The MUSE Benchmark: Probing Music Perception and Auditory Relational Reasoning in Audio LLMS
作者: Brandon James Carone, Iran R. Roman, Pablo Ripollés
分类: cs.AI, cs.SD, eess.AS
发布日期: 2025-10-21
备注: 5 pages, 2 figures, 2 tables
💡 一句话要点
MUSE基准测试:用于评估音频LLM音乐感知和听觉关系推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐理解 听觉关系推理 多模态大语言模型 基准测试 音乐感知
📋 核心要点
- 现有音频理解评估方法可能无法充分揭示MLLM在音乐关系推理方面的弱点。
- 提出MUSE基准测试,包含10个任务,用于评估模型在音乐感知和关系推理方面的能力。
- 实验结果表明,现有SOTA模型在音乐理解方面与人类专家存在显著差距,且CoT提示效果不稳定。
📝 摘要(中文)
多模态大型语言模型(MLLM)已展现出在音频理解方面的能力,但目前的评估可能掩盖了其在关系推理方面的根本弱点。我们推出了音乐理解和结构评估(MUSE)基准测试,这是一个包含10个任务的开源资源,旨在探测基本的音乐感知技能。我们评估了四个SOTA模型(Gemini Pro和Flash、Qwen2.5-Omni和Audio-Flamingo 3),并与大型人类基线(N=200)进行了比较。结果表明,SOTA模型的能力差异很大,并且与人类专家之间存在持续的差距。虽然Gemini Pro在基本感知方面表现出色,但Qwen和Audio Flamingo 3的性能接近或低于随机水平,暴露了严重的感知缺陷。此外,我们发现思维链(CoT)提示提供了不一致的,通常是有害的结果。我们的工作为评估不变的音乐表示和推动更强大的AI系统的开发提供了一个关键工具。
🔬 方法详解
问题定义:现有对多模态大型语言模型(MLLM)的音频理解能力评估可能无法充分揭示其在音乐感知和听觉关系推理方面的弱点。具体来说,模型可能在表面上表现出一定的音频理解能力,但缺乏对音乐结构和内在关系的深层理解,导致在需要复杂推理的任务中表现不佳。现有方法难以有效区分模型是真正理解了音乐,还是仅仅记住了某些模式。
核心思路:MUSE基准测试的核心思路是通过设计一系列专门的任务,系统性地探测MLLM在音乐感知和听觉关系推理方面的能力。这些任务涵盖了音乐的多个方面,例如音高、节奏、和声等,并要求模型进行不同层次的推理,从而全面评估其音乐理解能力。通过与人类专家的表现进行对比,可以更清晰地了解模型与人类在音乐理解方面的差距。
技术框架:MUSE基准测试包含10个任务,这些任务可以分为不同的类别,例如:音高识别、节奏分析、和声理解、音乐结构分析等。每个任务都设计成能够考察模型在特定音乐感知或推理方面的能力。基准测试提供了一套统一的评估指标,用于衡量模型在每个任务上的表现。同时,基准测试还提供了一个大型的人类基线,用于与模型的表现进行对比。
关键创新:MUSE基准测试的关键创新在于其任务设计的针对性和全面性。与现有的音频理解基准测试相比,MUSE更加关注音乐的结构和关系,能够更有效地探测模型在音乐感知和听觉关系推理方面的能力。此外,MUSE还提供了一个大型的人类基线,为评估模型的性能提供了一个可靠的参考。
关键设计:MUSE基准测试的任务设计涵盖了音乐的多个方面,例如音高、节奏、和声等。每个任务都设计成能够考察模型在特定音乐感知或推理方面的能力。例如,音高识别任务要求模型识别给定音符的音高;节奏分析任务要求模型分析给定音乐片段的节奏模式;和声理解任务要求模型理解给定音乐片段的和声结构。此外,基准测试还考虑了不同难度级别的任务,以评估模型在不同层次的音乐理解能力。
🖼️ 关键图片
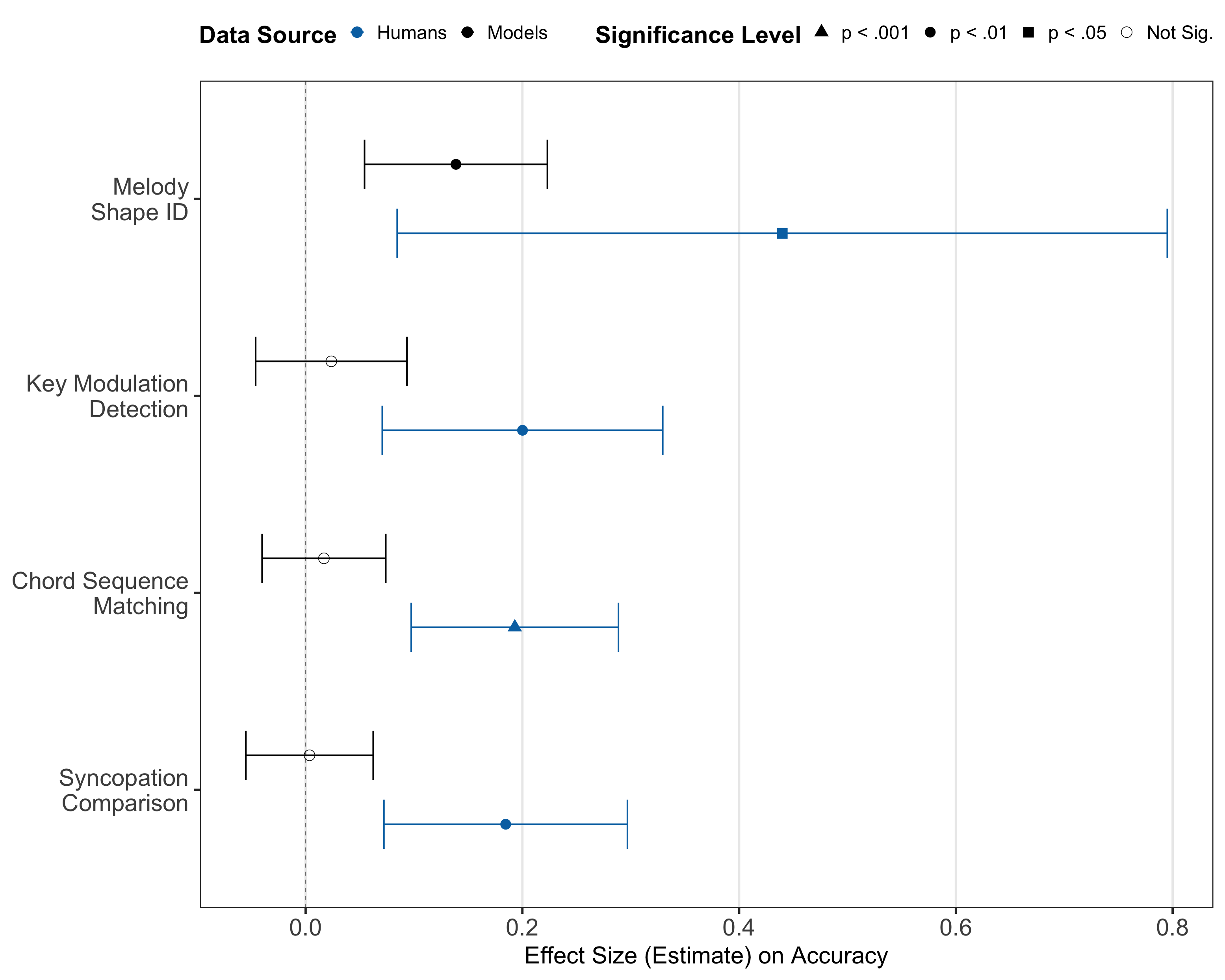
📊 实验亮点
实验结果表明,现有SOTA模型在MUSE基准测试上的表现差异显著。Gemini Pro在基本感知任务上表现较好,但Qwen和Audio Flamingo 3的性能接近随机水平,表明其存在严重的感知缺陷。此外,思维链(CoT)提示对模型的性能提升效果不一致,有时甚至会产生负面影响。这些结果突显了现有模型在音乐理解方面的局限性,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于开发更智能的音乐生成、推荐和分析系统。通过MUSE基准测试,可以更好地评估和改进AI模型在音乐理解方面的能力,从而推动音乐创作工具、音乐教育软件和音乐治疗等领域的发展。此外,该基准测试也可用于研究人类音乐认知,为认知科学提供新的视角。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated capabilities in audio understanding, but current evaluations may obscure fundamental weaknesses in relational reasoning. We introduce the Music Understanding and Structural Evaluation (MUSE) Benchmark, an open-source resource with 10 tasks designed to probe fundamental music perception skills. We evaluate four SOTA models (Gemini Pro and Flash, Qwen2.5-Omni, and Audio-Flamingo 3) against a large human baseline (N=200). Our results reveal a wide variance in SOTA capabilities and a persistent gap with human experts. While Gemini Pro succeeds on basic perception, Qwen and Audio Flamingo 3 perform at or near chance, exposing severe perceptual deficits. Furthermore, we find Chain-of-Thought (CoT) prompting provides inconsistent, often detrimental results. Our work provides a critical tool for evaluating invariant musical representations and driving development of more robust AI systems.