HarmNet: A Framework for Adaptive Multi-Turn Jailbreak Attacks on Large Language Models
作者: Sidhant Narula, Javad Rafiei Asl, Mohammad Ghasemigol, Eduardo Blanco, Daniel Takabi
分类: cs.CR, cs.AI
发布日期: 2025-10-21
备注: This paper has been accepted for presentation at the Conference on Applied Machine Learning in Information Security (CAMLIS 2025)
💡 一句话要点
HarmNet:一种用于大语言模型的多轮自适应越狱攻击框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 越狱攻击 大型语言模型 对抗性框架 查询优化 安全评估 ThoughtNet 自适应攻击
📋 核心要点
- 现有大语言模型在多轮对话中仍存在安全漏洞,容易受到对抗性攻击,威胁模型安全。
- HarmNet通过构建语义网络、模拟器和网络遍历器,自适应地探索和优化对抗空间,寻找有效的攻击路径。
- 实验结果表明,HarmNet在多种LLM上均优于现有方法,显著提高了攻击成功率,例如在Mistral-7B上提升了13.9%。
📝 摘要(中文)
大型语言模型(LLMs)仍然容易受到多轮越狱攻击。我们提出了 HarmNet,这是一个模块化框架,包含一个分层语义网络ThoughtNet;一个用于迭代查询优化的反馈驱动模拟器;以及一个用于实时自适应攻击执行的网络遍历器。HarmNet系统地探索和优化对抗空间,以发现隐蔽的、高成功率的攻击路径。在闭源和开源LLM上的实验表明,HarmNet优于最先进的方法,实现了更高的攻击成功率。例如,在Mistral-7B上,HarmNet实现了99.4%的攻击成功率,比最佳基线高出13.9%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在多轮对话中容易受到越狱攻击的问题。现有的攻击方法通常难以发现隐蔽且成功的攻击路径,尤其是在多轮对话的上下文中,攻击的有效性会随着对话的进行而降低。因此,需要一种能够自适应地探索和优化对抗空间,从而发现高成功率攻击路径的框架。
核心思路:HarmNet的核心思路是构建一个模块化的框架,该框架能够系统地探索和优化对抗空间,以发现隐蔽且高成功率的攻击路径。该框架通过ThoughtNet构建语义网络,模拟器进行迭代查询优化,以及网络遍历器进行实时自适应攻击执行,从而实现对LLM的有效越狱攻击。这种设计允许框架根据LLM的反馈动态调整攻击策略,提高攻击的成功率。
技术框架:HarmNet框架主要包含三个模块:ThoughtNet、Simulator和Network Traverser。ThoughtNet是一个分层语义网络,用于表示攻击相关的概念和关系。Simulator是一个反馈驱动的模拟器,用于迭代地优化查询,使其更具攻击性。Network Traverser则负责实时地执行攻击,并根据LLM的反馈自适应地调整攻击策略。整个流程是:首先,ThoughtNet构建攻击知识图谱;然后,Simulator利用LLM的反馈迭代优化攻击query;最后,Network Traverser根据优化后的query执行攻击。
关键创新:HarmNet的关键创新在于其模块化的设计和自适应的攻击策略。与传统的攻击方法相比,HarmNet能够更系统地探索对抗空间,并根据LLM的反馈动态调整攻击策略,从而发现更隐蔽和有效的攻击路径。此外,ThoughtNet的使用使得框架能够更好地理解攻击相关的概念和关系,从而生成更具针对性的攻击query。
关键设计:ThoughtNet采用分层结构,顶层表示攻击目标,底层表示具体的攻击query。Simulator使用强化学习算法,根据LLM的反馈信号(例如,是否生成有害内容)来优化query。Network Traverser使用贪心算法,选择最有可能成功的攻击路径。具体的损失函数和网络结构细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片
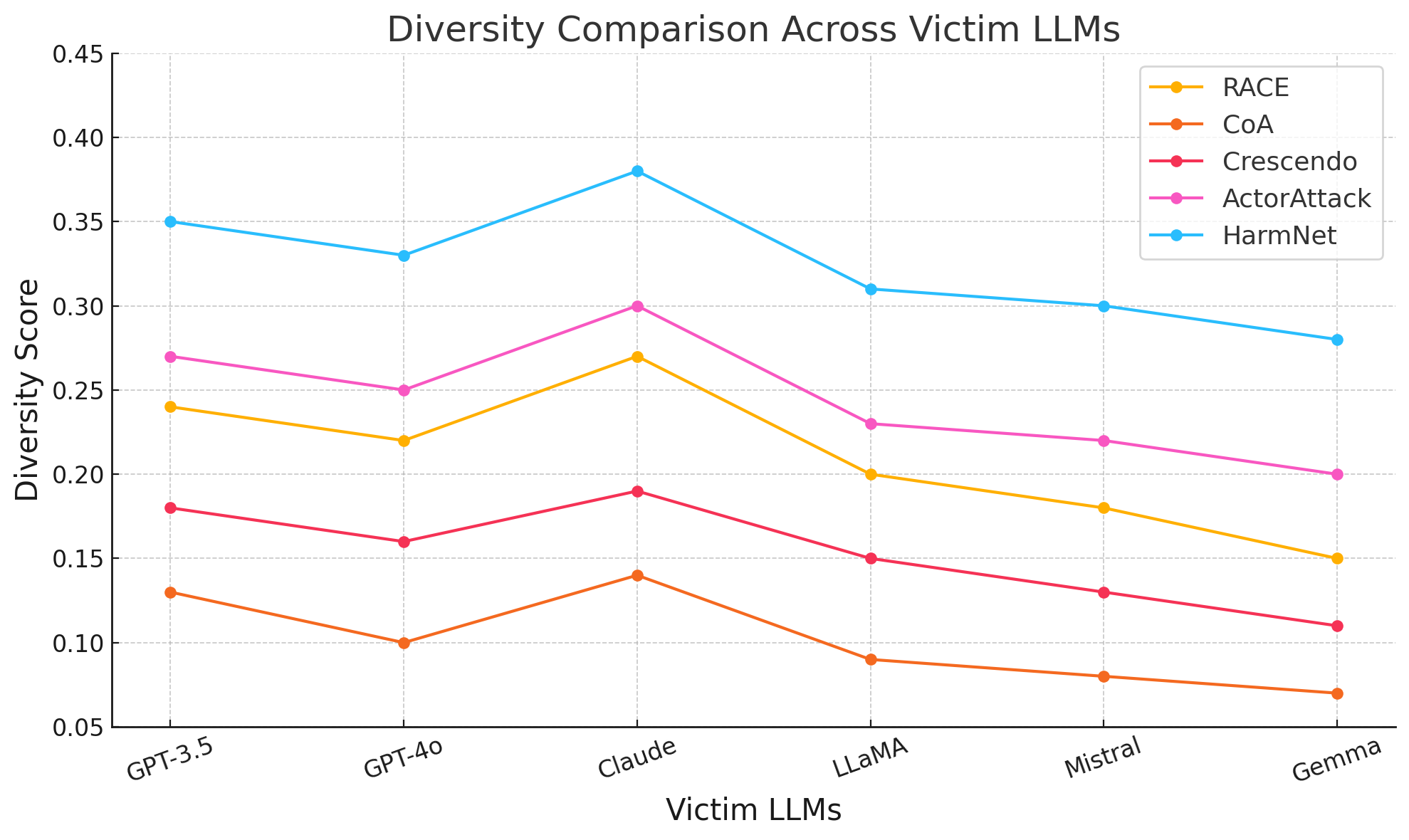
📊 实验亮点
HarmNet在多个LLM上进行了实验,结果表明其优于现有的越狱攻击方法。例如,在Mistral-7B上,HarmNet实现了99.4%的攻击成功率,比最佳基线高出13.9%。此外,HarmNet在其他闭源和开源LLM上也取得了显著的性能提升,证明了其有效性和泛化能力。
🎯 应用场景
HarmNet的研究成果可应用于评估和提升大型语言模型的安全性。通过使用HarmNet进行对抗性测试,可以发现LLM潜在的安全漏洞,并为开发更鲁棒的模型提供指导。此外,该框架也可以用于开发防御机制,以抵御恶意攻击,从而提高LLM在实际应用中的可靠性。
📄 摘要(原文)
Large Language Models (LLMs) remain vulnerable to multi-turn jailbreak attacks. We introduce HarmNet, a modular framework comprising ThoughtNet, a hierarchical semantic network; a feedback-driven Simulator for iterative query refinement; and a Network Traverser for real-time adaptive attack execution. HarmNet systematically explores and refines the adversarial space to uncover stealthy, high-success attack paths. Experiments across closed-source and open-source LLMs show that HarmNet outperforms state-of-the-art methods, achieving higher attack success rates. For example, on Mistral-7B, HarmNet achieves a 99.4% attack success rate, 13.9% higher than the best baseline. Index terms: jailbreak attacks; large language models; adversarial framework; query refinement.