Illusions of reflection: open-ended task reveals systematic failures in Large Language Models' reflective reasoning
作者: Sion Weatherhead, Flora Salim, Aaron Belbasis
分类: cs.AI, cs.LG
发布日期: 2025-10-21 (更新: 2025-10-23)
备注: Currently under review
🔗 代码/项目: GITHUB
💡 一句话要点
揭示大语言模型反思推理的系统性缺陷:开放任务下约束违反
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 反思推理 开放任务 约束违反 自我评价
📋 核心要点
- 现有大语言模型在封闭任务中表现出一定的反思能力,但在开放任务中,其反思能力不足以保证结果的有效性和约束性。
- 该研究通过设计开放式的科学测试题生成任务,并要求模型进行自我评价和修改,以此来评估大语言模型的反思推理能力。
- 实验结果表明,现有大语言模型在开放任务中的反思能力提升有限,且难以避免重复违反约束,表明其反思机制与人类存在显著差异。
📝 摘要(中文)
人类不仅在事后发现错误,还能在过程中及时纠正,因为“反思”与目标及其约束紧密相连。目前的大语言模型虽然能生成推理token和“反思”文本,但其功能是否等同于人类的反思推理?以往在封闭任务上的研究,由于存在明确的外部“正确性”信号,可能会使“反思”看起来有效,但掩盖了自我纠正的局限性。因此,本文在一项简单、真实且开放但受规则约束的任务上测试了八个前沿模型:生成有效的科学测试题,然后在考虑自身评价后进行修改。首次尝试表现不佳(通常4个要求中只有0个有效项目;平均值约为1),反思带来的提升也很有限(也约为1)。关键的是,第二次尝试经常重复相同的约束违反,表明“纠正性收益”主要来自偶然生成有效项目,而非错误检测和基于原则、对约束敏感的修复。随着开放性的增加,反思前后的性能都会下降,并且以“推理”为卖点的模型没有显示出优势。研究结果表明,当前LLM的“反思”缺乏主动的、目标驱动的监控的功能性证据,而这种监控有助于人类即使在第一次尝试时也能尊重约束。在模型本身实例化这种机制之前,可靠的性能需要强制执行约束的外部结构。
🔬 方法详解
问题定义:现有的大语言模型在封闭式任务中表现出一定的反思能力,但这种能力在开放式、规则约束的任务中是否仍然有效是一个问题。现有方法依赖于明确的外部正确性信号,可能掩盖了模型自我纠正的局限性。因此,需要一种新的方法来评估模型在更接近真实世界的场景下的反思推理能力。
核心思路:该论文的核心思路是设计一个开放式但受规则约束的任务,即生成有效的科学测试题,并要求模型在自我评价后进行修改。通过观察模型在首次尝试和反思后的表现,以及其对约束的遵守情况,来评估其反思推理能力。这种设计旨在模拟人类在解决问题时的主动监控和约束意识。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择八个前沿的大语言模型进行测试。2) 设计科学测试题生成任务,该任务要求模型生成符合特定规则和约束的测试题。3) 要求模型对生成的测试题进行自我评价。4) 根据自我评价的结果,模型对测试题进行修改。5) 对模型在首次尝试和反思后的表现进行评估,包括有效测试题的数量、约束违反情况等。
关键创新:该研究的关键创新在于其任务设计和评估方法。传统的反思评估方法通常依赖于封闭式任务和外部正确性信号,而该研究则采用开放式任务和内部自我评价,更真实地反映了模型在实际应用中的反思能力。此外,该研究还关注模型对约束的遵守情况,这对于评估模型的可靠性和安全性至关重要。
关键设计:该研究的关键设计包括:1) 科学测试题生成任务的规则和约束,这些规则和约束需要足够明确,以便模型能够理解和遵守。2) 自我评价的标准和方法,需要确保模型能够准确地评估其生成的测试题的质量。3) 评估指标的选择,需要能够全面地反映模型在首次尝试和反思后的表现,包括有效测试题的数量、约束违反情况等。
🖼️ 关键图片
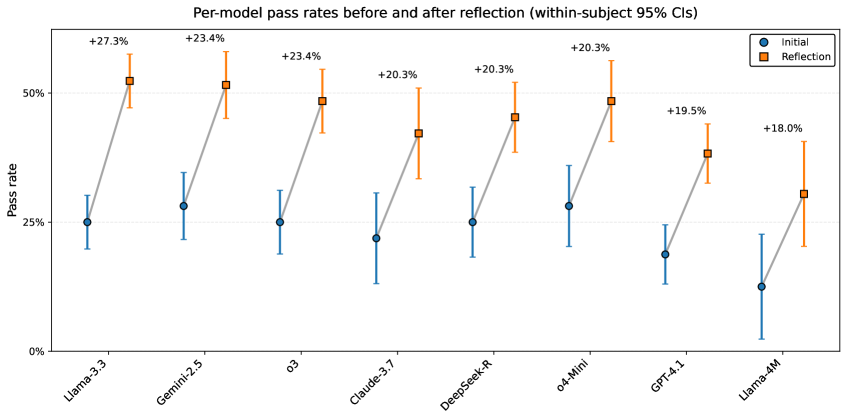


📊 实验亮点
实验结果表明,现有大语言模型在首次尝试时表现不佳,平均只能生成约1个有效测试题(满分4个)。反思后的提升也有限,仍然只能生成约1个有效测试题。更重要的是,模型经常重复违反相同的约束,表明其纠正性收益主要来自偶然因素,而非真正的错误检测和修复。随着任务开放性的增加,模型性能进一步下降,表明现有大语言模型的反思能力存在显著局限性。
🎯 应用场景
该研究的成果可以应用于评估和改进大语言模型的反思推理能力,提高其在开放式任务中的可靠性和安全性。例如,可以用于开发更智能的教育辅助工具,帮助学生生成和评估测试题。此外,该研究还可以为开发更可靠的AI系统提供指导,使其能够在复杂环境中更好地理解和遵守规则。
📄 摘要(原文)
Humans do not just find mistakes after the fact -- we often catch them mid-stream because 'reflection' is tied to the goal and its constraints. Today's large language models produce reasoning tokens and 'reflective' text, but is it functionally equivalent with human reflective reasoning? Prior work on closed-ended tasks -- with clear, external 'correctness' signals -- can make 'reflection' look effective while masking limits in self-correction. We therefore test eight frontier models on a simple, real-world task that is open-ended yet rule-constrained, with auditable success criteria: to produce valid scientific test items, then revise after considering their own critique. First-pass performance is poor (often zero valid items out of 4 required; mean $\approx$ 1), and reflection yields only modest gains (also $\approx$ 1). Crucially, the second attempt frequently repeats the same violation of constraint, indicating 'corrective gains' arise largely from chance production of a valid item rather than error detection and principled, constraint-sensitive repair. Performance before and after reflection deteriorates as open-endedness increases, and models marketed for 'reasoning' show no advantage. Our results suggest that current LLM 'reflection' lacks functional evidence of the active, goal-driven monitoring that helps humans respect constraints even on a first pass. Until such mechanisms are instantiated in the model itself, reliable performance requires external structure that enforces constraints. Our code is available at: https://github.com/cruiseresearchgroup/LLM_ReflectionTest