CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment
作者: Xue Jiang, Yihong Dong, Mengyang Liu, Hongyi Deng, Tian Wang, Yongding Tao, Rongyu Cao, Binhua Li, Zhi Jin, Wenpin Jiao, Fei Huang, Yongbin Li, Ge Li
分类: cs.SE, cs.AI, cs.CL
发布日期: 2025-10-21
💡 一句话要点
CodeRL+:通过执行语义对齐强化学习提升代码生成能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 强化学习 执行语义 语义对齐 大型语言模型
📋 核心要点
- 现有代码生成方法依赖二元奖励信号,难以有效对齐代码文本表示与执行语义,尤其在处理细微逻辑错误时。
- CodeRL+通过集成执行语义对齐到RLVR训练流程,使模型能够推断变量级执行轨迹,提供直接的语义学习信号。
- 实验表明,CodeRL+在代码生成、推理和测试输出生成任务上均优于现有方法,并能有效推广到不同RL算法和LLM。
📝 摘要(中文)
大型语言模型(LLMs)通过学习海量代码语料库在代码生成方面表现出色,但文本模式训练与形式执行语义所决定的功能正确性目标之间存在根本的语义差距。带有可验证奖励的强化学习(RLVR)方法试图利用执行测试用例的结果奖励来弥合这一差距。然而,仅仅依赖于二元的通过/失败信号对于在代码的文本表示和其执行语义之间建立良好对齐的连接是低效的,特别是对于代码中细微的逻辑错误。本文提出了CodeRL+,一种新颖的方法,将执行语义对齐集成到代码生成的RLVR训练流程中。CodeRL+使模型能够推断变量级别的执行轨迹,从而提供执行语义的直接学习信号。CodeRL+可以直接使用现有的on-policy rollout构建执行语义对齐,并与各种RL算法无缝集成。大量实验表明,CodeRL+优于后训练基线(包括RLVR和Distillation),在pass@1上实现了平均4.6%的相对改进。CodeRL+有效地推广到其他编码任务,在代码推理和测试输出生成基准测试中分别产生了15.5%和4.4%的更高准确率。CodeRL+在不同的RL算法和LLM中显示出强大的适用性。此外,探针分析提供了令人信服的证据,表明CodeRL+加强了代码的文本表示与其底层执行语义之间的对齐。
🔬 方法详解
问题定义:现有基于大型语言模型的代码生成方法,虽然能够从大量代码数据中学习,但模型训练的文本模式与代码实际执行的语义之间存在差距。传统的强化学习方法,例如RLVR,仅依赖于测试用例的通过/失败信号作为奖励,无法有效指导模型学习代码的深层语义,尤其是在代码存在细微逻辑错误时,奖励信号稀疏且难以区分。
核心思路:CodeRL+的核心思路是通过引入执行语义对齐,显式地将代码的执行过程信息融入到强化学习的训练过程中。具体来说,CodeRL+使模型能够推断变量级别的执行轨迹,从而提供更细粒度的、直接反映代码执行语义的学习信号。通过对齐代码的文本表示和执行语义,CodeRL+旨在弥合模型训练的文本模式与代码实际执行的功能正确性之间的差距。
技术框架:CodeRL+的整体框架是在现有的RLVR训练流程中加入执行语义对齐模块。该框架包含以下几个主要步骤:1) 使用大型语言模型生成代码;2) 执行生成的代码,并记录变量级别的执行轨迹;3) 基于执行轨迹构建执行语义对齐损失;4) 将执行语义对齐损失与RLVR的奖励信号结合,用于训练模型。CodeRL+可以与各种RL算法无缝集成,例如PPO等。
关键创新:CodeRL+最重要的创新点在于引入了执行语义对齐的概念,并将其应用到代码生成的强化学习训练中。与传统的RLVR方法仅依赖于二元奖励信号不同,CodeRL+通过显式地学习代码的执行语义,为模型提供了更丰富、更有效的学习信号。这种方法能够更好地指导模型生成功能正确的代码,尤其是在处理包含细微逻辑错误的代码时。
关键设计:CodeRL+的关键设计包括:1) 如何有效地记录和表示代码的执行轨迹;2) 如何构建执行语义对齐损失函数,以鼓励模型学习代码的执行语义;3) 如何将执行语义对齐损失与RLVR的奖励信号进行有效结合。具体来说,论文可能使用了某种形式的注意力机制或对比学习方法来构建执行语义对齐损失。此外,如何平衡执行语义对齐损失和RLVR奖励信号的权重也是一个重要的设计考虑。
🖼️ 关键图片
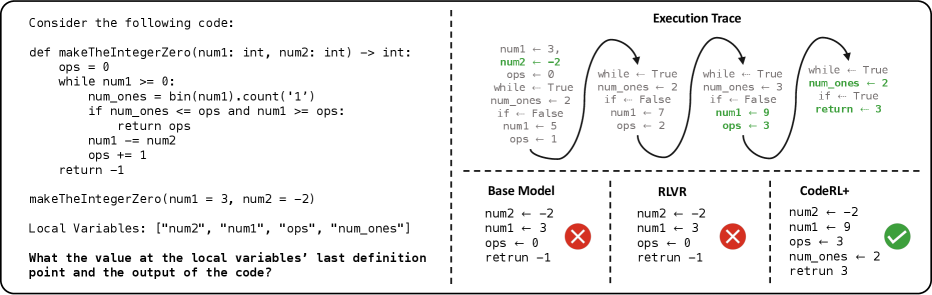
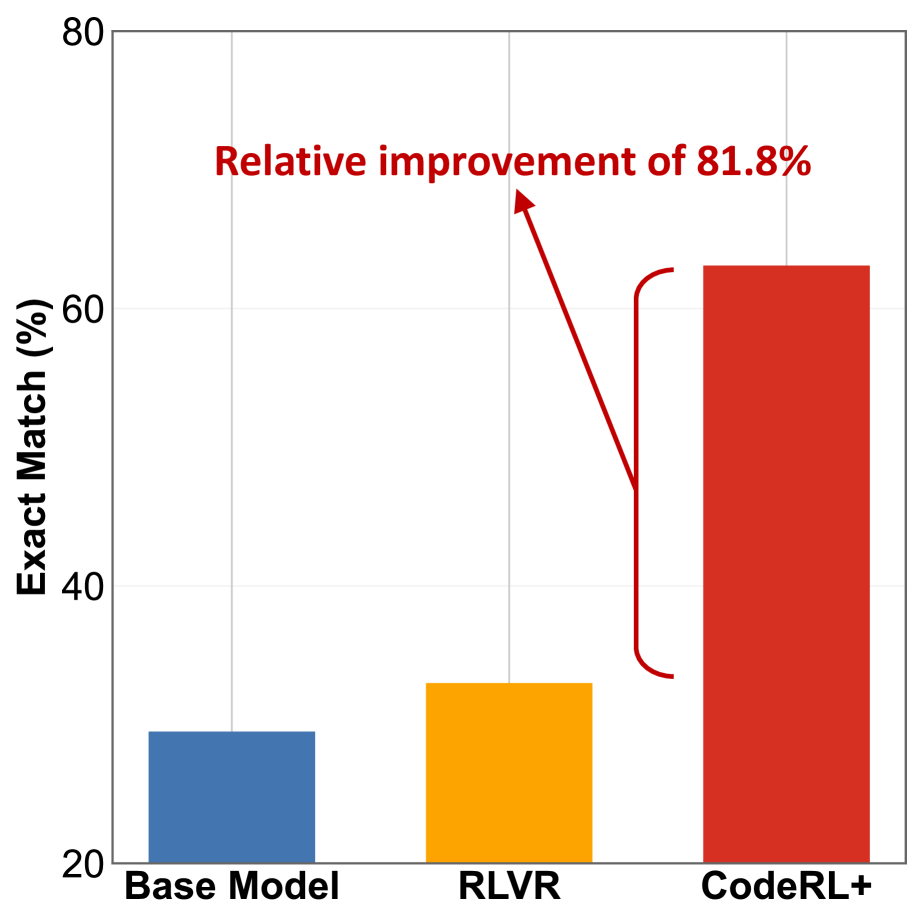
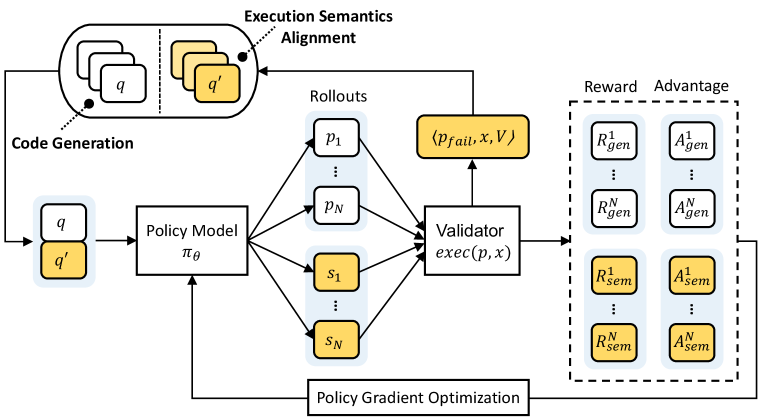
📊 实验亮点
实验结果表明,CodeRL+在代码生成任务上优于现有的RLVR和Distillation等基线方法,在pass@1指标上实现了平均4.6%的相对提升。此外,CodeRL+在代码推理和测试输出生成等其他编码任务上也取得了显著的性能提升,分别达到了15.5%和4.4%的准确率提升。探针分析也验证了CodeRL+能够有效加强代码的文本表示与其底层执行语义之间的对齐。
🎯 应用场景
CodeRL+在软件开发领域具有广泛的应用前景,可以用于自动化代码生成、代码补全、代码修复等任务。该方法能够提高生成代码的质量和可靠性,减少人工调试和测试的工作量。此外,CodeRL+还可以应用于教育领域,帮助学生更好地理解代码的执行过程和语义。
📄 摘要(原文)
While Large Language Models (LLMs) excel at code generation by learning from vast code corpora, a fundamental semantic gap remains between their training on textual patterns and the goal of functional correctness, which is governed by formal execution semantics. Reinforcement Learning with Verifiable Rewards (RLVR) approaches attempt to bridge this gap using outcome rewards from executing test cases. However, solely relying on binary pass/fail signals is inefficient for establishing a well-aligned connection between the textual representation of code and its execution semantics, especially for subtle logical errors within the code. In this paper, we propose CodeRL+, a novel approach that integrates execution semantics alignment into the RLVR training pipeline for code generation. CodeRL+ enables the model to infer variable-level execution trajectory, providing a direct learning signal of execution semantics. CodeRL+ can construct execution semantics alignment directly using existing on-policy rollouts and integrates seamlessly with various RL algorithms. Extensive experiments demonstrate that CodeRL+ outperforms post-training baselines (including RLVR and Distillation), achieving a 4.6% average relative improvement in pass@1. CodeRL+ generalizes effectively to other coding tasks, yielding 15.5% and 4.4% higher accuracy on code-reasoning and test-output-generation benchmarks, respectively. CodeRL+ shows strong applicability across diverse RL algorithms and LLMs. Furthermore, probe analyses provide compelling evidence that CodeRL+ strengthens the alignment between code's textual representations and its underlying execution semantics.