Reasoning Models Reason Well, Until They Don't
作者: Revanth Rameshkumar, Jimson Huang, Yunxin Sun, Fei Xia, Abulhair Saparov
分类: cs.AI, cs.CL
发布日期: 2025-10-25
💡 一句话要点
揭示大规模推理模型在复杂推理任务中的局限性,并提出新的评估基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 复杂推理 数据集构建 泛化能力
📋 核心要点
- 现有研究表明,大型语言模型在复杂推理任务中表现不佳,缺乏泛化能力。
- 论文提出通过构建更复杂的推理数据集DeepRD,并分析模型在图连通性和自然语言证明规划上的表现来评估模型。
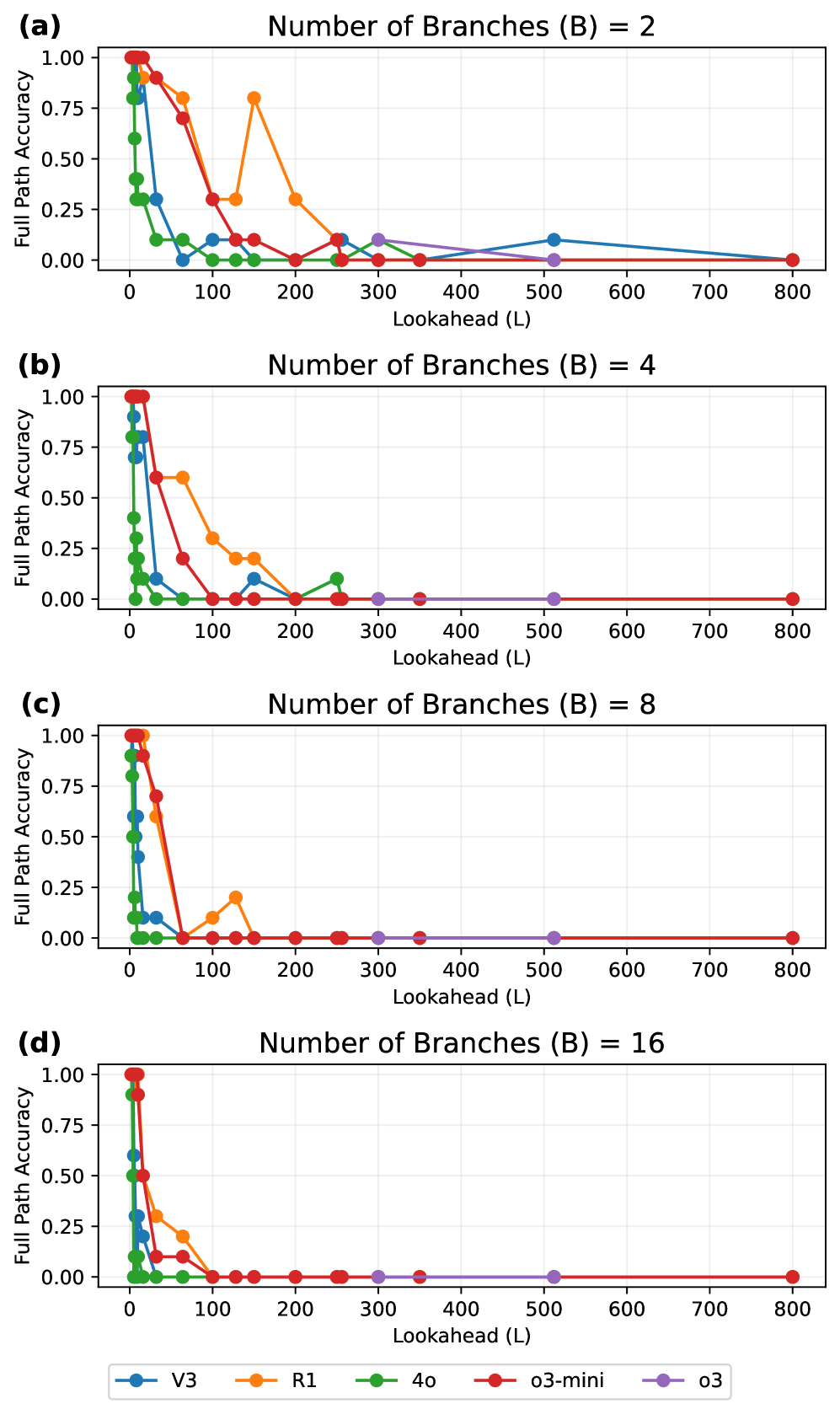
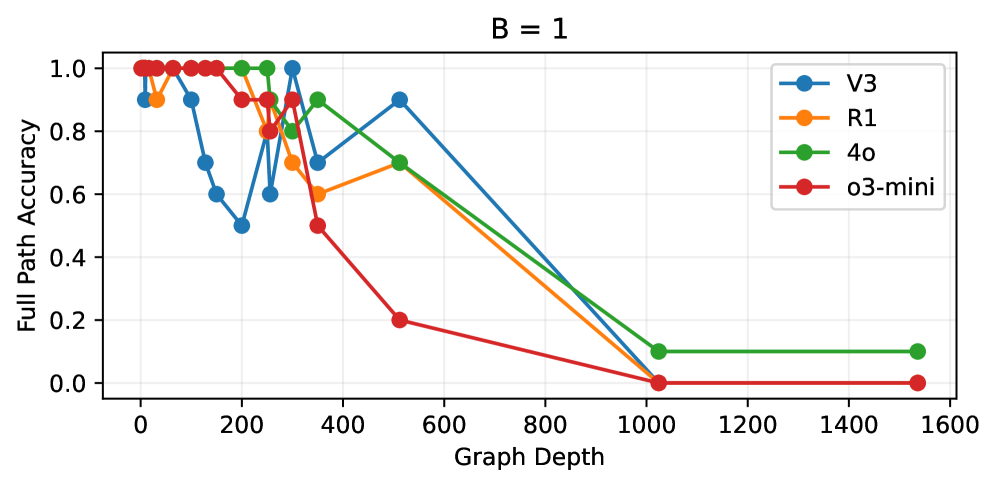
- 实验表明,大型推理模型在足够复杂的问题上性能急剧下降,无法很好地泛化到训练数据之外的复杂场景。
📝 摘要(中文)
大型语言模型(LLMs)在推理任务中取得了显著进展。然而,最近的研究表明,一旦推理问题的复杂度超过一定限度,transformers和LLMs就会彻底失败。本文通过大型推理模型(LRMs)的视角重新审视这些发现,LRMs是指经过微调,能够逐步论证和自我验证的LLMs。LRMs在图推理和NLGraph等推理基准测试中表现出色,甚至有人声称它们能够在数学、物理、医学和法律等推理密集型领域进行广义推理和创新。然而,通过更仔细地扩展推理问题的复杂性,我们表明现有的基准测试实际上具有有限的复杂性。我们开发了一个新的数据集,即深度推理数据集(DeepRD),以及一个用于生成无限数量的可扩展复杂性示例的生成过程。我们使用该数据集来评估模型在图连通性和自然语言证明规划方面的性能。我们发现,LRMs的性能在达到足够的复杂性时会突然下降,并且不能泛化。我们还将LRM结果与大型真实世界知识图、交互图和证明数据集的复杂性分布相关联。我们发现,大多数真实世界的例子都落在LRMs的成功范围内,但长尾暴露了巨大的失败潜力。我们的分析强调了LRMs的近期效用,同时强调了对新方法的需求,这些方法可以推广到训练分布中示例的复杂性之外。
🔬 方法详解
问题定义:现有的大型语言模型在推理任务中表现出一定的能力,但在面对复杂度较高的推理问题时,性能会急剧下降,缺乏泛化能力。现有的推理基准数据集的复杂度有限,无法充分评估模型的推理能力。
核心思路:论文的核心思路是通过构建一个具有可控复杂度的深度推理数据集(DeepRD),来更全面地评估大型推理模型(LRMs)在复杂推理任务中的性能。通过分析模型在不同复杂度问题上的表现,揭示其泛化能力的局限性。
技术框架:论文主要包含以下几个部分:1) 分析现有推理基准的局限性;2) 提出DeepRD数据集,并设计生成过程以控制数据集的复杂度;3) 使用DeepRD评估LRMs在图连通性和自然语言证明规划任务上的性能;4) 将LRM的性能与真实世界知识图的复杂性分布进行比较。
关键创新:论文的关键创新在于提出了DeepRD数据集,该数据集具有可控的复杂性,能够更有效地评估模型的推理能力。此外,论文还分析了LRMs在复杂推理任务中的失败模式,并将其与真实世界数据的复杂性分布联系起来,为未来的研究方向提供了启示。
关键设计:DeepRD数据集的生成过程允许控制图的规模、连接密度以及证明链的长度等参数,从而实现对推理问题复杂度的精确控制。论文使用图连通性判断和自然语言证明规划作为评估任务,并选择了经过微调的LLMs作为LRMs进行实验。
🖼️ 关键图片
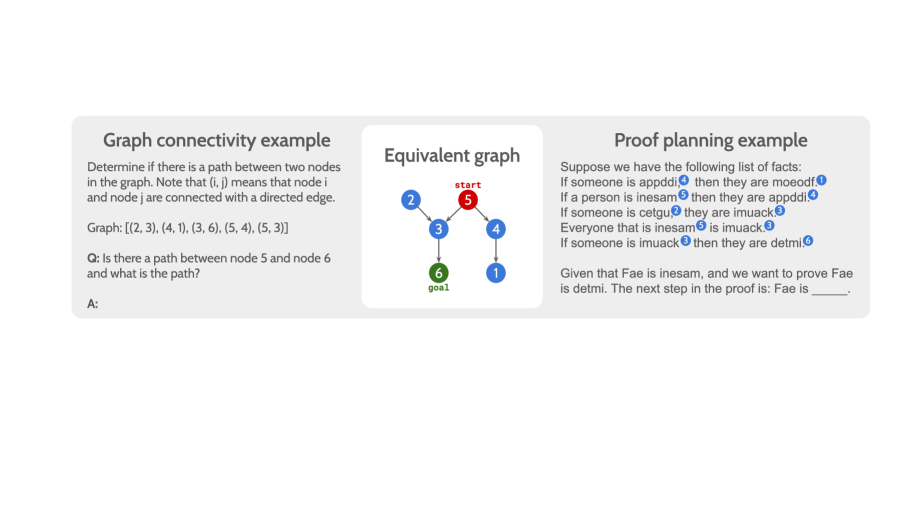
📊 实验亮点
实验结果表明,LRMs在DeepRD数据集上,当问题复杂度超过一定阈值时,性能会急剧下降,表明其泛化能力有限。论文还将LRM的性能与真实世界知识图的复杂性分布进行了比较,发现虽然大部分真实世界示例在LRM的成功范围内,但长尾部分仍然存在显著的失败风险。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型在需要复杂推理的实际场景中的性能,例如知识图谱推理、自然语言理解、智能问答、以及需要进行复杂逻辑推理的法律、医学等领域。未来的研究可以基于此发现,探索更有效的模型架构和训练方法,以提高模型在复杂推理任务中的泛化能力。
📄 摘要(原文)
Large language models (LLMs) have shown significant progress in reasoning tasks. However, recent studies show that transformers and LLMs fail catastrophically once reasoning problems exceed modest complexity. We revisit these findings through the lens of large reasoning models (LRMs) -- LLMs fine-tuned with incentives for step-by-step argumentation and self-verification. LRM performance on graph and reasoning benchmarks such as NLGraph seem extraordinary, with some even claiming they are capable of generalized reasoning and innovation in reasoning-intensive fields such as mathematics, physics, medicine, and law. However, by more carefully scaling the complexity of reasoning problems, we show existing benchmarks actually have limited complexity. We develop a new dataset, the Deep Reasoning Dataset (DeepRD), along with a generative process for producing unlimited examples of scalable complexity. We use this dataset to evaluate model performance on graph connectivity and natural language proof planning. We find that the performance of LRMs drop abruptly at sufficient complexity and do not generalize. We also relate our LRM results to the distributions of the complexities of large, real-world knowledge graphs, interaction graphs, and proof datasets. We find the majority of real-world examples fall inside the LRMs' success regime, yet the long tails expose substantial failure potential. Our analysis highlights the near-term utility of LRMs while underscoring the need for new methods that generalize beyond the complexity of examples in the training distribution.