PlanU: Large Language Model Reasoning through Planning under Uncertainty
作者: Ziwei Deng, Mian Deng, Chenjing Liang, Zeming Gao, Chennan Ma, Chenxing Lin, Haipeng Zhang, Songzhu Mei, Siqi Shen, Cheng Wang
分类: cs.AI
发布日期: 2025-10-21 (更新: 2025-11-05)
备注: 38 pages, 19 figures, NeurIPS 2025 Accepted
💡 一句话要点
提出PlanU:通过不确定性下的规划增强大语言模型推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 不确定性推理 蒙特卡洛树搜索 决策规划 分位数回归
📋 核心要点
- 现有基于LLM的决策方法难以处理环境不确定性,导致在随机状态转移环境中表现不佳。
- PlanU通过在蒙特卡洛树搜索(MCTS)中建模不确定性,利用分位数分布表示节点回报,有效应对环境不确定性。
- 实验结果表明,PlanU在不确定性推理任务中表现出色,验证了其在LLM决策中的有效性。
📝 摘要(中文)
大语言模型(LLM)越来越多地被应用于各种推理任务。然而,LLM在不确定性下的推理任务中表现不佳,而这些任务对人类来说相对容易,例如在随机环境中规划行动。LLM在推理中的应用受到不确定性挑战的阻碍,包括LLM自身的不确定性和环境的不确定性。LLM的不确定性源于其固有的随机抽样过程。大多数基于LLM的决策(LDM)方法通过多重推理链或搜索树来解决LLM的不确定性。然而,这些方法忽略了环境的不确定性,导致在具有随机状态转移的环境中性能较差。一些最新的LDM方法通过预测未知变量的概率来处理不确定性。但是,它们并非为需要与环境交互的多步推理任务而设计。为了解决LLM决策中的不确定性,我们提出了一种基于LLM的规划方法PlanU,该方法在蒙特卡洛树搜索(MCTS)中捕获不确定性。PlanU将MCTS中每个节点的回报建模为分位数分布,该分布使用一组分位数来表示回报分布。为了平衡树搜索期间的探索和利用,PlanU引入了一个带有好奇心的上限置信区间(UCC)分数,该分数估计MCTS节点的不确定性。通过大量的实验,我们证明了PlanU在基于LLM的不确定性推理任务中的有效性。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)在不确定性环境下进行决策和规划时遇到的困难。现有方法,如多重推理链或搜索树,主要关注LLM自身的不确定性,而忽略了环境的不确定性,导致在状态转移具有随机性的环境中表现不佳。
核心思路:PlanU的核心思路是在蒙特卡洛树搜索(MCTS)框架下,将每个节点的回报建模为分位数分布,从而显式地捕捉和表示环境的不确定性。通过这种方式,PlanU能够更好地评估不同行动的潜在风险和收益,从而做出更稳健的决策。
技术框架:PlanU的整体框架基于MCTS,主要包括以下几个阶段:选择(Selection)、扩展(Expansion)、模拟(Simulation)和反向传播(Backpropagation)。在选择阶段,使用带有好奇心的上限置信区间(UCC)分数来平衡探索和利用。在扩展阶段,根据LLM的输出生成新的节点。在模拟阶段,根据环境的随机性进行状态转移。在反向传播阶段,更新节点的回报分布。
关键创新:PlanU的关键创新在于使用分位数分布来建模MCTS节点的回报。传统MCTS通常使用平均回报来评估节点,这无法捕捉回报的不确定性。分位数分布能够提供更丰富的信息,包括回报的范围、概率分布等,从而更好地应对环境的不确定性。此外,UCC分数的设计也考虑了节点的不确定性,鼓励探索不确定性高的节点。
关键设计:PlanU的关键设计包括:1) 使用一组分位数(例如,0.1、0.25、0.5、0.75、0.9)来表示回报分布;2) UCC分数的计算公式,它结合了节点的平均回报和不确定性估计;3) 如何利用LLM生成新的节点,例如,通过prompting LLM生成可能的行动序列。
🖼️ 关键图片
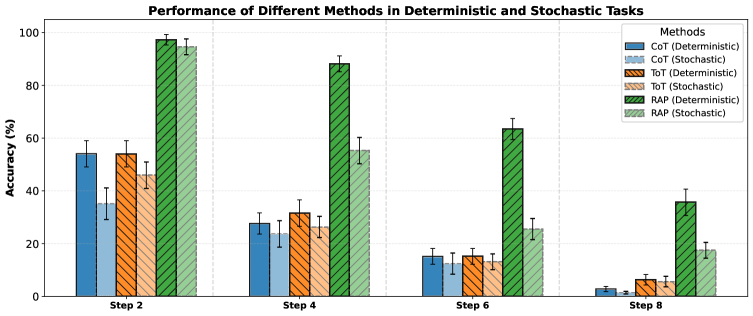


📊 实验亮点
论文通过实验验证了PlanU在不确定性推理任务中的有效性。实验结果表明,PlanU在多个benchmark上显著优于现有的基于LLM的决策方法。具体的性能提升数据需要在论文中查找,但总体趋势是PlanU能够更有效地应对环境不确定性,从而提高决策的准确性和鲁棒性。
🎯 应用场景
PlanU可应用于机器人导航、游戏AI、金融决策等涉及不确定环境的领域。例如,在机器人导航中,机器人需要在未知或部分已知的环境中规划路径,PlanU可以帮助机器人更好地应对传感器噪声、环境变化等不确定性因素,从而提高导航的成功率和效率。在金融决策中,PlanU可以帮助投资者评估不同投资策略的风险和收益,从而做出更明智的投资决策。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly being explored across a range of reasoning tasks. However, LLMs sometimes struggle with reasoning tasks under uncertainty that are relatively easy for humans, such as planning actions in stochastic environments. The adoption of LLMs for reasoning is impeded by uncertainty challenges, such as LLM uncertainty and environmental uncertainty. LLM uncertainty arises from the stochastic sampling process inherent to LLMs. Most LLM-based Decision-Making (LDM) approaches address LLM uncertainty through multiple reasoning chains or search trees. However, these approaches overlook environmental uncertainty, which leads to poor performance in environments with stochastic state transitions. Some recent LDM approaches deal with uncertainty by forecasting the probability of unknown variables. However, they are not designed for multi-step reasoning tasks that require interaction with the environment. To address uncertainty in LLM decision-making, we introduce PlanU, an LLM-based planning method that captures uncertainty within Monte Carlo Tree Search (MCTS). PlanU models the return of each node in the MCTS as a quantile distribution, which uses a set of quantiles to represent the return distribution. To balance exploration and exploitation during tree search, PlanU introduces an Upper Confidence Bounds with Curiosity (UCC) score which estimates the uncertainty of MCTS nodes. Through extensive experiments, we demonstrate the effectiveness of PlanU in LLM-based reasoning tasks under uncertainty.