CourtGuard: A Local, Multiagent Prompt Injection Classifier
作者: Isaac Wu, Michael Maslowski
分类: cs.CR, cs.AI
发布日期: 2025-10-20
备注: 11 pages, 7 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出CourtGuard:一种本地化、多智能体提示注入分类器,降低误报率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示注入攻击 大型语言模型安全 多智能体系统 对抗性提示 LLM防御
📋 核心要点
- 大型语言模型面临提示注入攻击威胁,可能导致信息泄露和有害行为,现有防御方法存在不足。
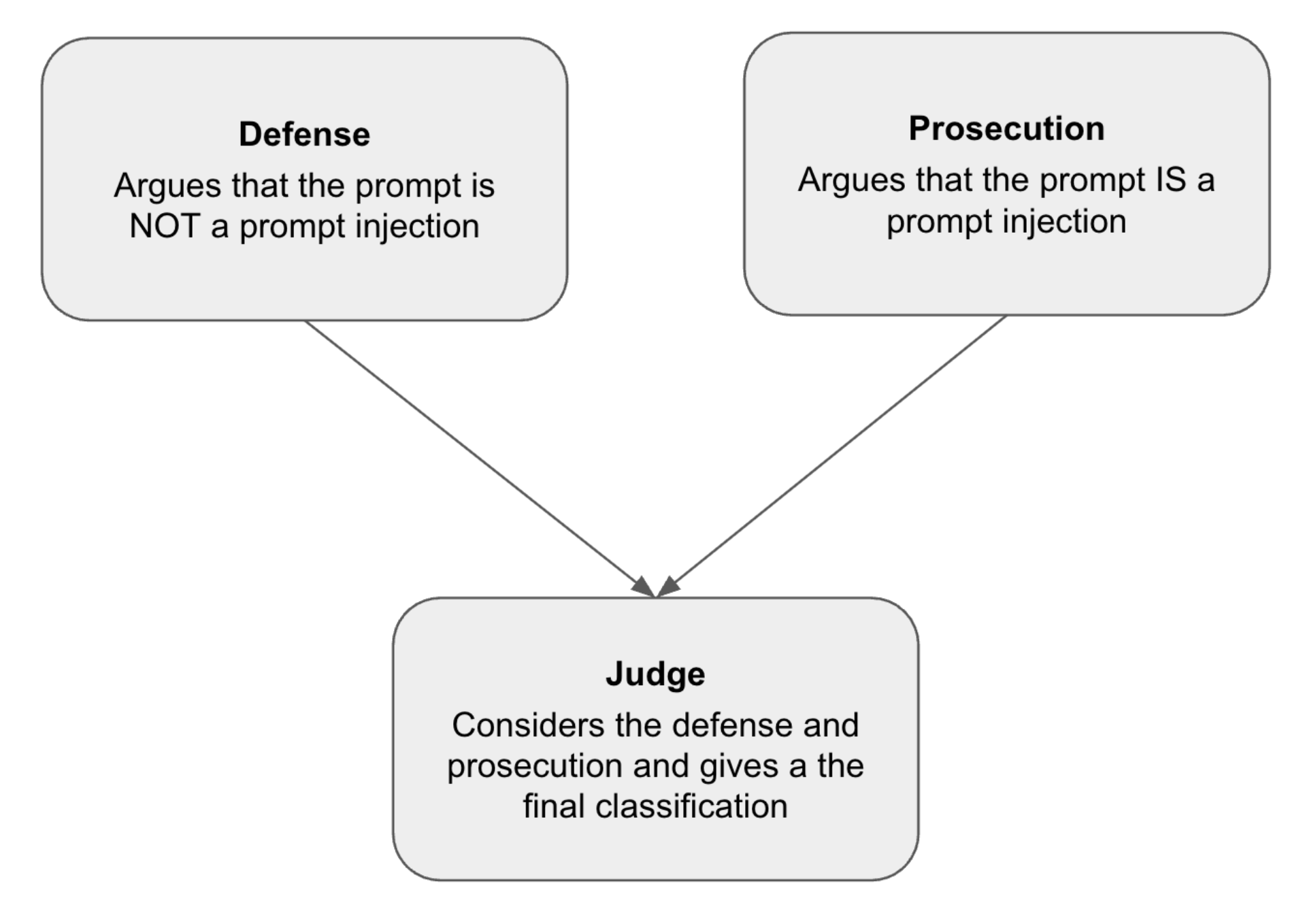
- CourtGuard采用多智能体系统,模拟法庭辩论,通过辩护律师、检察官和法官协同判断提示的安全性。
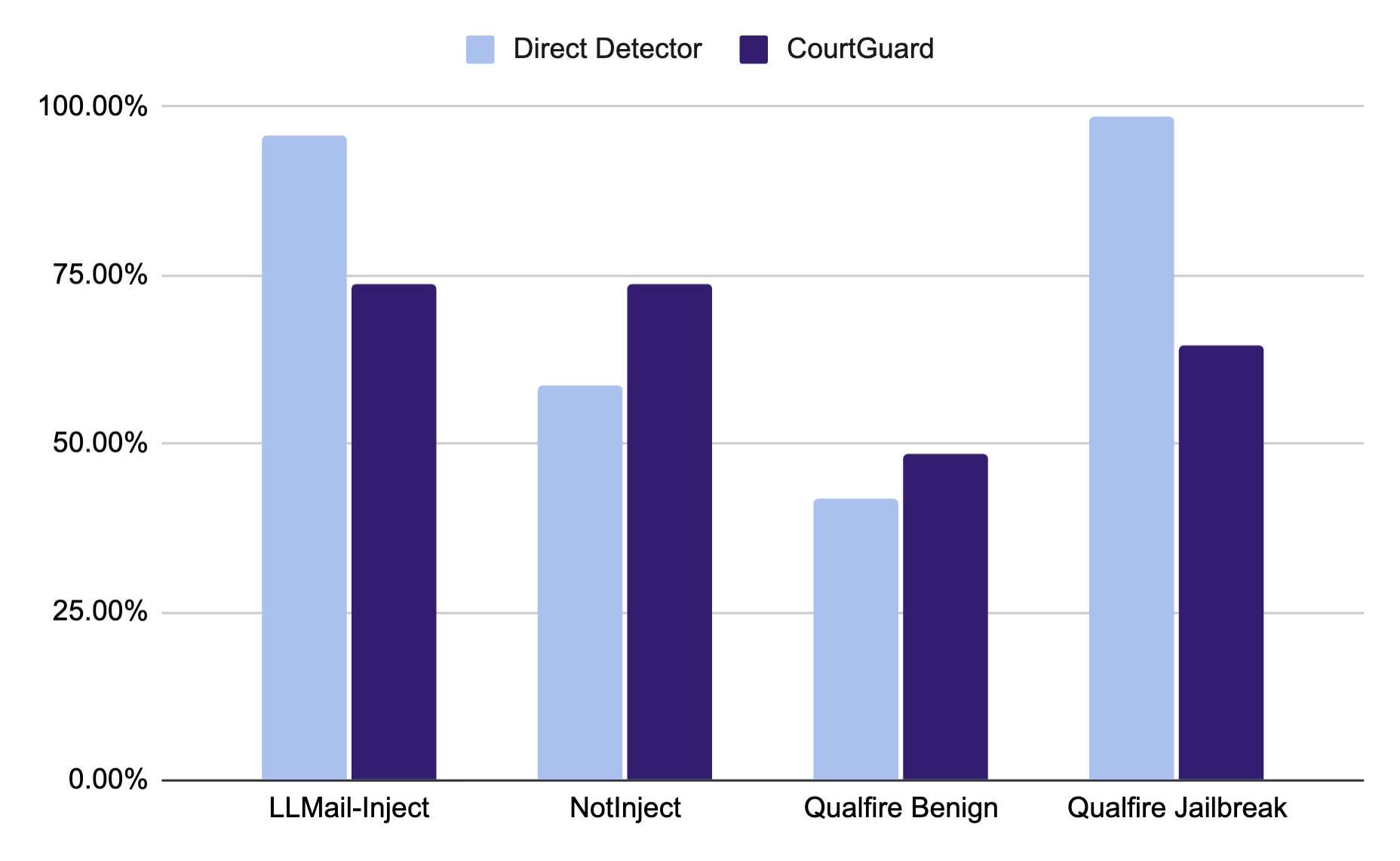
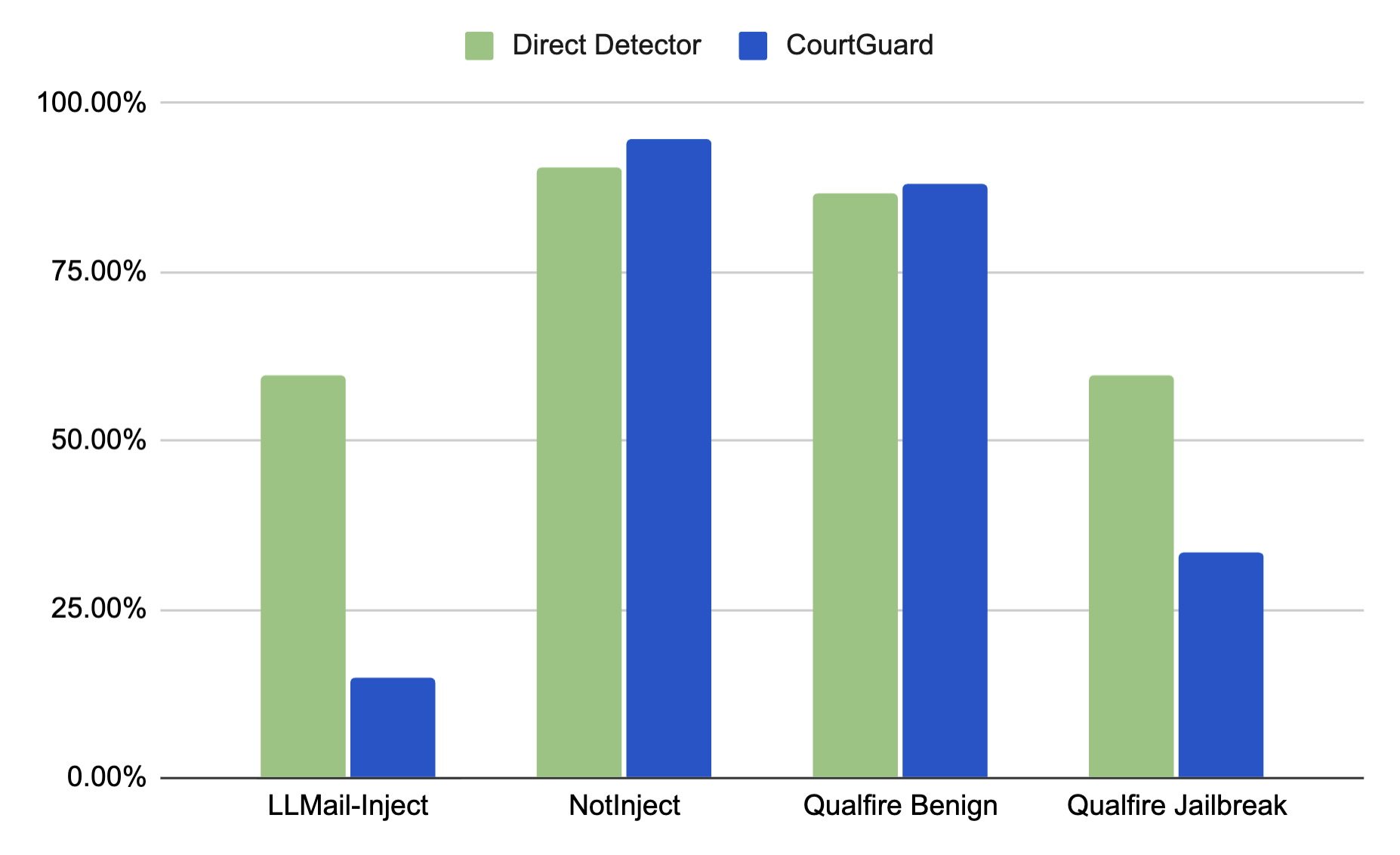
- 实验表明,CourtGuard降低了误报率,验证了多智能体系统在提示注入防御中的潜力,但检测能力有待提升。
📝 摘要(中文)
随着大型语言模型(LLMs)被集成到各种敏感应用中,提示注入(利用提示诱导LLMs产生有害行为)的风险日益增加。提示注入攻击可能导致LLMs泄露敏感数据、传播错误信息和表现出有害行为。为了防御这些攻击,我们提出了CourtGuard,一种本地可运行的多智能体提示注入分类器。在该系统中,提示在一个类似法庭的多智能体LLM系统中进行评估,其中“辩护律师”模型论证提示是良性的,“检察官”模型论证提示是提示注入,而“法官”模型给出最终分类。CourtGuard的假阳性率低于直接检测器(一种将LLM作为法官的方法)。然而,CourtGuard通常是一个较差的提示注入检测器。尽管如此,较低的假阳性率突出了在提示分类中同时考虑对抗性和良性场景的重要性。此外,CourtGuard与其他提示注入分类器的相对性能比较,推进了多智能体系统作为防御提示注入攻击的用途。CourtGuard和直接检测器的实现,以及Gemma-3-12b-it、Llama-3.3-8B和Phi-4-mini-instruct的完整提示,可在https://github.com/isaacwu2000/CourtGuard 获得。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中日益严重的提示注入攻击问题。现有的检测方法,例如直接使用LLM进行判断,容易产生较高的误报率,导致对良性提示的错误拦截,影响LLM的正常使用。
核心思路:论文的核心思路是将提示注入检测问题转化为一个多智能体博弈问题,模拟法庭辩论场景。通过引入“辩护律师”和“检察官”两个角色,分别从良性和恶意两个角度对提示进行评估,最终由“法官”进行裁决。这种设计旨在平衡检测精度和误报率,提高防御系统的鲁棒性。
技术框架:CourtGuard系统的整体架构包含三个主要模块:辩护律师模型、检察官模型和法官模型。首先,将待检测的提示分别输入给辩护律师和检察官模型,它们会生成各自的论证。然后,将提示和两个模型的论证一起输入给法官模型,由法官模型综合判断提示是否为提示注入攻击。
关键创新:该论文最重要的技术创新点在于将多智能体系统引入到提示注入检测中。与传统的单模型检测方法相比,多智能体系统能够更全面地评估提示的安全性,降低误报率。通过模拟法庭辩论,系统能够更好地理解提示的意图,从而更准确地识别恶意提示。
关键设计:论文使用了Gemma-3-12b-it、Llama-3.3-8B和Phi-4-mini-instruct等多种LLM作为各个智能体的基础模型。具体的提示工程(prompt engineering)对于各个角色的性能至关重要,论文在GitHub仓库中提供了完整的提示信息。法官模型的输出是一个概率值,表示提示为提示注入攻击的可能性,通过设定阈值进行最终分类。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CourtGuard在降低假阳性率方面优于直接检测器。虽然CourtGuard的整体提示注入检测性能略逊于直接检测器,但其较低的假阳性率表明了在提示分类中同时考虑对抗性和良性场景的重要性。这一结果突出了多智能体系统在防御提示注入攻击方面的潜力。
🎯 应用场景
CourtGuard可应用于各种集成大型语言模型的敏感应用中,例如智能客服、内容生成平台和数据分析系统。通过降低提示注入攻击的风险,CourtGuard能够保护用户数据安全,防止恶意信息传播,并确保LLM的可靠运行。未来,该方法可扩展到更复杂的攻击场景,并与其他防御机制结合,构建更强大的LLM安全体系。
📄 摘要(原文)
As large language models (LLMs) become integrated into various sensitive applications, prompt injection, the use of prompting to induce harmful behaviors from LLMs, poses an ever increasing risk. Prompt injection attacks can cause LLMs to leak sensitive data, spread misinformation, and exhibit harmful behaviors. To defend against these attacks, we propose CourtGuard, a locally-runnable, multiagent prompt injection classifier. In it, prompts are evaluated in a court-like multiagent LLM system, where a "defense attorney" model argues the prompt is benign, a "prosecution attorney" model argues the prompt is a prompt injection, and a "judge" model gives the final classification. CourtGuard has a lower false positive rate than the Direct Detector, an LLM as-a-judge. However, CourtGuard is generally a worse prompt injection detector. Nevertheless, this lower false positive rate highlights the importance of considering both adversarial and benign scenarios for the classification of a prompt. Additionally, the relative performance of CourtGuard in comparison to other prompt injection classifiers advances the use of multiagent systems as a defense against prompt injection attacks. The implementations of CourtGuard and the Direct Detector with full prompts for Gemma-3-12b-it, Llama-3.3-8B, and Phi-4-mini-instruct are available at https://github.com/isaacwu2000/CourtGuard.