Chitchat with AI: Understand the supply chain carbon disclosure of companies worldwide through Large Language Model
作者: Haotian Hang, Yueyang Shen, Vicky Zhu, Jose Cruz, Michelle Li
分类: cs.CY, cs.AI, cs.CL, cs.LG, stat.AP
发布日期: 2025-10-26
💡 一句话要点
提出基于LLM的企业碳排放披露质量评估框架,实现跨行业、跨国别对标。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 碳排放披露 大型语言模型 ESG 气候治理 决策支持系统
📋 核心要点
- 企业碳排放披露数据异构且非结构化,难以进行有效分析和跨公司比较。
- 利用大型语言模型,构建统一的评分体系,对企业碳排放披露质量进行量化评估。
- 实验结果揭示了不同行业和国家在碳排放披露质量上的差异,为决策提供依据。
📝 摘要(中文)
在全球可持续发展背景下,企业碳排放披露已成为企业战略与环境责任对齐的关键机制。碳披露项目(CDP)拥有全球最大的气候相关调查回复纵向数据集,包含结构化指标和开放式叙述,但这些披露的异构性和自由形式给基准测试、合规监控和投资筛选带来了重大分析挑战。本文提出了一种新的决策支持框架,利用大型语言模型(LLM)大规模评估企业气候披露质量。该框架开发了一个主标尺,协调了11年(2010-2020)CDP数据的叙述评分,实现了跨行业和跨国别的基准测试。通过将标尺引导的评分与基于百分比的归一化相结合,该方法识别了行业和区域间的披露的时间趋势、战略对齐模式和不一致性。结果表明,技术等行业和德国等国家始终表现出更高的标尺对齐度,而其他行业和国家则表现出波动或表面参与,为投资者、监管机构和企业环境、社会和治理(ESG)战略家提供了关键决策过程的信息。所提出的基于LLM的方法将非结构化披露转化为可量化、可解释、可比较和可操作的情报,从而提升了人工智能决策支持系统(DSS)在气候治理领域的能力。
🔬 方法详解
问题定义:论文旨在解决企业碳排放披露数据分析的难题。现有方法难以有效处理CDP数据的异构性和非结构化特点,导致无法进行准确的基准测试、合规监控和投资筛选。现有方法的痛点在于无法将大量的非结构化文本数据转化为可量化、可比较的信息,从而阻碍了对企业气候风险管理水平的有效评估。
核心思路:论文的核心思路是利用大型语言模型(LLM)的自然语言处理能力,将非结构化的碳排放披露文本转化为可量化的指标。通过构建一个统一的评分体系(master rubric),对企业披露的质量进行评估,并结合百分比归一化方法,实现跨行业和跨国别的比较。这样设计的目的是为了克服现有方法在处理异构数据方面的局限性,提供更全面、更客观的评估结果。
技术框架:整体框架包括以下几个主要阶段:1) 数据收集与预处理:收集CDP的碳排放披露数据,并进行清洗和格式化。2) 构建主标尺(Master Rubric):设计一个包含多个维度和评分标准的评分体系,用于评估披露质量。3) LLM评分:利用LLM对披露文本进行分析,并根据主标尺进行评分。4) 百分比归一化:将评分结果进行归一化处理,以便进行跨行业和跨国别的比较。5) 结果分析与可视化:对评分结果进行统计分析,并以可视化的方式呈现,为决策者提供参考。
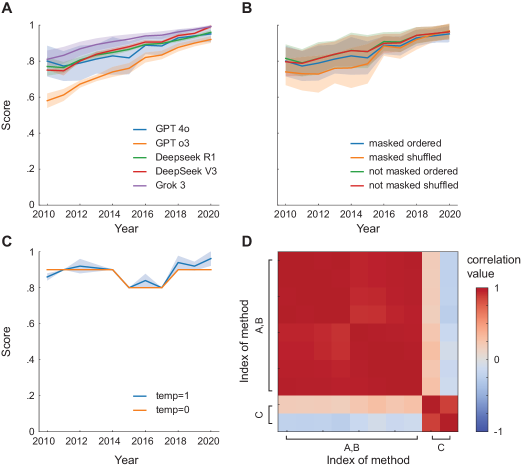
关键创新:最重要的技术创新点在于将大型语言模型应用于企业碳排放披露质量的评估。与传统的人工评估方法相比,LLM能够更高效、更客观地处理大量的文本数据,并提供更一致的评分结果。此外,主标尺的设计也为跨行业和跨国别的比较提供了统一的标准。
关键设计:主标尺的设计是关键的技术细节。它需要包含多个维度,例如披露的完整性、透明度、战略一致性等,并为每个维度定义清晰的评分标准。LLM的选择和训练也至关重要,需要选择具有较强自然语言理解能力的模型,并使用大量的碳排放披露数据进行训练,以提高评分的准确性。百分比归一化的方法也需要仔细设计,以确保不同行业和国家之间的评分具有可比性。
🖼️ 关键图片
📊 实验亮点
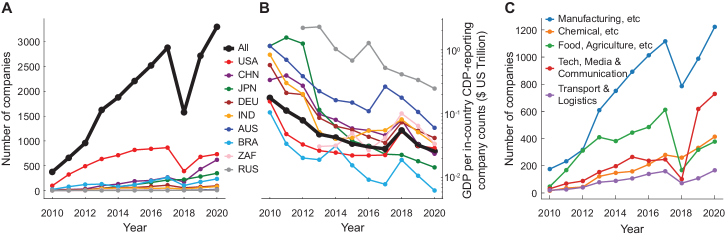
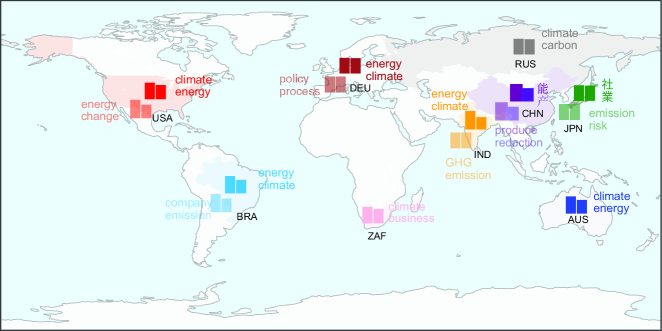
研究结果表明,技术等行业和德国等国家在碳排放披露质量方面表现突出,而其他行业和国家则存在改进空间。该框架能够识别企业披露中的时间趋势、战略对齐模式和不一致性,为投资者、监管机构和企业ESG战略家提供有价值的信息。通过将非结构化披露转化为可量化、可解释、可比较和可操作的情报,该研究提升了人工智能决策支持系统在气候治理领域的能力。
🎯 应用场景
该研究成果可应用于多个领域。投资者可以利用该框架评估企业的气候风险管理水平,并做出更明智的投资决策。监管机构可以利用该框架监控企业的碳排放披露情况,并评估其合规性。企业自身可以利用该框架识别自身在碳排放披露方面的不足,并改进其环境战略。未来,该框架可以扩展到其他ESG领域,例如社会责任和公司治理。
📄 摘要(原文)
In the context of global sustainability mandates, corporate carbon disclosure has emerged as a critical mechanism for aligning business strategy with environmental responsibility. The Carbon Disclosure Project (CDP) hosts the world's largest longitudinal dataset of climate-related survey responses, combining structured indicators with open-ended narratives, but the heterogeneity and free-form nature of these disclosures present significant analytical challenges for benchmarking, compliance monitoring, and investment screening. This paper proposes a novel decision-support framework that leverages large language models (LLMs) to assess corporate climate disclosure quality at scale. It develops a master rubric that harmonizes narrative scoring across 11 years of CDP data (2010-2020), enabling cross-sector and cross-country benchmarking. By integrating rubric-guided scoring with percentile-based normalization, our method identifies temporal trends, strategic alignment patterns, and inconsistencies in disclosure across industries and regions. Results reveal that sectors such as technology and countries like Germany consistently demonstrate higher rubric alignment, while others exhibit volatility or superficial engagement, offering insights that inform key decision-making processes for investors, regulators, and corporate environmental, social, and governance (ESG) strategists. The proposed LLM-based approach transforms unstructured disclosures into quantifiable, interpretable, comparable, and actionable intelligence, advancing the capabilities of AI-enabled decision support systems (DSSs) in the domain of climate governance.