A Justice Lens on Fairness and Ethics Courses in Computing Education: LLM-Assisted Multi-Perspective and Thematic Evaluation
作者: Kenya S. Andrews, Deborah Dormah Kanubala, Kehinde Aruleba, Francisco Enrique Vicente Castro, Renata A Revelo
分类: cs.CY, cs.AI, cs.LG
发布日期: 2025-10-21
备注: 14 pages, 8 figures, In Review
💡 一句话要点
利用LLM多视角评估,提升计算教育中公平与伦理课程的教学设计。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 课程评估 公平性 伦理 计算教育 多视角评估 AI伦理
📋 核心要点
- 现有公平与伦理课程大纲评估耗时且主观,缺乏系统性方法。
- 利用LLM进行多视角角色模拟,结合公正导向评分标准,实现更全面客观的评估。
- 实验表明,多视角评估能有效识别课程设计中的盲点,为课程改进提供具体指导。
📝 摘要(中文)
课程大纲为课程设定了基调和期望,影响着学生和教师的学习体验。在计算课程中,特别是那些涉及人工智能(AI)、机器学习(ML)和算法设计中的公平性和伦理的课程,理解如何解决实现公平结果的障碍至关重要。这些期望应该是包容的、透明的,并且以促进批判性思维为基础。课程大纲分析提供了一种评估课程覆盖范围、深度、实践和期望的方法。然而,手动课程大纲评估既耗时又容易出现不一致。为了解决这个问题,我们开发了一个以公正为导向的评分标准,并要求大型语言模型(LLM)通过多视角角色模拟来审查课程大纲。使用这个评分标准,我们从四个角度评估了24个课程大纲:教师、系主任、机构审查员和外部评估员。我们还提示LLM识别课程中的主题趋势。研究结果表明,多视角评估有助于我们注意到细微的、特定于角色的优先级,并利用它们来填补AI/ML和相关计算课程(侧重于公平性和伦理)课程设计中的隐藏差距。这些见解为改进此类课程中公平性、伦理和公正内容的教学设计和交付提供了具体方向。
🔬 方法详解
问题定义:现有计算教育,特别是AI/ML相关的公平与伦理课程,其课程大纲的评估主要依赖于人工,存在耗时、主观性强、难以发现潜在问题等痛点。缺乏一种系统性的、多视角的评估方法,难以保证课程设计的全面性和有效性。
核心思路:本研究的核心思路是利用大型语言模型(LLM)的自然语言处理能力,模拟不同角色的视角(如教师、系主任、机构审查员、外部评估员),并结合公正导向的评分标准,对课程大纲进行多维度评估。通过这种方式,可以更全面地了解课程大纲的优势和不足,为课程改进提供更具针对性的建议。
技术框架:该方法主要包含以下几个阶段:1) 设计公正导向的评分标准;2) 收集公平与伦理相关的课程大纲;3) 利用LLM模拟不同角色,并根据评分标准对课程大纲进行评估;4) 分析LLM的评估结果,识别课程设计中的主题趋势和潜在问题;5) 基于分析结果,为课程改进提供建议。
关键创新:该研究的关键创新在于将LLM的多视角模拟能力应用于课程大纲评估,并结合公正导向的评分标准,从而实现更全面、客观的评估。与传统的单一视角的人工评估相比,该方法能够更好地识别课程设计中的盲点和潜在问题。
关键设计:评分标准的设计是关键。评分标准需要能够反映不同角色的关注点,并涵盖公平、伦理和公正等多个维度。LLM的角色模拟也需要精心设计,以确保LLM能够准确地理解不同角色的视角和目标。此外,还需要对LLM的输出进行适当的后处理和分析,以提取有用的信息。
🖼️ 关键图片


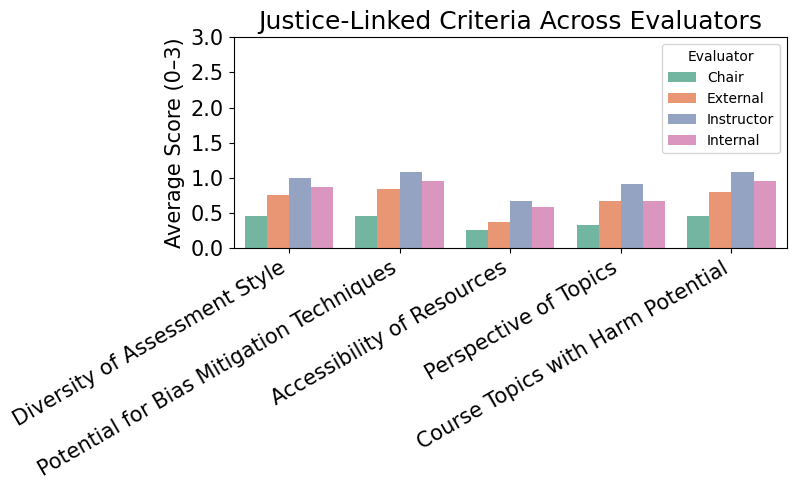
📊 实验亮点
该研究通过LLM多视角评估,揭示了现有公平与伦理课程大纲中存在的不足,例如对某些关键议题的关注不足,以及不同角色对课程的期望存在差异。实验结果表明,多视角评估能够有效地识别这些问题,并为课程改进提供具体的指导方向,例如增加对特定议题的讨论,或调整课程内容以满足不同角色的期望。
🎯 应用场景
该研究成果可应用于计算教育领域,帮助教师和课程设计者更有效地设计和改进公平与伦理相关的课程。通过多视角评估,可以确保课程内容更加全面、公正,并促进学生对公平、伦理和公正等问题的深入思考。此外,该方法还可以推广到其他领域的课程评估中,提高课程设计的质量和效果。
📄 摘要(原文)
Course syllabi set the tone and expectations for courses, shaping the learning experience for both students and instructors. In computing courses, especially those addressing fairness and ethics in artificial intelligence (AI), machine learning (ML), and algorithmic design, it is imperative that we understand how approaches to navigating barriers to fair outcomes are being addressed.These expectations should be inclusive, transparent, and grounded in promoting critical thinking. Syllabus analysis offers a way to evaluate the coverage, depth, practices, and expectations within a course. Manual syllabus evaluation, however, is time-consuming and prone to inconsistency. To address this, we developed a justice-oriented scoring rubric and asked a large language model (LLM) to review syllabi through a multi-perspective role simulation. Using this rubric, we evaluated 24 syllabi from four perspectives: instructor, departmental chair, institutional reviewer, and external evaluator. We also prompted the LLM to identify thematic trends across the courses. Findings show that multiperspective evaluation aids us in noting nuanced, role-specific priorities, leveraging them to fill hidden gaps in curricula design of AI/ML and related computing courses focused on fairness and ethics. These insights offer concrete directions for improving the design and delivery of fairness, ethics, and justice content in such courses.