Memo: Training Memory-Efficient Embodied Agents with Reinforcement Learning
作者: Gunshi Gupta, Karmesh Yadav, Zsolt Kira, Yarin Gal, Rahaf Aljundi
分类: cs.AI, cs.CV, cs.RO
发布日期: 2025-10-22 (更新: 2025-11-27)
备注: Accepted for Spotlight Presentation at NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出Memo,一种内存高效的具身智能体强化学习训练方法,适用于长时程任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 具身智能 强化学习 Transformer 记忆网络 长时程任务
📋 核心要点
- 现有基于Transformer的具身智能体策略训练,面临视觉输入超出Transformer上下文长度限制的问题。
- Memo通过周期性地将摘要token与模型输入交错,实现记忆的创建和检索,从而压缩和利用长期经验。
- 实验表明,Memo在计算和存储效率上优于长上下文Transformer,且能更好地泛化到更长的上下文。
📝 摘要(中文)
为了使具身智能体能够在较长时间范围内有效运行,开发能够形成和访问记忆的模型至关重要,以便在环境中保持上下文感知。在当前基于Transformer的策略训练范式中,视觉输入经常超出Transformer的上下文限制,而人类可以维持和利用压缩为记忆的终身经验。原则上可以实现显著的压缩,因为大部分输入是不相关的并且可以被抽象。然而,现有的方法主要集中于具有固定大小内存的循环模型或完全依赖上下文的Transformer。本文提出Memo,一种基于Transformer的架构和训练方法,用于在内存密集型、长时程任务上进行强化学习(RL)。Memo通过在训练期间将周期性的摘要token与模型的输入交错,从而实现记忆的创建和检索。我们在网格世界元强化学习基准测试和逼真的室内环境中的多对象导航任务上证明了Memo的有效性。Memo优于朴素的长上下文Transformer基线,同时更具计算和存储效率。此外,Memo在推理时更好地泛化到更长的上下文,并且在流式设置中保持鲁棒性,在这种设置中,必须截断历史上下文以适应推理约束。
🔬 方法详解
问题定义:论文旨在解决具身智能体在长时程任务中,由于视觉输入过多导致Transformer上下文长度受限,无法有效利用长期记忆的问题。现有方法要么依赖固定大小的循环记忆,要么完全依赖Transformer的完整上下文,无法兼顾效率和性能。
核心思路:Memo的核心思路是在Transformer架构中引入周期性的摘要token,这些token能够对历史信息进行压缩和概括,形成记忆。通过在训练过程中将这些摘要token与输入交错,模型可以学习如何创建、存储和检索这些记忆,从而在有限的上下文窗口内处理更长的序列。
技术框架:Memo的整体架构基于Transformer,主要包含以下几个模块:1) 输入编码器:将视觉输入或其他环境信息编码为向量表示。2) Transformer层:标准的Transformer层,用于处理输入和摘要token。3) 摘要token生成器:周期性地生成摘要token,用于概括历史信息。4) 记忆检索机制:在需要时,从记忆中检索相关信息,并将其与当前输入一起输入到Transformer中。训练过程中,摘要token与输入交错,共同参与Transformer的计算。
关键创新:Memo的关键创新在于将记忆机制融入到Transformer架构中,通过周期性的摘要token实现对长期信息的压缩和检索。与传统的循环模型相比,Memo能够更好地利用Transformer的并行计算能力。与完全依赖上下文的Transformer相比,Memo能够显著降低计算和存储成本。
关键设计:摘要token的生成频率是一个关键参数,需要根据任务的特点进行调整。损失函数包括标准的强化学习损失函数,以及用于鼓励摘要token有效概括历史信息的辅助损失函数。网络结构方面,可以采用标准的Transformer结构,也可以根据任务的特点进行定制。
🖼️ 关键图片


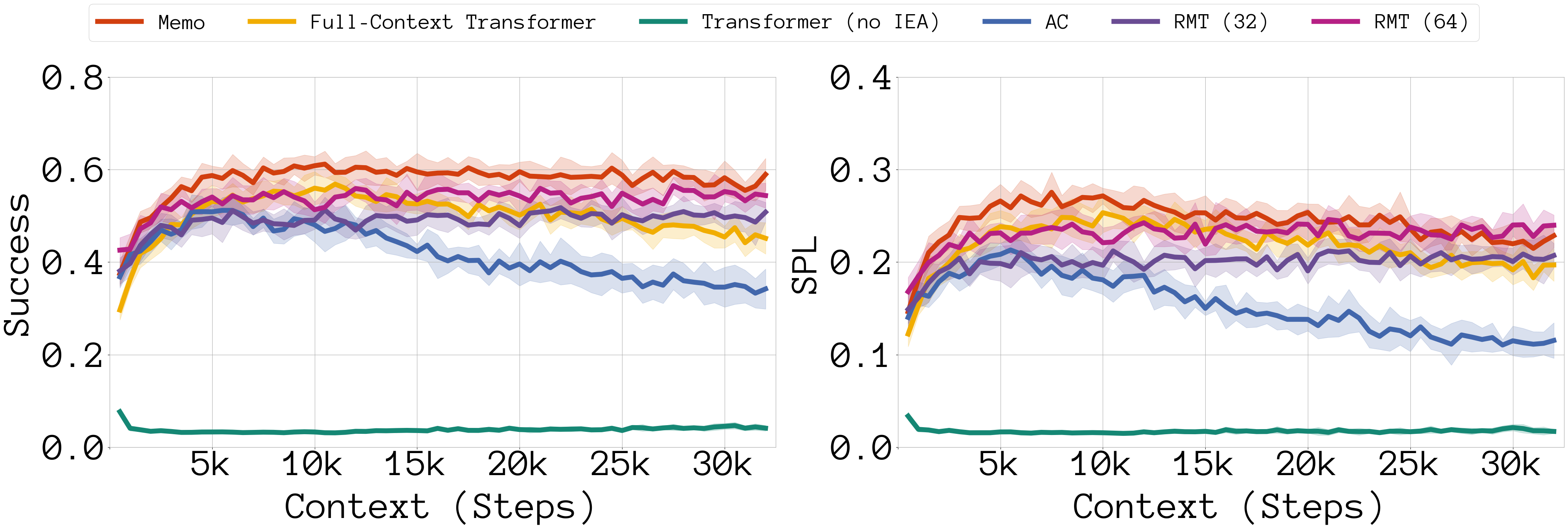
📊 实验亮点
实验结果表明,Memo在网格世界元强化学习基准测试和逼真的室内环境中的多对象导航任务上,优于朴素的长上下文Transformer基线。Memo在计算和存储效率上具有优势,并且能够更好地泛化到更长的上下文。此外,Memo在流式设置中也表现出良好的鲁棒性。
🎯 应用场景
Memo的潜在应用领域包括机器人导航、长期对话系统、游戏AI等需要处理长时程信息的任务。该研究的实际价值在于降低了训练和部署具身智能体的计算成本,使其能够在资源受限的环境中运行。未来,Memo可以与其他记忆增强技术相结合,进一步提升智能体的性能和泛化能力。
📄 摘要(原文)
To enable embodied agents to operate effectively over extended timeframes, it is crucial to develop models that form and access memories to stay contextualized in their environment. In the current paradigm of training transformer-based policies for embodied sequential decision-making tasks, visual inputs often overwhelm the context limits of transformers, while humans can maintain and utilize a lifetime of experience compressed as memories. Significant compression is possible in principle, as much of the input is irrelevant and can be abstracted. However, existing approaches predominantly focus on either recurrent models with fixed-size memory or transformers with full-context reliance. In this work, we propose Memo, a transformer-based architecture and training recipe for reinforcement learning (RL) on memory-intensive, long-horizon tasks. Memo incorporates the creation and retrieval of memory by interleaving periodic summarization tokens with the inputs of a model during training. We demonstrate Memo's effectiveness on a gridworld meta-RL benchmark and a multi-object navigation task in photo-realistic indoor settings. Memo outperforms naive long-context transformer baselines while being more compute and storage efficient. Additionally, Memo generalizes better to longer contexts at inference time and remains robust in streaming settings, where historical context must be truncated to fit inference constraints. Our code is available at: https://github.com/gunshi/memo.