LAFA: Agentic LLM-Driven Federated Analytics over Decentralized Data Sources
作者: Haichao Ji, Zibo Wang, Cheng Pan, Meng Han, Yifei Zhu, Dan Wang, Zhu Han
分类: cs.AI, cs.CR, cs.DC, cs.MA
发布日期: 2025-10-21 (更新: 2025-10-30)
备注: This paper has been accepted by the 16th IEEE International Conference on Cloud Computing Technology and Science (CloudCom 2025)
💡 一句话要点
LAFA:基于Agentic LLM的去中心化数据联邦分析框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦分析 大型语言模型 自然语言处理 多Agent系统 隐私保护
📋 核心要点
- 现有基于LLM的分析框架依赖集中式数据访问,缺乏隐私保护,无法直接应用于分布式数据场景。
- LAFA提出一种分层多agent架构,将自然语言查询转化为优化的联邦分析工作流,实现隐私保护的数据分析。
- 实验结果表明,LAFA在执行计划成功率和资源利用率方面显著优于基线方法,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLMs)在自动化数据分析任务方面展现出巨大潜力,它们能够解释自然语言查询并生成多操作执行计划。然而,现有的基于LLM-agent的分析框架通常假设集中式数据访问,几乎不提供隐私保护。相比之下,联邦分析(FA)支持跨分布式数据源的隐私保护计算,但缺乏对自然语言输入的支持,并且需要结构化的、机器可读的查询。本文提出了LAFA,这是第一个将基于LLM-agent的数据分析与FA集成的系统。LAFA引入了一种分层多agent架构,该架构接受自然语言查询,并将其转换为优化的、可执行的FA工作流。一个粗粒度规划器首先将复杂查询分解为子查询,而一个细粒度规划器使用先验结构知识将每个子查询映射到FA操作的有向无环图(DAG)。为了提高执行效率,优化器agent重写和合并多个DAG,消除冗余操作并最小化计算和通信开销。实验表明,LAFA始终优于基线提示策略,实现了更高的执行计划成功率,并大幅减少了资源密集型FA操作。这项工作为隐私保护的、LLM驱动的分析奠定了实践基础,该分析支持FA环境中的自然语言输入。
🔬 方法详解
问题定义:论文旨在解决联邦分析(FA)中缺乏自然语言输入支持和现有LLM-agent框架缺乏隐私保护的问题。现有方法要么需要结构化的机器可读查询,要么假设集中式数据访问,无法满足分布式数据场景下隐私保护和易用性的需求。
核心思路:论文的核心思路是利用LLM的自然语言理解和生成能力,构建一个多agent系统,将自然语言查询转化为可执行的联邦分析工作流。通过分层规划和优化,在保证隐私的前提下,提高联邦分析的效率。
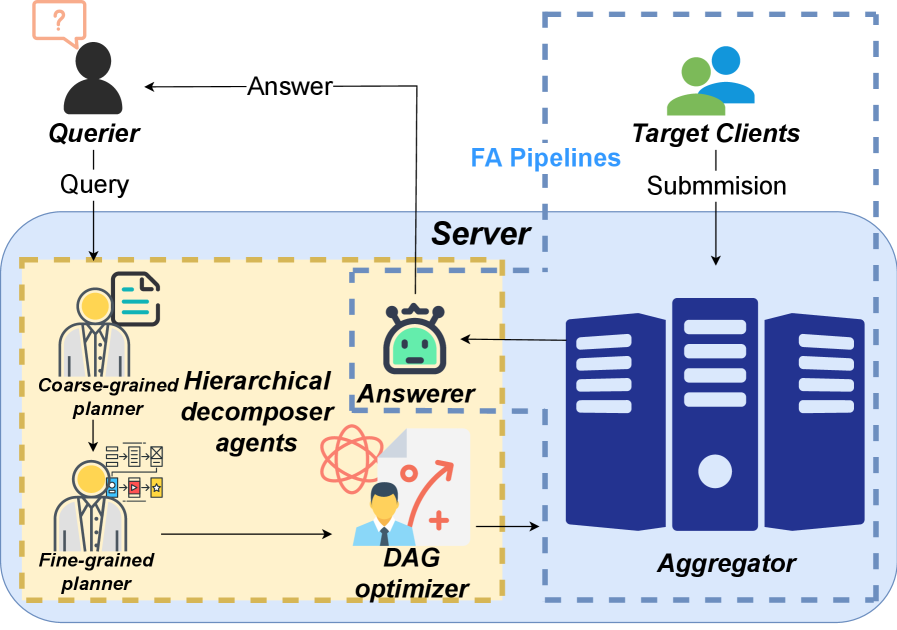
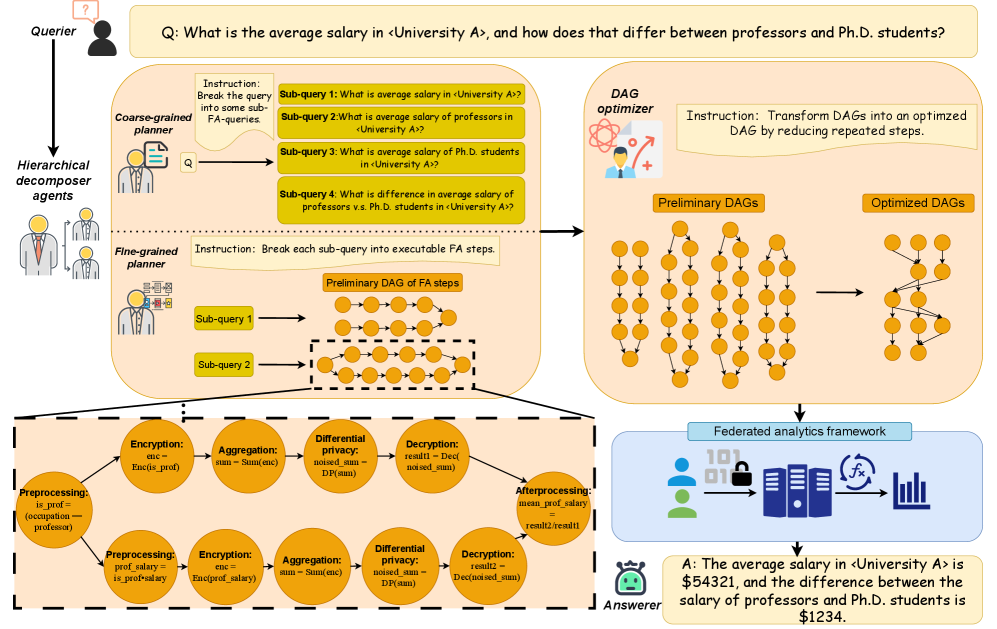
技术框架:LAFA采用分层多agent架构,包含以下主要模块: 1. 粗粒度规划器:将复杂的自然语言查询分解为多个子查询。 2. 细粒度规划器:将每个子查询映射为FA操作的有向无环图(DAG)。 3. 优化器agent:重写和合并多个DAG,消除冗余操作,最小化计算和通信开销。 整个流程是从自然语言查询开始,经过层层转化和优化,最终生成可在联邦环境下执行的分析计划。
关键创新:LAFA的关键创新在于将LLM-agent技术与联邦分析相结合,实现了自然语言驱动的隐私保护数据分析。通过分层规划和优化,解决了自然语言查询到联邦分析工作流的自动转换问题,并提高了执行效率。与现有方法相比,LAFA无需人工编写结构化查询,并能有效保护数据隐私。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。粗粒度规划器和细粒度规划器如何利用LLM的知识和推理能力,以及优化器agent的具体优化策略(例如,如何判断和消除冗余操作,如何平衡计算和通信开销)等细节未知。
🖼️ 关键图片
📊 实验亮点
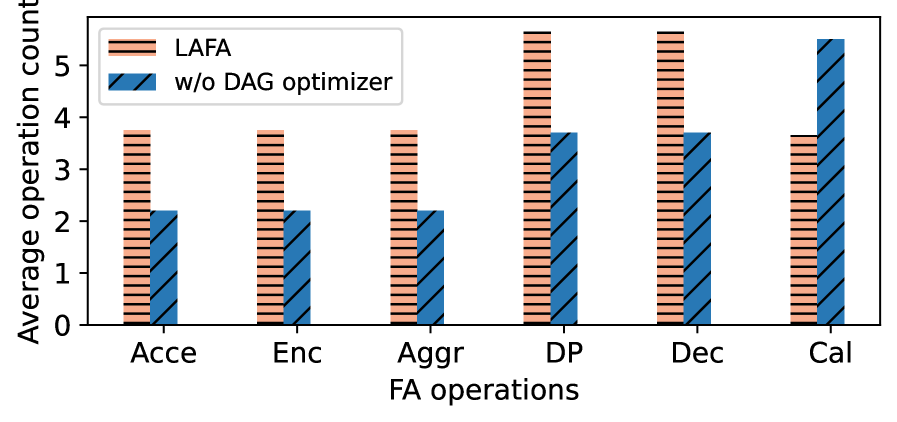
实验结果表明,LAFA在执行计划成功率方面显著优于基线提示策略。此外,LAFA能够大幅减少资源密集型FA操作,降低计算和通信开销。具体的性能提升幅度在论文中没有给出明确的数值,但总体而言,LAFA在效率和准确性方面都优于现有方法。
🎯 应用场景
LAFA可应用于金融、医疗、物联网等涉及大量分布式数据和隐私保护需求的领域。例如,在医疗领域,LAFA可以帮助医生利用分布在不同医院的患者数据进行疾病诊断和治疗方案优化,同时保护患者隐私。在金融领域,LAFA可以用于风险评估、反欺诈等应用,利用分布在不同机构的数据进行分析,提高模型的准确性和可靠性。
📄 摘要(原文)
Large Language Models (LLMs) have shown great promise in automating data analytics tasks by interpreting natural language queries and generating multi-operation execution plans. However, existing LLM-agent-based analytics frameworks operate under the assumption of centralized data access, offering little to no privacy protection. In contrast, federated analytics (FA) enables privacy-preserving computation across distributed data sources, but lacks support for natural language input and requires structured, machine-readable queries. In this work, we present LAFA, the first system that integrates LLM-agent-based data analytics with FA. LAFA introduces a hierarchical multi-agent architecture that accepts natural language queries and transforms them into optimized, executable FA workflows. A coarse-grained planner first decomposes complex queries into sub-queries, while a fine-grained planner maps each subquery into a Directed Acyclic Graph of FA operations using prior structural knowledge. To improve execution efficiency, an optimizer agent rewrites and merges multiple DAGs, eliminating redundant operations and minimizing computational and communicational overhead. Our experiments demonstrate that LAFA consistently outperforms baseline prompting strategies by achieving higher execution plan success rates and reducing resource-intensive FA operations by a substantial margin. This work establishes a practical foundation for privacy-preserving, LLM-driven analytics that supports natural language input in the FA setting.