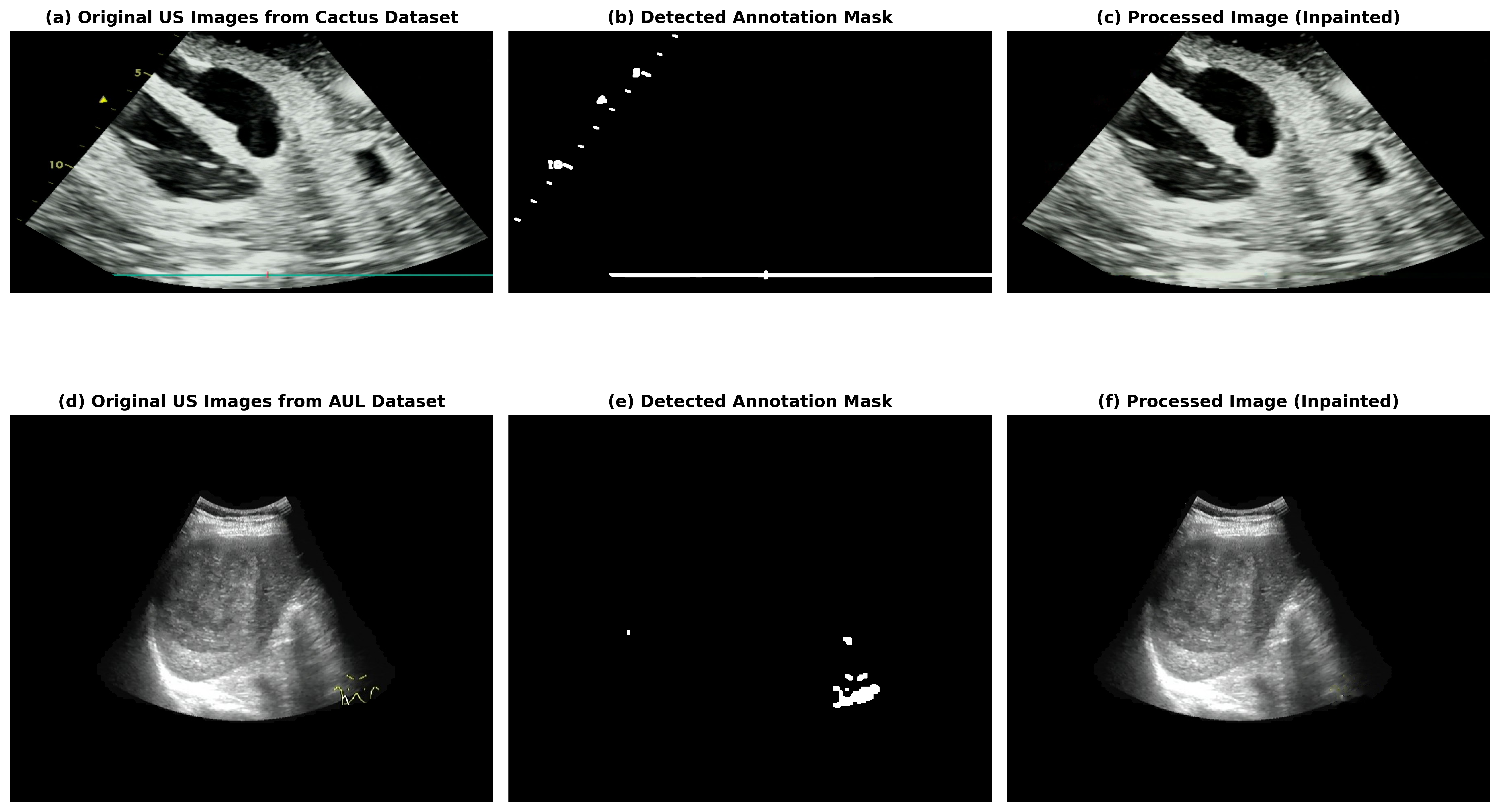
关键创新:最重要的技术创新点在于,USF-MAE是首个完全基于超声数据进行大规模自监督MAE预训练的框架。与以往使用通用图像数据进行预训练的方法相比,USF-MAE能够更好地适应超声图像的特点,学习到更具判别性的特征表示。此外,论文还构建了一个包含46个开源超声数据集的大规模数据集OpenUS-46,为后续研究提供了便利。
关键设计:USF-MAE采用了标准的ViT架构,并针对超声图像的特点进行了一些调整。例如,论文使用了相对较大的掩码比例(例如,75%),以迫使模型学习更全局的图像上下文信息。损失函数采用均方误差(MSE),用于衡量重建图像块与原始图像块之间的差异。在下游任务微调时,使用了AdamW优化器,并设置了合适的学习率和权重衰减系数。
🖼️ 关键图片

📊 实验亮点
USF-MAE在三个公共下游分类基准(BUS-BRA、MMOTU-2D和GIST514-DB)上进行了评估,结果表明,USF-MAE始终优于传统的CNN和ViT基线,分别实现了81.6%、79.6%和82.4%的F1分数。在乳腺癌分类方面,USF-MAE的性能接近了有监督的基础模型UltraSam,并在其他任务上超过了它,展示了强大的跨解剖泛化能力。
🎯 应用场景
USF-MAE在医学影像诊断领域具有广泛的应用前景,可用于辅助医生进行乳腺癌、卵巢肿瘤、胃肠道间质瘤等疾病的诊断。通过提升超声图像分析的准确性和效率,该研究有助于改善患者的诊断和治疗效果,并降低医疗成本。未来,该模型有望扩展到其他医学影像模态,并应用于更复杂的临床场景。
📄 摘要(原文)
Ultrasound imaging is one of the most widely used diagnostic modalities, offering real-time, radiation-free assessment across diverse clinical domains. However, interpretation of ultrasound images remains challenging due to high noise levels, operator dependence, and limited field of view, resulting in substantial inter-observer variability. Current Deep Learning approaches are hindered by the scarcity of large labeled datasets and the domain gap between general and sonographic images, which limits the transferability of models pretrained on non-medical data. To address these challenges, we introduce the Ultrasound Self-Supervised Foundation Model with Masked Autoencoding (USF-MAE), the first large-scale self-supervised MAE framework pretrained exclusively on ultrasound data. The model was pre-trained on 370,000 2D and 3D ultrasound images curated from 46 open-source datasets, collectively termed OpenUS-46, spanning over twenty anatomical regions. This curated dataset has been made publicly available to facilitate further research and reproducibility. Using a Vision Transformer encoder-decoder architecture, USF-MAE reconstructs masked image patches, enabling it to learn rich, modality-specific representations directly from unlabeled data. The pretrained encoder was fine-tuned on three public downstream classification benchmarks: BUS-BRA (breast cancer), MMOTU-2D (ovarian tumors), and GIST514-DB (gastrointestinal stromal tumors). Across all tasks, USF-MAE consistently outperformed conventional CNN and ViT baselines, achieving F1-scores of 81.6%, 79.6%, and 82.4%, respectively. Despite not using labels during pretraining, USF-MAE approached the performance of the supervised foundation model UltraSam on breast cancer classification and surpassed it on the other tasks, demonstrating strong cross-anatomical generalization.