Exploring Membership Inference Vulnerabilities in Clinical Large Language Models
作者: Alexander Nemecek, Zebin Yun, Zahra Rahmani, Yaniv Harel, Vipin Chaudhary, Mahmood Sharif, Erman Ayday
分类: cs.CR, cs.AI
发布日期: 2025-10-21
备注: Accepted at the 1st IEEE Workshop on Healthcare and Medical Device Security, Privacy, Resilience, and Trust (IEEE HMD-SPiRiT)
💡 一句话要点
探索临床大语言模型中的成员推理漏洞,评估患者隐私泄露风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 临床大语言模型 成员推理攻击 隐私泄露 电子健康记录 释义扰动
📋 核心要点
- 临床LLM在医疗领域的应用日益广泛,但其在敏感数据上的微调可能导致患者隐私泄露,这是一个亟待解决的问题。
- 本研究通过成员推理攻击,评估临床LLM是否会泄露训练数据中的患者信息,并探索更符合临床场景的攻击方式。
- 初步实验表明,现有临床LLM存在一定程度的成员信息泄露风险,需要进一步研究和开发相应的隐私保护机制。
📝 摘要(中文)
随着大型语言模型(LLM)日益融入临床决策支持、文档记录和患者信息系统,确保其隐私性和可信度已成为医疗保健领域的一项紧迫挑战。在敏感的电子健康记录(EHR)数据上微调LLM可以提高领域对齐性,但也增加了通过模型行为暴露患者信息的风险。本研究初步探讨了临床LLM中的成员推理漏洞,重点关注攻击者是否可以推断出特定患者记录是否被用于模型训练。我们使用最先进的临床问答模型Llemr,评估了基于损失的典型攻击和基于释义的扰动策略,后者更真实地反映了临床对抗条件。初步结果表明,存在有限但可衡量的成员信息泄露,表明当前的临床LLM提供了一定的抵抗力,但仍然容易受到细微的隐私风险的影响,这些风险可能会削弱对临床AI应用的信任。这些结果促使我们继续开发上下文感知、领域特定的隐私评估和防御方法,例如差分隐私微调和释义感知训练,以加强医疗保健AI系统的安全性和可信度。
🔬 方法详解
问题定义:论文旨在研究临床大语言模型(LLM)在训练过程中是否会泄露患者的隐私信息。现有的方法主要集中在通用领域的LLM,缺乏针对临床场景的特定评估。此外,现有的攻击方法可能无法真实反映临床对抗环境,例如,直接修改电子病历数据在现实中很难实现。
核心思路:论文的核心思路是通过成员推理攻击来评估临床LLM的隐私风险。成员推理攻击旨在判断一个给定的数据样本是否被用于训练模型。如果攻击者能够成功推断出某个患者的记录被用于训练模型,则表明该模型存在隐私泄露的风险。论文还提出了一种基于释义的扰动策略,模拟临床场景中攻击者可能采取的手段。
技术框架:论文使用临床问答模型Llemr作为研究对象。Llemr是一个在临床数据上微调的LLM,用于回答临床问题。论文首先使用基于损失的典型攻击方法,即通过比较模型在目标样本和非目标样本上的损失值来判断目标样本是否为训练集成员。然后,论文提出了一种基于释义的扰动策略,通过对问题进行释义来生成新的问题,并观察模型在原始问题和释义问题上的表现差异,以此来判断目标样本是否为训练集成员。
关键创新:论文的关键创新在于提出了针对临床场景的基于释义的扰动策略。这种策略更符合临床实际情况,因为攻击者可能无法直接访问原始的电子病历数据,但可以通过释义问题来获取信息。此外,论文还首次对临床LLM的成员推理漏洞进行了系统的评估,为后续的研究提供了参考。
关键设计:在基于损失的攻击中,论文使用了标准的损失函数,例如交叉熵损失。在基于释义的扰动策略中,论文使用了多种释义方法,例如同义词替换、句子重组等。论文还设计了一系列指标来评估攻击的成功率,例如准确率、精确率、召回率等。
🖼️ 关键图片

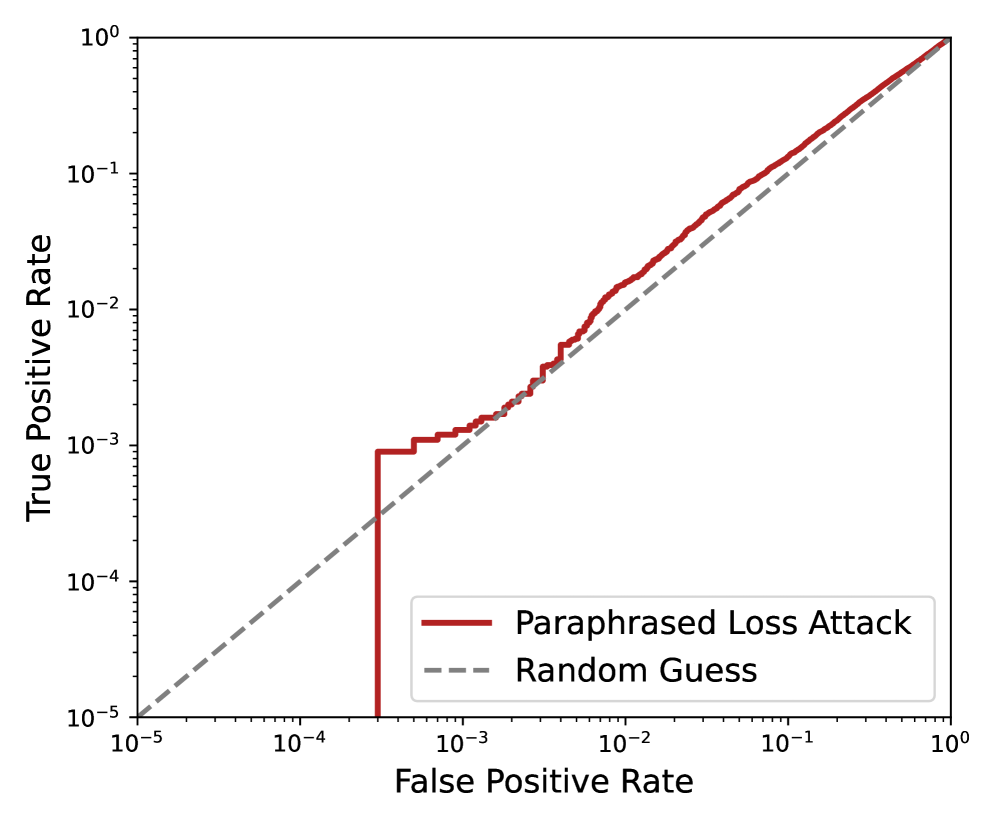

📊 实验亮点
实验结果表明,即使是最先进的临床问答模型Llemr也存在一定程度的成员信息泄露风险。基于损失的攻击和基于释义的扰动策略均能成功推断出部分训练集成员。虽然泄露程度有限,但足以引起重视,并促使我们进一步研究和开发更有效的隐私保护机制。基于释义的扰动策略在一定程度上优于传统的基于损失的攻击,更贴近真实的临床对抗环境。
🎯 应用场景
该研究成果可应用于评估和改进临床大语言模型的隐私保护能力,指导医疗机构安全地使用AI技术。通过识别和修复模型中的隐私漏洞,可以提高患者对AI辅助医疗系统的信任度,促进AI技术在医疗领域的广泛应用。未来的研究可以进一步探索差分隐私微调和释义感知训练等防御方法,以构建更加安全可靠的医疗AI系统。
📄 摘要(原文)
As large language models (LLMs) become progressively more embedded in clinical decision-support, documentation, and patient-information systems, ensuring their privacy and trustworthiness has emerged as an imperative challenge for the healthcare sector. Fine-tuning LLMs on sensitive electronic health record (EHR) data improves domain alignment but also raises the risk of exposing patient information through model behaviors. In this work-in-progress, we present an exploratory empirical study on membership inference vulnerabilities in clinical LLMs, focusing on whether adversaries can infer if specific patient records were used during model training. Using a state-of-the-art clinical question-answering model, Llemr, we evaluate both canonical loss-based attacks and a domain-motivated paraphrasing-based perturbation strategy that more realistically reflects clinical adversarial conditions. Our preliminary findings reveal limited but measurable membership leakage, suggesting that current clinical LLMs provide partial resistance yet remain susceptible to subtle privacy risks that could undermine trust in clinical AI adoption. These results motivate continued development of context-aware, domain-specific privacy evaluations and defenses such as differential privacy fine-tuning and paraphrase-aware training, to strengthen the security and trustworthiness of healthcare AI systems.