ssToken: Self-modulated and Semantic-aware Token Selection for LLM Fine-tuning
作者: Xiaohan Qin, Xiaoxing Wang, Ning Liao, Cancheng Zhang, Xiangdong Zhang, Mingquan Feng, Jingzhi Wang, Junchi Yan
分类: cs.AI
发布日期: 2025-10-21
💡 一句话要点
提出ssToken,通过自调制和语义感知选择token,提升LLM微调效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 监督微调 token选择 自调制学习 语义感知 注意力机制 模型优化 数据选择
📋 核心要点
- 现有token级别数据选择方法依赖额外参考模型或仅使用损失信息,忽略了语义重要性。
- ssToken利用历史模型计算损失差异作为自调制信号,并结合注意力机制进行语义感知选择。
- 实验表明,ssToken优于全数据微调和现有token选择方法,提升性能并保持训练效率。
📝 摘要(中文)
本文提出了一种自调制和语义感知的token选择方法ssToken,旨在提升大型语言模型(LLM)的监督微调(SFT)效果。现有token级别选择方法存在两个主要局限:需要训练或访问额外的参考模型;仅依赖损失信息进行token选择,无法很好地保留语义上重要的token。ssToken利用易于访问的历史模型计算当前模型每个token的损失差异,作为自调制信号,使模型能够自适应地选择token。此外,引入了一种基于注意力的语义感知token重要性估计指标,与基于损失的选择互补,提供更有效的语义信息过滤。大量实验表明,自调制选择和语义感知选择均优于全数据微调,而ssToken的集成实现了协同增益,超越了现有的token级别选择方法,在保持训练效率的同时提高了性能。
🔬 方法详解
问题定义:现有token级别数据选择方法在大型语言模型微调中表现出潜力,但存在两个主要痛点。一是需要额外的参考模型进行训练或访问,增加了计算成本和部署难度。二是仅依赖损失信息进行token选择,容易忽略那些语义重要但对损失贡献不大的token,导致模型学习到的知识不完整。
核心思路:ssToken的核心思路是利用模型自身的历史状态作为参考,通过计算当前模型与历史模型在每个token上的损失差异,得到一个自调制信号,用于自适应地选择token。同时,引入语义感知机制,利用注意力权重估计token的重要性,弥补损失信息在语义层面的不足。这样既避免了额外参考模型的依赖,又能够更全面地选择对模型学习有益的token。
技术框架:ssToken主要包含两个模块:自调制选择模块和语义感知选择模块。首先,自调制选择模块计算当前模型和历史模型在每个token上的损失差异,得到自调制信号。然后,语义感知选择模块利用注意力机制计算每个token的重要性得分。最后,将两个模块的结果进行融合,得到最终的token选择概率,并根据概率选择用于微调的token子集。
关键创新:ssToken的关键创新在于提出了自调制选择机制和语义感知选择机制。自调制选择机制避免了对额外参考模型的依赖,降低了计算成本。语义感知选择机制弥补了损失信息在语义层面的不足,提高了token选择的准确性。两个机制的结合使得ssToken能够更有效地选择对模型学习有益的token。
关键设计:在自调制选择模块中,历史模型的选择策略是一个关键设计。论文中可能采用了滑动平均或者周期性保存等方法来维护历史模型。在语义感知选择模块中,注意力权重的计算方式以及如何将注意力权重与损失差异进行融合是关键设计。此外,token选择概率的阈值设置也会影响最终的微调效果。具体的损失函数和网络结构细节需要参考论文原文。
🖼️ 关键图片


📊 实验亮点
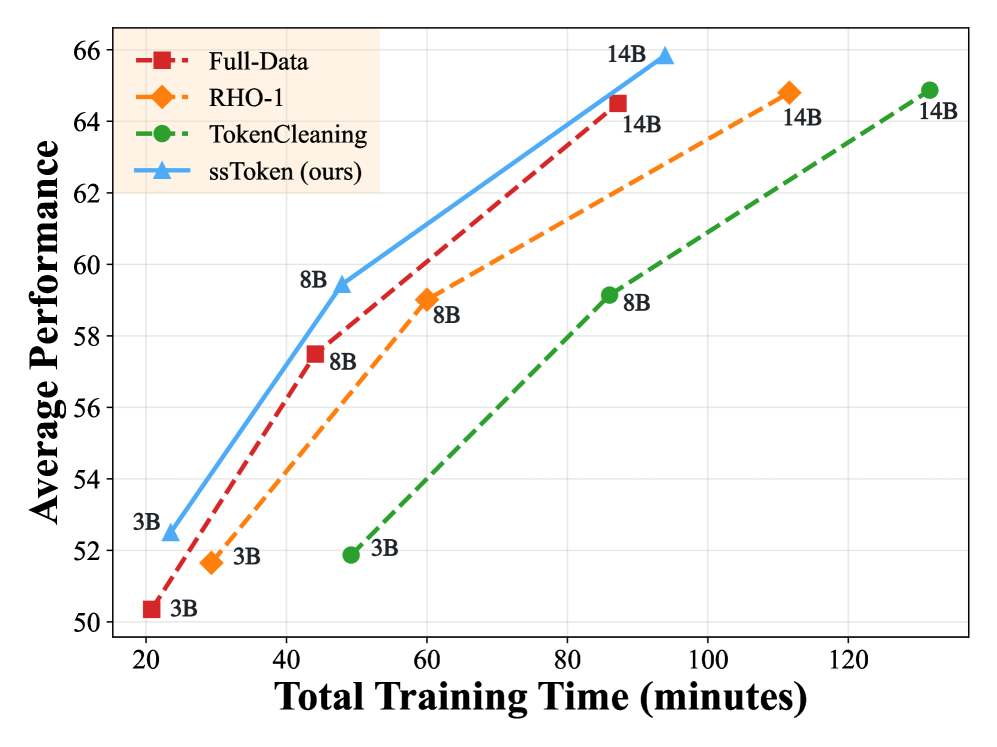
实验结果表明,ssToken在不同模型家族和规模上均取得了显著的性能提升。自调制选择和语义感知选择单独使用时均优于全数据微调。ssToken集成了两种选择机制,实现了协同增益,超越了现有的token级别选择方法。具体性能数据和对比基线需要在论文原文中查找。
🎯 应用场景
ssToken可应用于各种大型语言模型的微调场景,尤其适用于计算资源有限或难以获取高质量参考模型的环境。该方法能够提升模型在特定任务上的性能,例如文本生成、情感分析、问答系统等,并可降低微调过程中的计算成本和数据需求。未来,ssToken有望推广到更多自然语言处理任务和模型架构中。
📄 摘要(原文)
Data quality plays a critical role in enhancing supervised fine-tuning (SFT) for large language models (LLMs), and token-level data selection has emerged as a promising direction for its fine-grained nature. Despite their strong empirical performance, existing token-level selection methods share two key limitations: (1) requiring training or accessing an additional reference model, and (2) relying solely on loss information for token selection, which cannot well preserve semantically important tokens that are not favored by loss-based metrics. To address these challenges, we propose ssToken, a Self-modulated and Semantic-aware Token Selection approach. ssToken leverages readily accessible history models to compute the per-token loss difference with the current model, which serves as a self-modulated signal that enables the model to adaptively select tokens along its optimization trajectory, rather than relying on excess loss from an offline-trained reference model as in prior works. We further introduce a semantic-aware, attention-based token importance estimation metric, orthogonal to loss-based selection and providing complementary semantic information for more effective filtering. Extensive experiments across different model families and scales demonstrate that both self-modulated selection and semantic-aware selection alone outperform full-data fine-tuning, while their integration--ssToken--achieves synergistic gains and further surpasses prior token-level selection methods, delivering performance improvements while maintaining training efficiency.