Performance Trade-offs of Optimizing Small Language Models for E-Commerce
作者: Josip Tomo Licardo, Nikola Tankovic
分类: cs.AI, cs.CL
发布日期: 2025-10-24
备注: 15 pages, 9 figures
💡 一句话要点
针对电商领域,优化小型语言模型Llama 3.2,实现与大型模型GPT-4.1相当的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 电商意图识别 量化 QLoRA GPTQ GGUF 模型优化 资源效率
📋 核心要点
- 大型语言模型计算成本高昂,部署在电商等特定领域受限,需要更高效的替代方案。
- 采用QLoRA微调小型Llama 3.2模型,并进行后训练量化,优化模型性能。
- 实验表明,优化后的1B模型在电商意图识别上达到99%准确率,媲美GPT-4.1,且资源消耗更低。
📝 摘要(中文)
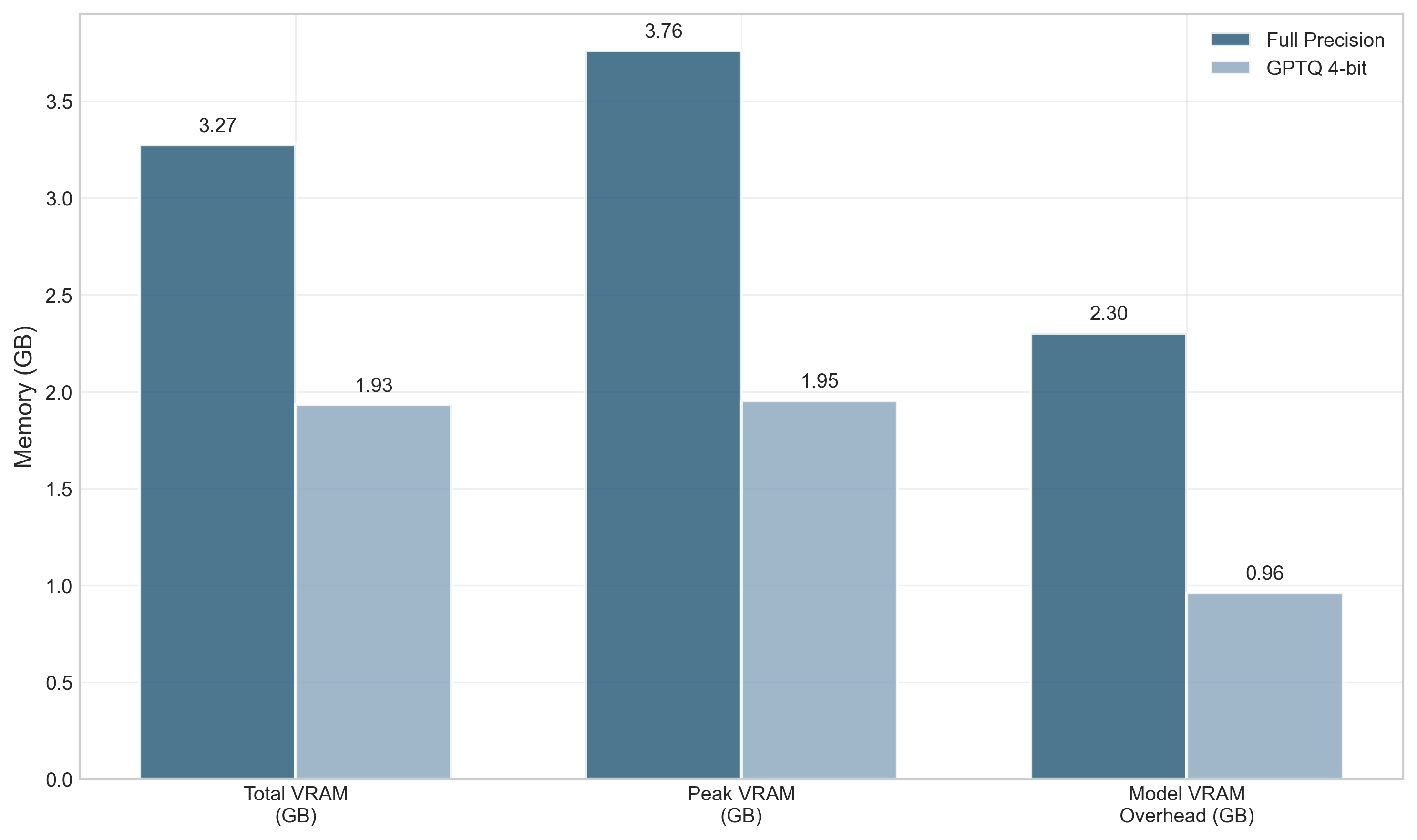
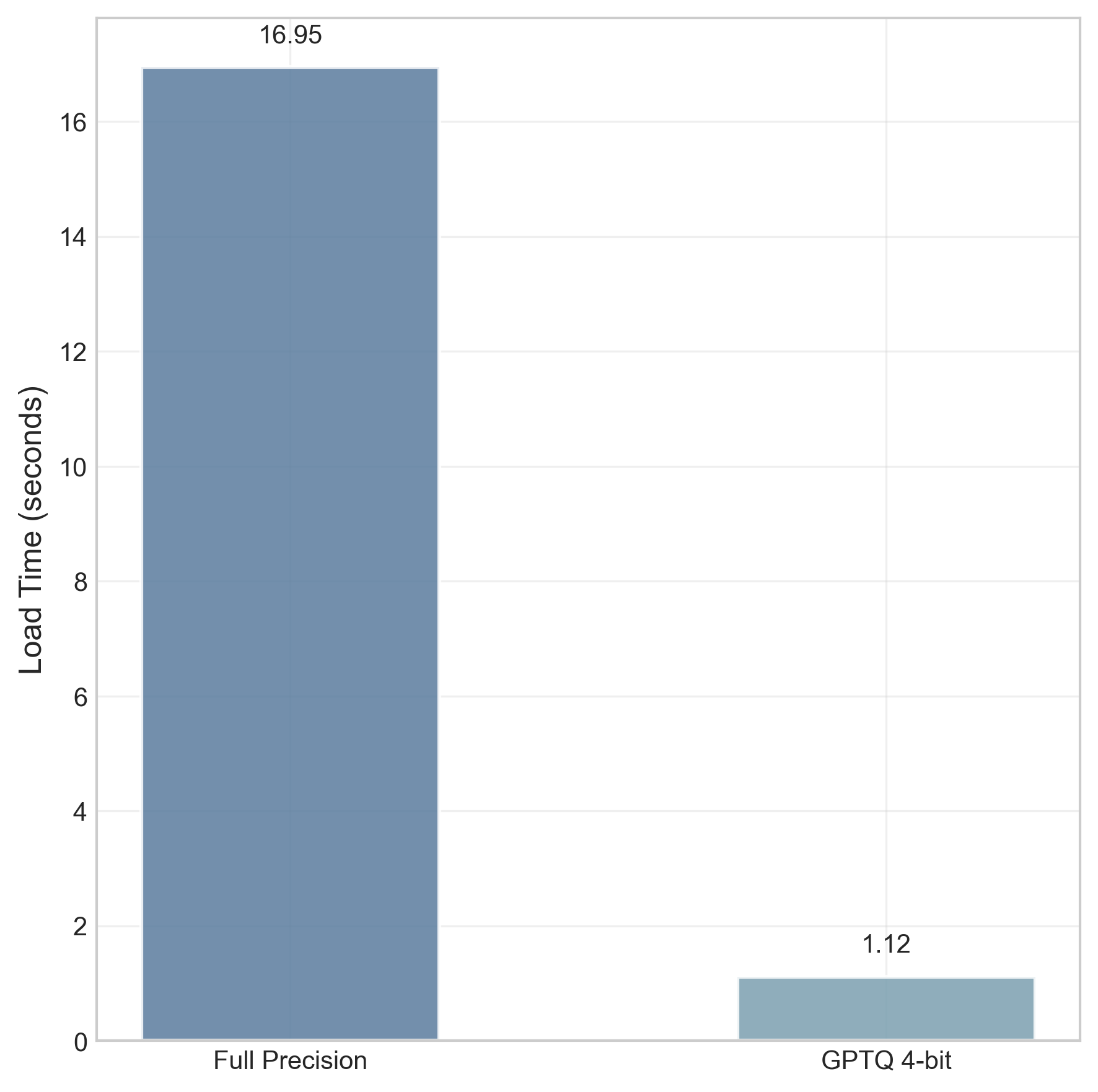
大型语言模型(LLMs)在自然语言理解和生成任务中表现出色。然而,将领先的商业模型部署到诸如电子商务等特定任务中,常常因高计算成本、延迟和运营费用而受阻。本文研究了小型、开放权重模型作为资源高效替代方案的可行性。我们提出了一种优化十亿参数Llama 3.2模型用于多语言电子商务意图识别的方法。该模型使用量化低秩适应(QLoRA)在合成生成的数据集上进行微调,该数据集旨在模拟真实世界的用户查询。随后,我们应用了后训练量化技术,创建了GPU优化(GPTQ)和CPU优化(GGUF)版本。结果表明,专门的1B模型实现了99%的准确率,与更大的GPT-4.1模型性能相当。详细的性能分析揭示了关键的、依赖于硬件的权衡:虽然4位GPTQ降低了41%的VRAM使用量,但由于反量化开销,它反而使旧GPU架构(NVIDIA T4)上的推理速度降低了82%。相反,CPU上的GGUF格式在推理吞吐量方面实现了高达18倍的加速,并且与FP16基线相比,RAM消耗降低了90%以上。我们得出结论,小型、经过适当优化的开放权重模型不仅是可行的,而且是特定领域应用的更合适的替代方案,以一小部分计算成本提供最先进的准确性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在特定领域(如电商)部署时面临的高计算成本、高延迟和高运营费用问题。现有方法依赖于大型模型,资源消耗大,难以在资源受限的环境中应用。
核心思路:论文的核心思路是利用小型、开放权重的语言模型,通过针对特定任务的优化,使其在特定领域达到与大型模型相当的性能,同时显著降低计算成本和资源消耗。通过微调和量化等技术,提高小型模型的效率。
技术框架:整体流程包括:1) 使用合成数据微调Llama 3.2模型,使其适应电商意图识别任务;2) 对微调后的模型进行后训练量化,生成GPTQ(GPU优化)和GGUF(CPU优化)两种格式;3) 在不同硬件平台上评估模型的性能,包括准确率、推理速度、内存占用等。
关键创新:关键创新在于针对特定领域,通过优化小型模型,在保证性能的同时,显著降低了计算成本。论文展示了小型模型在特定任务上可以媲美甚至超越大型模型的潜力。同时,论文详细分析了不同量化方法在不同硬件上的性能权衡,为实际部署提供了指导。
关键设计:论文使用了QLoRA进行微调,降低了训练成本。后训练量化采用了GPTQ和GGUF两种格式,分别针对GPU和CPU进行了优化。实验中,对比了不同硬件平台(如NVIDIA T4)上不同量化模型的性能,并分析了量化位数对性能的影响。合成数据集的设计也至关重要,需要尽可能模拟真实世界的用户查询。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过优化的1B Llama 3.2模型在电商意图识别任务上达到了99%的准确率,与GPT-4.1的性能相当。在NVIDIA T4 GPU上,4-bit GPTQ虽然降低了41%的VRAM使用量,但推理速度降低了82%。在CPU上,GGUF格式实现了高达18倍的推理吞吐量加速,并降低了超过90%的RAM消耗。
🎯 应用场景
该研究成果可应用于电商领域的智能客服、商品搜索、推荐系统等场景。通过部署小型、高效的语言模型,企业可以降低运营成本,提高服务响应速度,并为用户提供更个性化的体验。该研究也为其他资源受限场景下的自然语言处理任务提供了借鉴。
📄 摘要(原文)
Large Language Models (LLMs) offer state-of-the-art performance in natural language understanding and generation tasks. However, the deployment of leading commercial models for specialized tasks, such as e-commerce, is often hindered by high computational costs, latency, and operational expenses. This paper investigates the viability of smaller, open-weight models as a resource-efficient alternative. We present a methodology for optimizing a one-billion-parameter Llama 3.2 model for multilingual e-commerce intent recognition. The model was fine-tuned using Quantized Low-Rank Adaptation (QLoRA) on a synthetically generated dataset designed to mimic real-world user queries. Subsequently, we applied post-training quantization techniques, creating GPU-optimized (GPTQ) and CPU-optimized (GGUF) versions. Our results demonstrate that the specialized 1B model achieves 99% accuracy, matching the performance of the significantly larger GPT-4.1 model. A detailed performance analysis revealed critical, hardware-dependent trade-offs: while 4-bit GPTQ reduced VRAM usage by 41%, it paradoxically slowed inference by 82% on an older GPU architecture (NVIDIA T4) due to dequantization overhead. Conversely, GGUF formats on a CPU achieved a speedup of up to 18x in inference throughput and a reduction of over 90% in RAM consumption compared to the FP16 baseline. We conclude that small, properly optimized open-weight models are not just a viable but a more suitable alternative for domain-specific applications, offering state-of-the-art accuracy at a fraction of the computational cost.