EdgeReasoning: Characterizing Reasoning LLM Deployment on Edge GPUs
作者: Benjamin Kubwimana, Qijing Huang
分类: cs.DC, cs.AI, cs.AR
发布日期: 2025-10-21
备注: Published in the Proceedings of the 2025 IEEE International Symposium on Workload Characterization (IISWC 2025)
💡 一句话要点
EdgeReasoning:表征边缘GPU上推理LLM的部署,优化延迟-精度权衡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘计算 大型语言模型 推理优化 延迟-精度权衡 GPU部署
📋 核心要点
- 边缘部署LLM面临延迟约束和资源限制,开发者需权衡架构、模型大小、token预算和缩放策略。
- EdgeReasoning系统研究了推理LLM在边缘GPU上的部署,旨在量化延迟-精度权衡并优化部署策略。
- 该研究评估了prompt工程和模型微调以减少token长度,并分析了不同并行度的测试时缩放方法。
📝 摘要(中文)
新兴的自主系统,如机器人,对边缘智能的需求日益增长。边缘部署不仅确保了隐私保护操作和连接受限环境中的弹性,而且比基于云的解决方案具有显著的能源和成本优势。然而,在边缘GPU上部署用于推理任务的大型语言模型(LLM)面临着严格的延迟约束和有限的计算资源等关键挑战。为了应对这些约束,开发者必须平衡多个设计因素——选择推理与非推理架构、选择合适的模型大小、分配token预算以及应用测试时缩放策略——以满足目标延迟并优化准确性。然而,关于这些变量的最佳组合的指导仍然稀缺。在这项工作中,我们提出了EdgeReasoning,一项全面的研究,旨在表征推理LLM在边缘GPU上的部署。我们系统地量化了各种LLM架构和模型大小之间的延迟-精度权衡。我们系统地评估了基于prompt和基于模型微调的技术,以减少推理token长度,同时保持性能质量。我们进一步分析了具有不同并行度的测试时缩放方法,以在严格的延迟预算下最大化准确性。通过这些分析,EdgeReasoning绘制了可实现的准确性-延迟配置的Pareto前沿,为推理LLM的最佳边缘部署提供了系统的指导。
🔬 方法详解
问题定义:论文旨在解决在边缘设备上部署用于推理任务的大型语言模型(LLM)时,如何在严格的延迟约束和有限的计算资源下,优化模型的准确性和推理速度的问题。现有方法缺乏对不同LLM架构、模型大小、token预算和测试时缩放策略之间复杂关系的系统性分析,导致难以找到最佳的部署配置。
核心思路:EdgeReasoning的核心思路是通过系统性的实验和分析,量化不同设计选择(例如,LLM架构、模型大小、prompt工程、测试时缩放)对延迟和准确性的影响,从而为开发者提供在边缘设备上部署推理LLM的指导。通过绘制准确性-延迟配置的Pareto前沿,帮助开发者根据实际需求选择最佳的部署方案。
技术框架:EdgeReasoning的研究框架主要包括以下几个阶段:1) 选择不同的LLM架构和模型大小;2) 评估基于prompt和模型微调的token长度缩减技术;3) 分析不同并行度的测试时缩放方法;4) 在边缘GPU上进行实验,测量延迟和准确性;5) 分析实验结果,绘制准确性-延迟配置的Pareto前沿。
关键创新:EdgeReasoning的关键创新在于其系统性和全面性。它不仅考虑了多种LLM架构和模型大小,还深入研究了prompt工程和测试时缩放等优化技术。通过量化这些因素对延迟和准确性的影响,EdgeReasoning为边缘LLM部署提供了更细粒度的指导。与现有方法相比,EdgeReasoning更注重实际部署中的各种约束和权衡。
关键设计:论文的关键设计包括:1) 针对不同的推理任务,选择合适的prompt策略,例如few-shot learning;2) 使用模型量化和剪枝等技术来减小模型大小;3) 设计高效的并行推理方案,以充分利用边缘GPU的计算资源;4) 采用自适应的token预算分配策略,根据任务的复杂程度动态调整token数量。
🖼️ 关键图片
📊 实验亮点
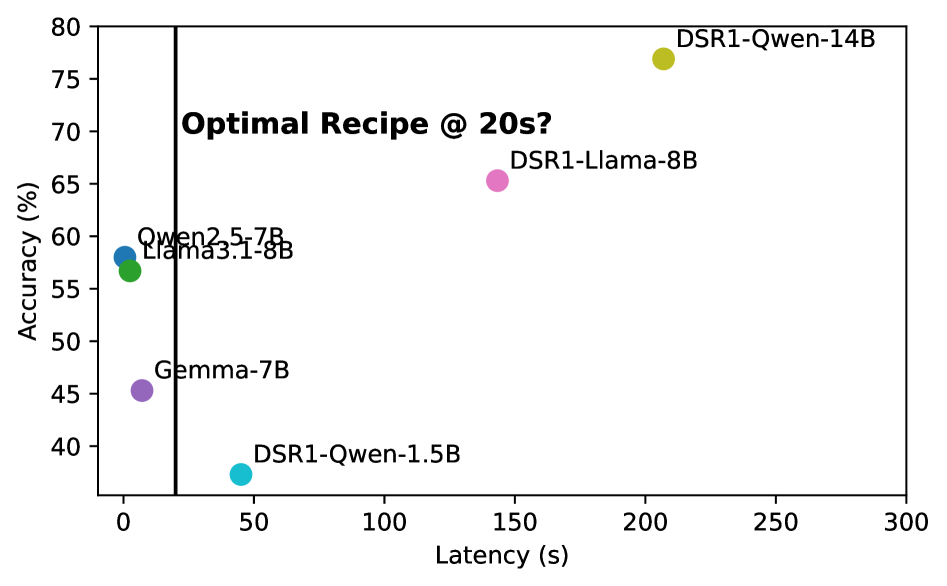
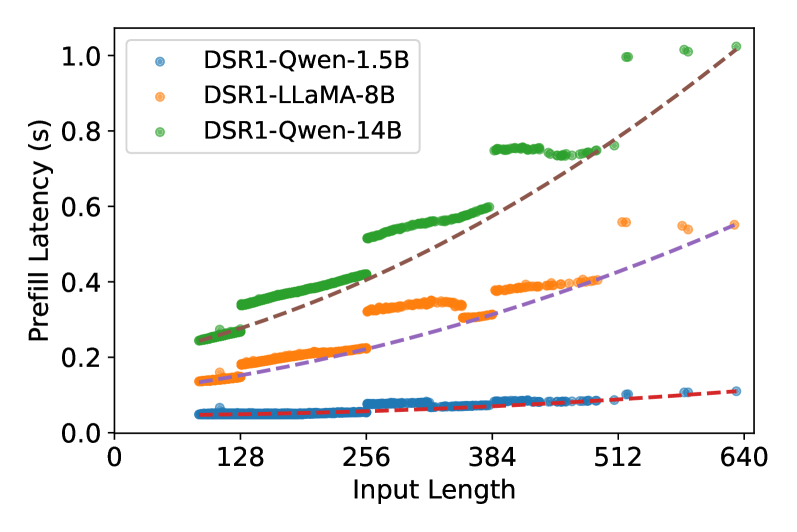
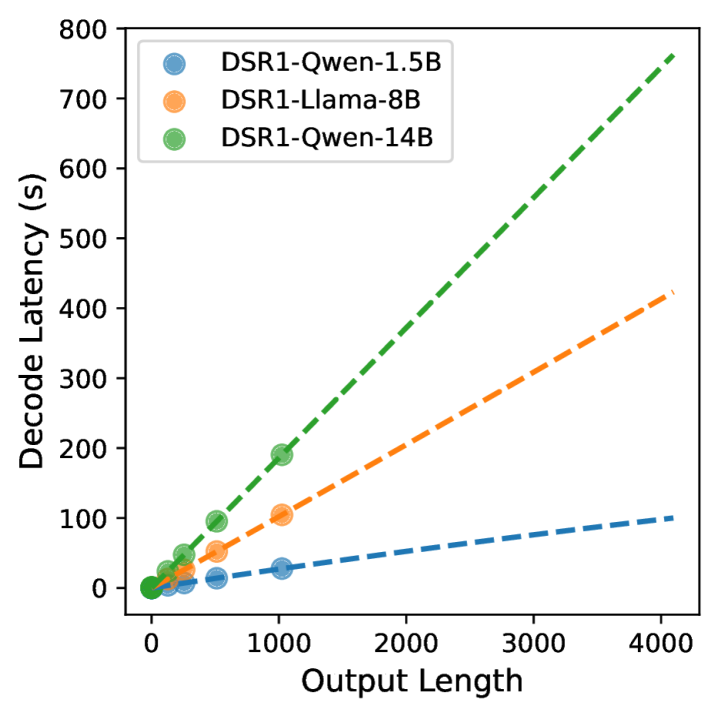
EdgeReasoning通过实验系统地量化了不同LLM架构和模型大小的延迟-精度权衡。研究表明,通过prompt工程和模型微调,可以在减少推理token长度的同时保持性能质量。此外,研究还分析了不同并行度的测试时缩放方法,为在严格延迟预算下最大化准确性提供了指导。这些实验结果为边缘LLM部署提供了宝贵的参考。
🎯 应用场景
EdgeReasoning的研究成果可广泛应用于机器人、自动驾驶、智能家居等边缘计算场景。通过优化LLM在边缘设备上的部署,可以实现更快速、更可靠、更节能的推理服务,提升用户体验,并降低运营成本。该研究为未来边缘智能的发展奠定了基础,有助于推动更多复杂AI应用在资源受限的环境中落地。
📄 摘要(原文)
Edge intelligence paradigm is increasingly demanded by the emerging autonomous systems, such as robotics. Beyond ensuring privacy-preserving operation and resilience in connectivity-limited environments, edge deployment offers significant energy and cost advantages over cloud-based solutions. However, deploying large language models (LLMs) for reasoning tasks on edge GPUs faces critical challenges from strict latency constraints and limited computational resources. To navigate these constraints, developers must balance multiple design factors - choosing reasoning versus non-reasoning architectures, selecting appropriate model sizes, allocating token budgets, and applying test-time scaling strategies - to meet target latency and optimize accuracy. Yet guidance on optimal combinations of these variables remains scarce. In this work, we present EdgeReasoning, a comprehensive study characterizing the deployment of reasoning LLMs on edge GPUs. We systematically quantify latency-accuracy tradeoffs across various LLM architectures and model sizes. We systematically evaluate prompt-based and model-tuning-based techniques for reducing reasoning token length while maintaining performance quality. We further profile test-time scaling methods with varying degrees of parallelism to maximize accuracy under strict latency budgets. Through these analyses, EdgeReasoning maps the Pareto frontier of achievable accuracy-latency configurations, offering systematic guidance for optimal edge deployment of reasoning LLMs.