Local Coherence or Global Validity? Investigating RLVR Traces in Math Domains
作者: Soumya Rani Samineni, Durgesh Kalwar, Vardaan Gangal, Siddhant Bhambri, Subbarao Kambhampati
分类: cs.AI, cs.LG
发布日期: 2025-10-20
备注: 4 pages, 2 figures
💡 一句话要点
研究表明,RLVR训练提升数学推理局部连贯性,但不能保证全局正确性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 数学推理 可验证奖励 Trace Coherence 一阶逻辑 GSM8K
📋 核心要点
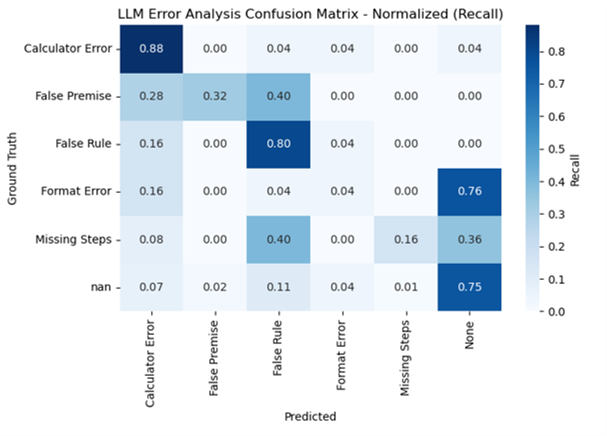
- 现有RLVR方法忽略token级别差异,仅关注最终答案,无法有效评估中间推理步骤的质量。
- 论文提出trace coherence指标,基于一阶逻辑评估推理步骤的局部一致性,区分局部连贯性和全局有效性。
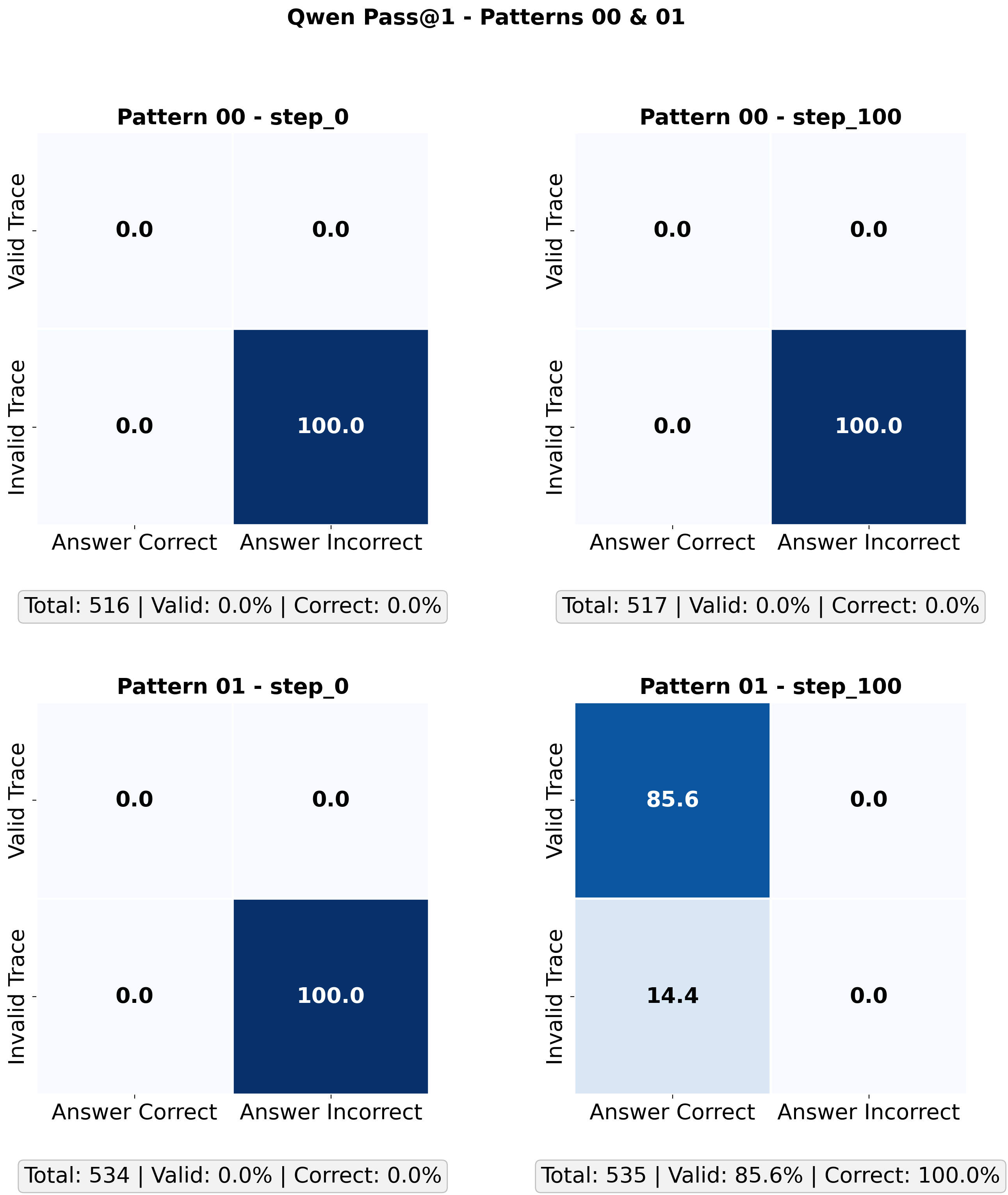
- 实验表明,RL后训练能提升局部连贯性,但不能保证最终答案正确,需谨慎评估RL对推理的改进。
📝 摘要(中文)
基于可验证奖励的强化学习(RLVR)对大型语言模型(LLM)进行后训练,已被证明可以提高推理任务的准确性,并持续受到广泛关注。然而,现有的RLVR方法通常对所有token一视同仁,没有考虑token级别的优势。这些方法主要基于最终答案的正确性或Pass@K准确率来评估性能,并声称RL后训练可以改善推理过程。这促使我们研究RL后训练对未直接激励的中间token的影响。为了研究这一点,我们使用Qwen-2.5-0.5B模型在GSM8K数据集上设计了一个使用GRPO算法的实验装置。我们引入了trace coherence,一种基于一阶逻辑(FOL)的度量,通过识别trace中的错误来捕捉推理步骤的一致性。我们区分了trace validity和trace coherence,前者意味着逻辑上的合理性,而后者通过缺乏错误来衡量局部连贯性。我们的结果表明,RL后训练总体上提高了trace coherence,在基础模型失败但RL模型成功的案例中,提升最为显著。令人惊讶的是,RL增强了局部连贯性,但并不一定产生有效或正确的解决方案。这突出了一个关键区别:推理步骤中改进的局部连贯性并不能保证最终答案的正确性。我们认为,必须谨慎审查关于通过RL改进推理的说法,因为这些说法可能基于改进的trace coherence,而这可能无法转化为完全有效的数学证明。
🔬 方法详解
问题定义:论文旨在解决现有RLVR方法在评估LLM数学推理能力时,过度依赖最终答案正确性,忽略中间推理步骤质量的问题。现有方法无法有效区分局部推理的连贯性和全局答案的正确性,可能误导对RLVR效果的评估。
核心思路:论文的核心思路是引入trace coherence这一指标,用于衡量LLM在生成数学推理trace时,局部步骤之间逻辑一致性。通过分析trace coherence的变化,可以更细粒度地评估RLVR对LLM推理能力的影响,并区分局部改进和全局正确性。
技术框架:论文使用GRPO算法对Qwen-2.5-0.5B模型在GSM8K数据集上进行RL后训练。主要流程包括:1) 使用基础模型生成推理trace;2) 使用RLVR方法对模型进行后训练;3) 使用trace coherence指标评估推理trace的质量;4) 分析RLVR对trace coherence和最终答案正确性的影响。
关键创新:论文的关键创新在于提出了trace coherence这一指标,它是一种基于一阶逻辑的度量,用于评估推理trace中局部步骤之间的一致性。与传统的只关注最终答案正确性的评估方法相比,trace coherence可以更细粒度地捕捉RLVR对LLM推理过程的影响。
关键设计:trace coherence的计算涉及将推理步骤转换为一阶逻辑表达式,并检查相邻步骤之间是否存在逻辑矛盾。具体实现细节和一阶逻辑表达式的构建方法在论文中进行了详细描述。此外,GRPO算法的具体参数设置和Qwen-2.5-0.5B模型的配置也影响实验结果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RL后训练总体上提高了trace coherence,尤其是在基础模型失败但RL模型成功的案例中提升最为显著。然而,RL增强了局部连贯性,但并不一定产生有效或正确的解决方案。这表明,改进的局部连贯性并不能保证最终答案的正确性,需要谨慎评估RL对推理的改进效果。
🎯 应用场景
该研究成果可应用于评估和改进LLM在数学、逻辑推理等领域的性能。通过trace coherence指标,可以更准确地评估RLVR等训练方法对LLM推理过程的影响,并指导模型训练,提升推理的可靠性和可解释性。此外,该方法也可用于检测LLM生成的推理过程中的错误,提高LLM在实际应用中的安全性。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR)-based post-training of Large Language Models (LLMs) has been shown to improve accuracy on reasoning tasks and continues to attract significant attention. Existing RLVR methods, however, typically treat all tokens uniformly without accounting for token-level advantages. These methods primarily evaluate performance based on final answer correctness or Pass@K accuracy, and yet make claims about RL post-training leading to improved reasoning traces. This motivates our investigation into the effect of RL post-training on intermediate tokens which are not directly incentivized. To study this, we design an experimental setup using the GRPO algorithm with Qwen-2.5-0.5B model on the GSM8K dataset. We introduce trace coherence, a First-Order Logic (FOL)-based measure to capture the consistency of reasoning steps by identifying errors in the traces. We distinguish between trace validity and trace coherence, noting that the former implies logical soundness while the latter measures local coherence via lack of errors. Our results show that RL post-training overall improves trace coherence with the most significant gains on problems where the base model fails but the RL model succeeds. Surprisingly, RL enhances local coherence without necessarily producing valid or correct solutions. This highlights a crucial distinction: improved local coherence in reasoning steps does not guarantee final answer correctness. We argue that claims of improved reasoning via RL must be examined with care, as these may be based on improved trace coherence, which may not translate into fully valid mathematical proofs.