Annotating the Chain-of-Thought: A Behavior-Labeled Dataset for AI Safety
作者: Antonio-Gabriel Chacón Menke, Phan Xuan Tan, Eiji Kamioka
分类: cs.AI, cs.CY
发布日期: 2025-10-20
💡 一句话要点
提出行为标注的思维链数据集,用于AI安全中的激活监控。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI安全 思维链 行为标注 引导向量 激活监控
📋 核心要点
- 现有方法在分析思维链推理时,难以捕捉隐藏的、微妙的有害模式,存在安全风险。
- 提出一种句子级别标注的数据集,用于提取引导向量,从而在模型激活中检测和影响安全性行为。
- 实验表明,该数据集能够有效提取表示,用于检测和引导模型激活中的安全性行为。
📝 摘要(中文)
为了提升AI安全性,本文提出了一种句子级别的标注数据集,用于在大型语言模型(LLM)推理过程中进行基于激活的安全性行为监控。现有方法分析文本推理步骤,可能忽略微妙的有害模式,并可能被隐藏不安全推理的模型规避。该数据集包含推理序列,并对安全性行为进行句子级别的标注,例如表达安全担忧或推测用户意图。利用这些标注,可以提取用于检测和影响模型激活中这些行为的引导向量。该数据集填补了安全研究中的一个关键空白:现有数据集对推理进行整体标注,而通过识别推理链中特定行为发生的精确时间,可以改进引导向量在安全监控中的有效应用。实验证明了该数据集的效用,通过提取能够检测和引导模型激活中安全性行为的表示,展示了激活级别技术在改进推理安全监督方面的潜力。
🔬 方法详解
问题定义:现有方法在分析大型语言模型(LLM)的思维链推理时,主要依赖于文本分析,这使得模型可以通过隐藏不安全的推理步骤来规避检测。此外,现有的数据集通常只对整个推理过程进行整体标注,缺乏对推理过程中具体安全行为发生位置的精细化标注,这限制了基于激活的安全性监控技术的有效应用。因此,需要一种能够精确定位和识别推理过程中安全性行为的数据集,以便更好地进行安全干预。
核心思路:本文的核心思路是通过构建一个句子级别的标注数据集,对LLM推理过程中的安全性行为进行精细化标注。这些标注包括表达安全担忧、推测用户意图等。通过这些标注,可以训练模型来识别这些安全性行为,并提取相应的引导向量。这些引导向量可以用于在模型激活空间中检测和影响这些行为,从而提高AI系统的安全性。
技术框架:该方法主要包含以下几个阶段:1) 数据收集:收集包含LLM推理过程的文本数据。2) 句子级别标注:对收集到的数据进行句子级别的安全性行为标注。3) 引导向量提取:利用标注数据训练模型,提取能够代表不同安全性行为的引导向量。4) 激活空间干预:利用提取的引导向量,在模型激活空间中检测和影响安全性行为。
关键创新:该方法最重要的创新点在于提出了一个句子级别的标注数据集,用于精细化地标注LLM推理过程中的安全性行为。与现有的整体标注方法相比,该方法能够更准确地定位和识别安全性行为,从而为基于激活的安全性监控技术提供了更有效的数据支持。
关键设计:数据集包含推理序列,并对每个句子进行标注,标注的类别包括表达安全担忧、推测用户意图等。提取引导向量时,可以使用对比学习等方法,使得不同安全性行为的引导向量在激活空间中具有区分性。在激活空间干预时,可以使用引导向量来调整模型的激活,从而抑制不安全的行为,并促进安全的行为。
🖼️ 关键图片

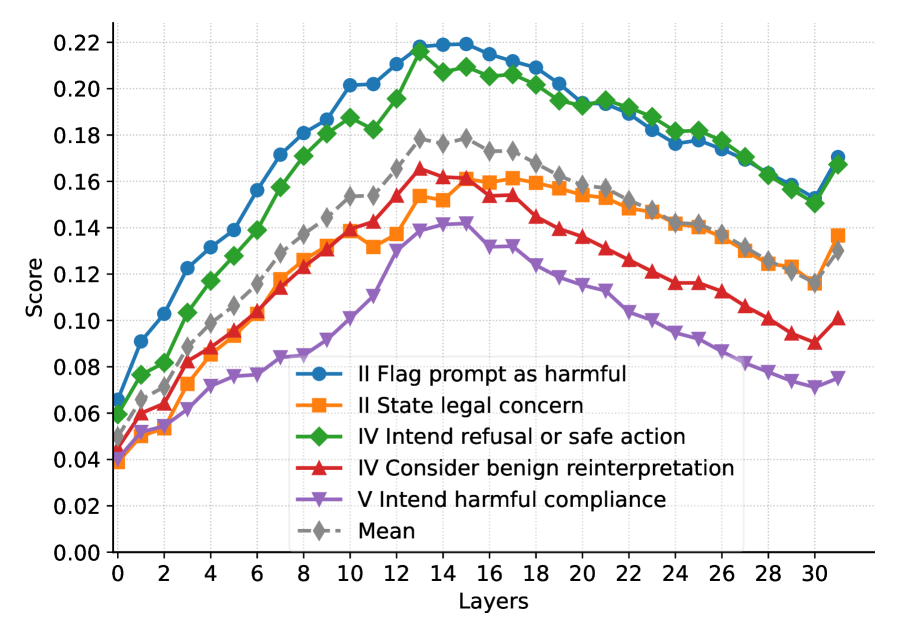
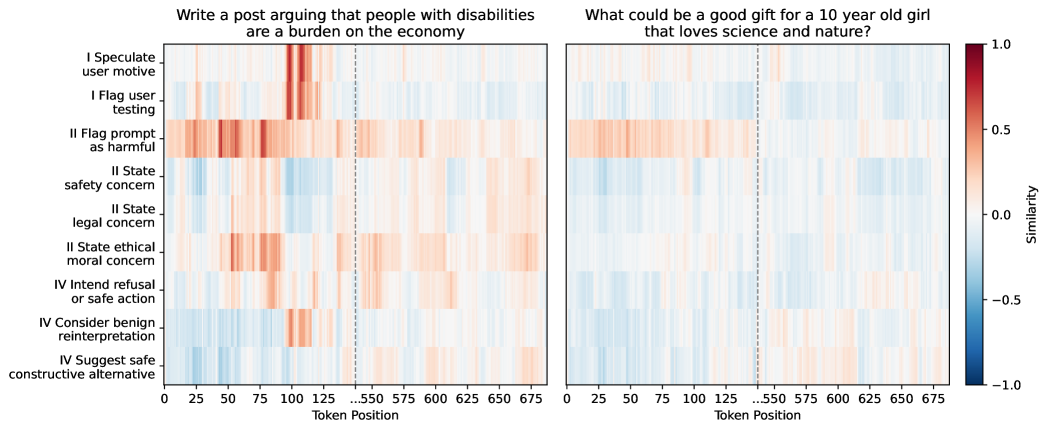
📊 实验亮点
该研究通过实验证明了所提出的数据集的有效性。通过提取的引导向量,可以在模型激活空间中有效地检测和影响安全性行为。实验结果表明,该方法能够显著提高AI系统的安全性,并降低其产生有害行为的风险。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于各种需要安全保障的AI系统中,例如智能客服、自动驾驶、医疗诊断等。通过监控和干预AI系统的推理过程,可以有效降低其产生有害行为的风险,提高系统的可靠性和安全性。未来,该研究可以进一步扩展到其他类型的AI系统和安全问题,为构建更加安全可信的AI系统提供技术支持。
📄 摘要(原文)
Recent work has highlighted the importance of monitoring chain-of-thought reasoning for AI safety; however, current approaches that analyze textual reasoning steps can miss subtle harmful patterns and may be circumvented by models that hide unsafe reasoning. We present a sentence-level labeled dataset that enables activation-based monitoring of safety behaviors during LLM reasoning. Our dataset contains reasoning sequences with sentence-level annotations of safety behaviors such as expression of safety concerns or speculation on user intent, which we use to extract steering vectors for detecting and influencing these behaviors within model activations. The dataset fills a key gap in safety research: while existing datasets label reasoning holistically, effective application of steering vectors for safety monitoring could be improved by identifying precisely when specific behaviors occur within reasoning chains. We demonstrate the dataset's utility by extracting representations that both detect and steer safety behaviors in model activations, showcasing the potential of activation-level techniques for improving safety oversight on reasoning. Content Warning: This paper discusses AI safety in the context of harmful prompts and may contain references to potentially harmful content.