Extracting alignment data in open models
作者: Federico Barbero, Xiangming Gu, Christopher A. Choquette-Choo, Chawin Sitawarin, Matthew Jagielski, Itay Yona, Petar Veličković, Ilia Shumailov, Jamie Hayes
分类: cs.AI
发布日期: 2025-10-21 (更新: 2025-10-23)
💡 一句话要点
提出一种从后训练模型中提取对齐训练数据的方法,用于提升模型能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对齐训练数据提取 嵌入模型 语义相似性 模型记忆 数据隐私 蒸馏训练 大型语言模型
📋 核心要点
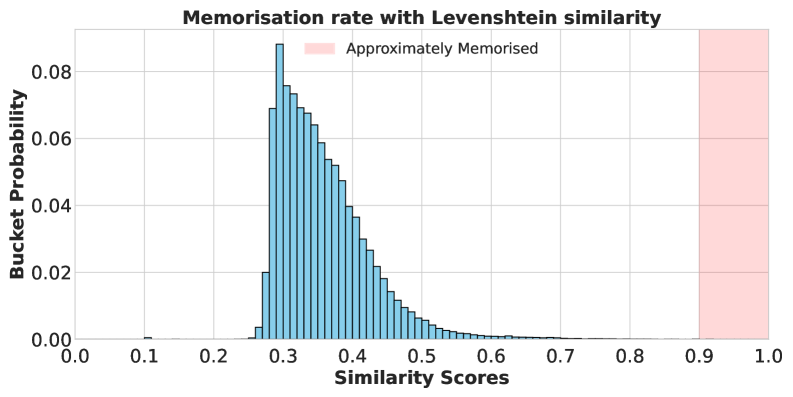
- 现有方法在评估训练数据提取时,过度依赖字符串匹配,忽略了语义相似性。
- 利用高质量嵌入模型,通过语义相似性来识别和提取后训练模型中的对齐数据。
- 实验表明,提取的对齐数据可用于训练基础模型,并恢复原始性能,揭示了潜在风险。
📝 摘要(中文)
本文展示了从后训练模型中提取大量对齐训练数据的可行性。这些数据可用于引导模型,提升其在长文本推理、安全性、指令遵循和数学等方面的能力。与以往主要通过字符串匹配来评估训练数据提取效果的研究不同,本文认为嵌入模型更适合此目标。高质量嵌入模型能够识别字符串之间的语义相似性,而编辑距离等其他指标难以捕捉。研究发现,模型容易重复使用后训练阶段(如SFT或RL)中使用过的训练数据。这些数据可用于训练基础模型,恢复相当一部分原始性能。这项工作揭示了提取对齐数据可能存在的风险。此外,该研究引发了关于蒸馏实践的下游影响的讨论:由于模型似乎在重复训练集的某些方面,因此蒸馏可以被认为是在间接训练模型的原始数据集。
🔬 方法详解
问题定义:论文旨在解决从已经过对齐训练(例如SFT或RL)的模型中提取用于对齐的训练数据的问题。现有方法主要依赖于字符串匹配,例如编辑距离,来判断模型是否“记住”了训练数据。然而,这种方法忽略了语义相似性,导致低估了实际可以提取的数据量。现有方法难以捕捉到由于细微的文本变化(例如拼写错误、同义词替换等)而产生的语义相似性。
核心思路:论文的核心思路是利用高质量的嵌入模型来度量文本之间的语义相似性,从而更准确地识别和提取模型中存在的对齐训练数据。通过嵌入模型,即使文本存在细微的差异,只要语义相似,就可以被识别为来自同一训练数据。
技术框架:论文的技术框架主要包含以下几个步骤:1)从目标模型中提取文本片段;2)使用高质量的嵌入模型(例如,Sentence Transformers)将提取的文本片段转换为向量表示;3)计算这些向量表示之间的相似度;4)根据相似度阈值,判断这些文本片段是否来自同一训练数据;5)将识别出的训练数据用于重新训练基础模型,并评估其性能。
关键创新:论文的关键创新在于使用嵌入模型来评估训练数据的提取,而不是传统的字符串匹配方法。这种方法能够更好地捕捉语义相似性,从而更准确地识别和提取对齐训练数据。此外,论文还揭示了后训练阶段(如SFT或RL)的模型更容易重复使用训练数据,这为研究模型记忆和数据隐私带来了新的视角。
关键设计:论文的关键设计包括:1)选择高质量的嵌入模型,确保能够准确捕捉文本的语义信息;2)设置合适的相似度阈值,以平衡提取数据的准确性和召回率;3)使用提取的对齐数据重新训练基础模型,并评估其在各种任务上的性能,以验证提取数据的有效性。论文没有详细说明具体的损失函数或网络结构,因为重点在于数据提取方法本身。
🖼️ 关键图片
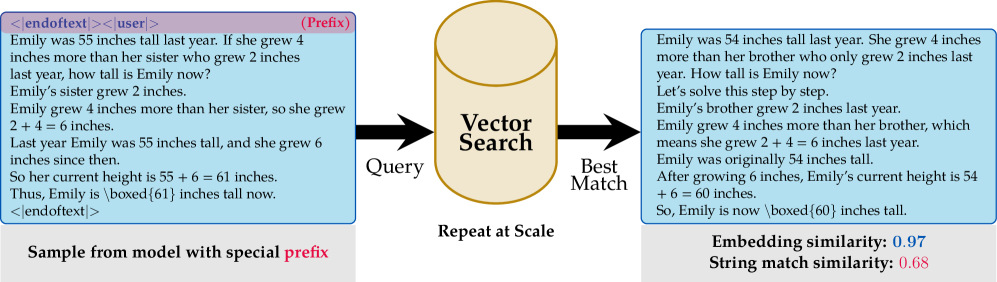

📊 实验亮点
实验结果表明,使用嵌入模型提取的对齐数据量远大于使用字符串匹配方法提取的数据量(保守估计为10倍)。此外,使用提取的对齐数据重新训练基础模型后,能够恢复相当一部分原始性能,证明了提取数据的有效性。这些结果表明,模型更容易重复使用后训练阶段的训练数据。
🎯 应用场景
该研究成果可应用于评估大型语言模型的安全性和隐私风险,特别是关于模型是否会泄露训练数据。此外,该方法还可以用于分析蒸馏训练过程,了解蒸馏模型是否间接学习了原始模型的训练数据。这对于开发更安全、更可靠的语言模型具有重要意义。
📄 摘要(原文)
In this work, we show that it is possible to extract significant amounts of alignment training data from a post-trained model -- useful to steer the model to improve certain capabilities such as long-context reasoning, safety, instruction following, and maths. While the majority of related work on memorisation has focused on measuring success of training data extraction through string matching, we argue that embedding models are better suited for our specific goals. Distances measured through a high quality embedding model can identify semantic similarities between strings that a different metric such as edit distance will struggle to capture. In fact, in our investigation, approximate string matching would have severely undercounted (by a conservative estimate of $10\times$) the amount of data that can be extracted due to trivial artifacts that deflate the metric. Interestingly, we find that models readily regurgitate training data that was used in post-training phases such as SFT or RL. We show that this data can be then used to train a base model, recovering a meaningful amount of the original performance. We believe our work exposes a possibly overlooked risk towards extracting alignment data. Finally, our work opens up an interesting discussion on the downstream effects of distillation practices: since models seem to be regurgitating aspects of their training set, distillation can therefore be thought of as indirectly training on the model's original dataset.