Network and Systems Performance Characterization of MCP-Enabled LLM Agents
作者: Zihao Ding, Mufeng Zhu, Yao Liu
分类: cs.DC, cs.AI, cs.CL, cs.NI, cs.SE
发布日期: 2025-10-20
💡 一句话要点
针对MCP赋能的LLM Agent,分析其网络与系统性能瓶颈并提出优化建议
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型上下文协议 LLM Agent 性能分析 成本优化
📋 核心要点
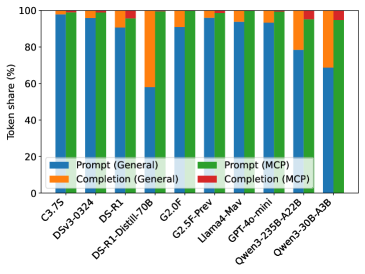
- 现有MCP赋能的LLM Agent交互因上下文信息膨胀导致token使用量激增,带来成本和计算负担。
- 通过测量分析不同LLM模型和MCP配置对性能指标的影响,揭示能力、性能和成本间的权衡。
- 提出并行工具调用和任务中止机制等优化方案,旨在提升MCP赋能工作流程的效率和鲁棒性。
📝 摘要(中文)
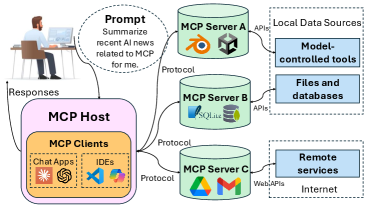
本文针对模型上下文协议(MCP)赋能的大语言模型(LLM)交互进行了全面的基于测量的分析。MCP通过提供一种标准化的方式,使LLM能够与外部工具和服务交互,从而显著增强其能力。然而,在MCP赋能的LLM交互中,大量的上下文信息(包括系统提示、MCP工具定义和上下文历史)会显著增加token的使用量。鉴于LLM提供商按token收费,这种扩展的上下文可能会迅速增加经济成本,并增加LLM服务的计算负载。本文揭示了能力、性能和成本之间的权衡。我们探讨了不同的LLM模型和MCP配置如何影响关键性能指标,如token效率、货币成本、任务完成时间和任务成功率,并提出了潜在的优化方案,包括启用并行工具调用和实施稳健的任务中止机制。这些发现为开发更高效、更稳健、更具成本效益的MCP赋能工作流程提供了有用的见解。
🔬 方法详解
问题定义:论文旨在解决MCP赋能的LLM Agent在实际应用中,由于上下文信息量大导致的token使用效率低、成本高昂以及计算负载过重的问题。现有方法缺乏对这些性能瓶颈的系统性分析和优化策略,使得MCP的优势难以充分发挥。
核心思路:论文的核心思路是通过对MCP赋能的LLM交互进行全面的测量分析,量化不同因素(如LLM模型选择、MCP配置等)对token效率、成本、任务完成时间和成功率的影响。基于分析结果,提出针对性的优化策略,以在能力、性能和成本之间取得平衡。
技术框架:论文采用实验测量的方法,构建了MCP赋能的LLM Agent交互环境,并设计了一系列实验来评估不同配置下的性能表现。主要流程包括:1) 定义实验任务和评估指标;2) 选择不同的LLM模型和MCP配置;3) 运行实验并收集性能数据;4) 分析数据并识别性能瓶颈;5) 提出优化策略并验证其有效性。
关键创新:论文的关键创新在于对MCP赋能的LLM Agent的性能进行了系统性的量化分析,并提出了实用的优化建议。与现有方法相比,该研究更注重实际应用中的性能瓶颈,并提供了可操作的优化方案,例如并行工具调用和任务中止机制。
关键设计:论文的关键设计包括:1) 针对不同任务设计了合理的评估指标,如token效率、成本、任务完成时间和成功率;2) 选择了具有代表性的LLM模型和MCP配置进行实验;3) 提出了并行工具调用机制,允许LLM同时调用多个工具,从而减少总的交互轮数和时间;4) 提出了任务中止机制,可以在任务失败或超出预算时及时中止任务,避免浪费资源。
🖼️ 关键图片
📊 实验亮点
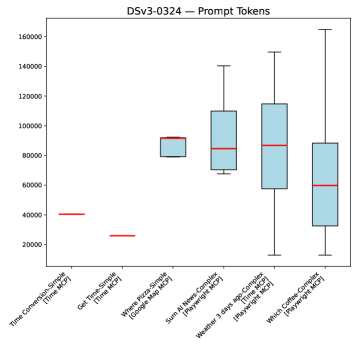
实验结果表明,不同的LLM模型和MCP配置对性能指标有显著影响。例如,某些模型在特定任务上表现出更高的token效率,而并行工具调用机制可以显著减少任务完成时间。通过实施任务中止机制,可以在任务失败时避免不必要的成本支出。这些发现为优化MCP赋能的LLM Agent提供了数据支持。
🎯 应用场景
该研究成果可应用于各种需要LLM与外部工具交互的场景,例如智能客服、自动化流程、数据分析等。通过优化MCP配置,可以降低token成本,提高任务完成效率和成功率,从而提升LLM Agent的实用性和经济性。未来,该研究可以扩展到更复杂的任务和更广泛的LLM模型,为构建更智能、更高效的AI系统提供指导。
📄 摘要(原文)
Model Context Protocol (MCP) has recently gained increased attention within the AI community for providing a standardized way for large language models (LLMs) to interact with external tools and services, significantly enhancing their capabilities. However, the inclusion of extensive contextual information, including system prompts, MCP tool definitions, and context histories, in MCP-enabled LLM interactions, dramatically inflates token usage. Given that LLM providers charge based on tokens, these expanded contexts can quickly escalate monetary costs and increase the computational load on LLM services. This paper presents a comprehensive measurement-based analysis of MCP-enabled interactions with LLMs, revealing trade-offs between capability, performance, and cost. We explore how different LLM models and MCP configurations impact key performance metrics such as token efficiency, monetary cost, task completion times, and task success rates, and suggest potential optimizations, including enabling parallel tool calls and implementing robust task abort mechanisms. These findings provide useful insights for developing more efficient, robust, and cost-effective MCP-enabled workflows.