DiffGRM: Diffusion-based Generative Recommendation Model
作者: Zhao Liu, Yichen Zhu, Yiqing Yang, Guoping Tang, Rui Huang, Qiang Luo, Xiao Lv, Ruiming Tang, Kun Gai, Guorui Zhou
分类: cs.IR, cs.AI, cs.LG
发布日期: 2025-10-21
备注: 13 pages, 5 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出DiffGRM,一种基于扩散模型的生成式推荐模型,解决语义ID的结构性问题。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 生成式推荐 扩散模型 语义ID 并行编码 噪声注入
📋 核心要点
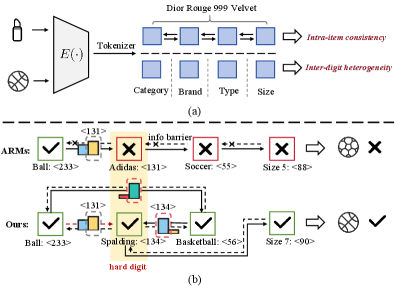
- 传统自回归生成式推荐模型在处理语义ID时,由于其内部一致性和数字间异质性,导致训练效率和效果受限。
- DiffGRM采用掩码离散扩散模型,通过并行语义编码、On-policy Coherent Noising和置信度引导的并行去噪,实现更有效的训练和推理。
- 实验结果表明,DiffGRM在多个数据集上显著优于现有的生成式和判别式推荐模型,NDCG@10指标提升高达15.5%。
📝 摘要(中文)
生成式推荐(GR)是一种新兴范式,它通过分词器将每个物品表示为一个n位语义ID(SID),并通过自回归方式生成SID来预测下一个物品。然而,SID的两个结构性属性使得自回归模型(ARM)不太适用:一是物品内部一致性,即n位数字共同指定一个物品,但从左到右的因果关系仅在其前缀下训练每个数字,阻碍了双向跨数字证据,将监督坍缩到单个因果路径;二是数字间异质性,即数字在语义粒度和可预测性上有所不同,而统一的下一个token目标为所有数字分配相同的权重,过度训练容易的数字,而训练不足困难的数字。为了解决这两个问题,我们提出了DiffGRM,一种基于扩散的GR模型,它用掩码离散扩散模型(MDM)代替了自回归解码器,从而实现了SID数字的双向上下文和任意顺序并行生成,以用于推荐。具体来说,我们从三个方面定制了DiffGRM:(1)使用并行语义编码(PSE)进行分词,以解耦数字并平衡每个数字的信息;(2)使用On-policy Coherent Noising(OCN)进行训练,通过连贯的掩码优先考虑不确定的数字,从而将监督集中在高价值信号上;(3)使用置信度引导的并行去噪(CPD)进行推理,首先填充更高置信度的数字,并生成多样化的Top-K候选。实验表明,在多个数据集上,相对于强大的生成式和判别式推荐基线,DiffGRM取得了持续的收益,将NDCG@10提高了6.9%-15.5%。代码可在https://github.com/liuzhao09/DiffGRM 获得。
🔬 方法详解
问题定义:论文旨在解决生成式推荐模型中,由于物品语义ID(SID)的结构性问题导致的自回归模型训练效率低下的问题。具体来说,SID的内部一致性(各个数字共同决定一个物品)和数字间异质性(不同数字的语义粒度和可预测性不同)使得自回归模型难以充分利用信息,导致模型性能受限。现有方法通常采用从左到右的因果关系进行训练,忽略了双向信息,并且对所有数字采用相同的训练权重,导致训练不均衡。
核心思路:DiffGRM的核心思路是利用扩散模型来替代自回归模型,从而克服SID的结构性问题。扩散模型允许双向上下文信息的使用,并且可以通过控制噪声添加的方式来调整不同数字的训练权重。通过这种方式,DiffGRM可以更有效地利用SID中的信息,从而提高推荐性能。
技术框架:DiffGRM的整体框架包括三个主要模块:并行语义编码(PSE)、On-policy Coherent Noising(OCN)和置信度引导的并行去噪(CPD)。首先,PSE将物品编码为SID,并解耦各个数字,平衡每个数字的信息量。然后,OCN通过优先对不确定的数字添加噪声,将训练集中在高价值信号上。最后,CPD在推理阶段,首先填充高置信度的数字,并生成多样化的Top-K候选。
关键创新:DiffGRM的关键创新在于使用扩散模型进行生成式推荐,并针对SID的特性设计了PSE、OCN和CPD。与传统的自回归模型相比,DiffGRM能够利用双向上下文信息,并且可以根据数字的重要性调整训练权重。这使得DiffGRM能够更有效地利用SID中的信息,从而提高推荐性能。
关键设计:PSE通过特定的编码方式确保各个数字包含的信息量相对均衡。OCN使用On-policy的方式选择需要添加噪声的数字,并根据数字的不确定性调整噪声的强度。CPD使用置信度作为指导,优先填充高置信度的数字,并采用特定的策略生成Top-K候选,以提高推荐的多样性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DiffGRM在多个数据集上显著优于现有的生成式和判别式推荐模型。例如,在某个数据集上,DiffGRM的NDCG@10指标比最强的基线模型提升了6.9%-15.5%。这些结果表明,DiffGRM能够更有效地利用物品的语义信息,从而提高推荐性能。
🎯 应用场景
DiffGRM可应用于各种推荐系统场景,尤其是在需要对物品进行细粒度建模的场景下,例如电商推荐、内容推荐等。该模型能够更有效地利用物品的语义信息,提高推荐的准确性和多样性,从而提升用户体验和平台收益。未来,该模型可以进一步扩展到其他生成式任务中,例如文本生成、图像生成等。
📄 摘要(原文)
Generative recommendation (GR) is an emerging paradigm that represents each item via a tokenizer as an n-digit semantic ID (SID) and predicts the next item by autoregressively generating its SID conditioned on the user's history. However, two structural properties of SIDs make ARMs ill-suited. First, intra-item consistency: the n digits jointly specify one item, yet the left-to-right causality trains each digit only under its prefix and blocks bidirectional cross-digit evidence, collapsing supervision to a single causal path. Second, inter-digit heterogeneity: digits differ in semantic granularity and predictability, while the uniform next-token objective assigns equal weight to all digits, overtraining easy digits and undertraining hard digits. To address these two issues, we propose DiffGRM, a diffusion-based GR model that replaces the autoregressive decoder with a masked discrete diffusion model (MDM), thereby enabling bidirectional context and any-order parallel generation of SID digits for recommendation. Specifically, we tailor DiffGRM in three aspects: (1) tokenization with Parallel Semantic Encoding (PSE) to decouple digits and balance per-digit information; (2) training with On-policy Coherent Noising (OCN) that prioritizes uncertain digits via coherent masking to concentrate supervision on high-value signals; and (3) inference with Confidence-guided Parallel Denoising (CPD) that fills higher-confidence digits first and generates diverse Top-K candidates. Experiments show consistent gains over strong generative and discriminative recommendation baselines on multiple datasets, improving NDCG@10 by 6.9%-15.5%. Code is available at https://github.com/liuzhao09/DiffGRM.