CompactPrompt: A Unified Pipeline for Prompt Data Compression in LLM Workflows
作者: Joong Ho Choi, Jiayang Zhao, Jeel Shah, Ritvika Sonawane, Vedant Singh, Avani Appalla, Will Flanagan, Filipe Condessa
分类: cs.AI
发布日期: 2025-10-20
备注: Workshop on LLMs and Generative AI for Finance at ACM ICAIF 2025
💡 一句话要点
CompactPrompt:面向LLM工作流的统一Prompt数据压缩方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Prompt压缩 数据压缩 大型语言模型 Agentic工作流 推理成本
📋 核心要点
- LLM在Agent任务中面临长Prompt和大数据流带来的高昂计算成本挑战。
- CompactPrompt通过硬Prompt压缩和轻量级文件级数据压缩,实现高效的token缩减。
- 实验表明,CompactPrompt能在保持输出质量的同时,显著降低token使用量和推理成本。
📝 摘要(中文)
大型语言模型(LLM)具有强大的推理和生成能力,但在agentic工作流中运行时会产生巨大的成本,因为这些工作流将冗长的prompt链接在一起并处理丰富的数据流。我们介绍了CompactPrompt,这是一个端到端的pipeline,它将硬prompt压缩与轻量级文件级数据压缩相结合。CompactPrompt首先使用自信息评分和基于依赖关系的短语分组从prompt中修剪低信息量的token。同时,它将n-gram缩写应用于附加文档中重复出现的文本模式,并将均匀量化应用于数值列,从而产生紧凑但语义忠实的表示。集成到标准LLM agent中,CompactPrompt在TAT-QA和FinQA等基准数据集上减少了高达60%的总token使用量和推理成本,同时保持了输出质量(Claude-3.5-Sonnet和GPT-4.1-Mini的准确率下降小于5%)。CompactPrompt有助于可视化实时压缩决策并量化成本-性能权衡,为更精简的生成式AI pipeline奠定基础。
🔬 方法详解
问题定义:LLM在agentic工作流中处理复杂任务时,需要处理大量的prompt和数据,导致token数量激增,推理成本高昂。现有的方法要么只关注prompt优化,要么忽略了附加文档中的冗余信息,无法实现整体的有效压缩。
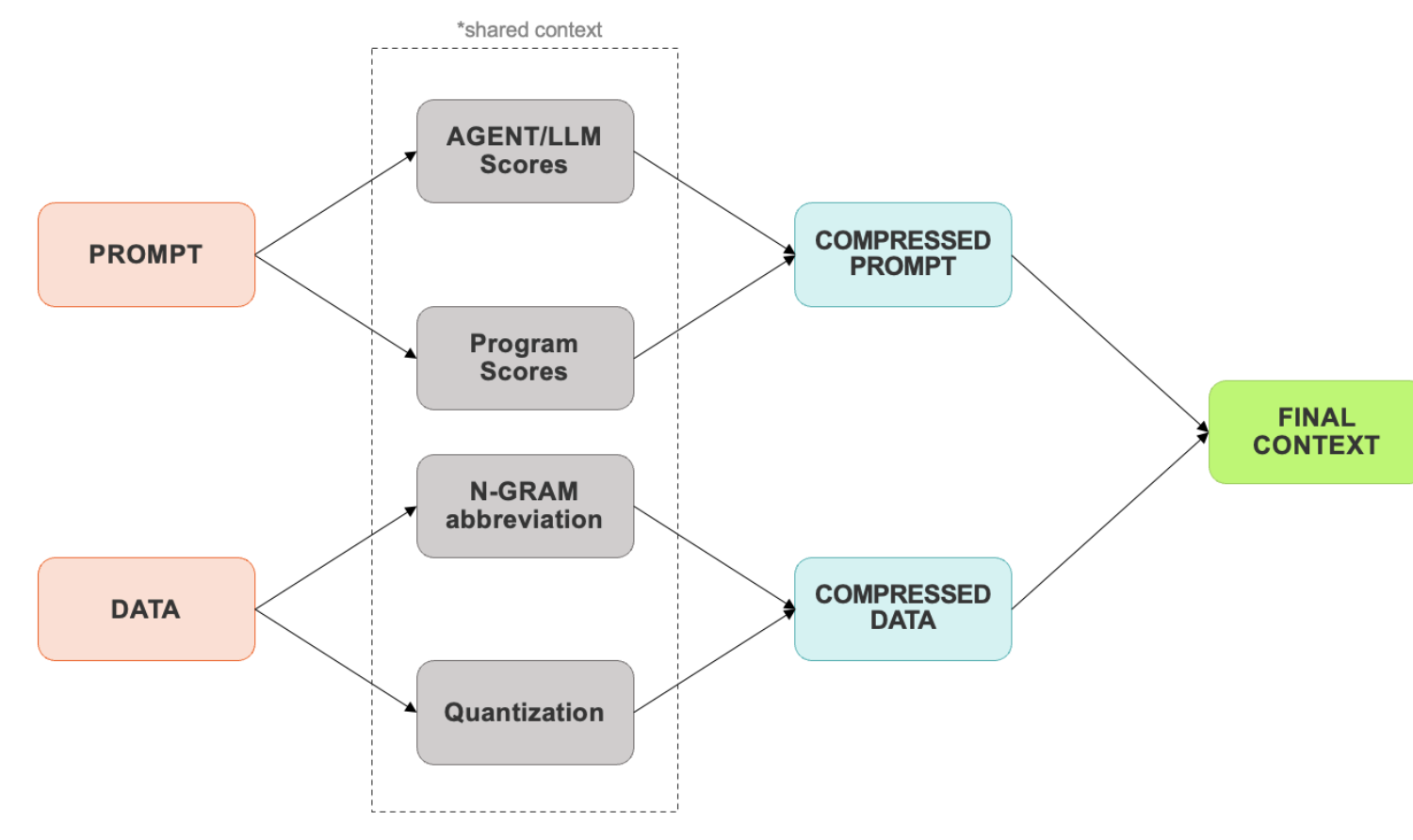
核心思路:CompactPrompt的核心思路是将prompt压缩和数据压缩相结合,形成一个端到端的pipeline。通过去除prompt中的低信息量token,并对附加文档进行压缩,从而在整体上减少token数量,降低推理成本。这种设计旨在保持语义完整性的同时,实现高效的压缩。
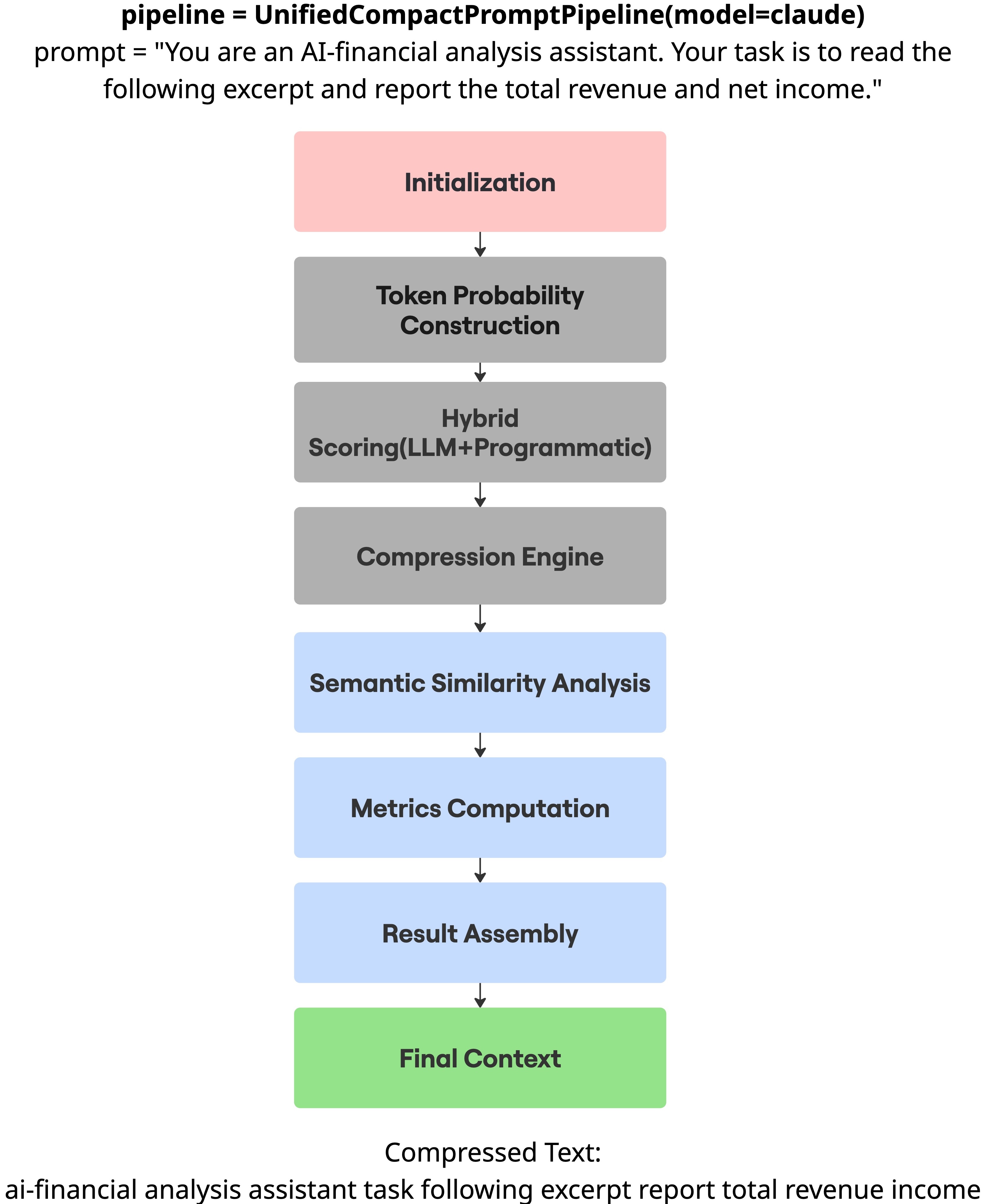
技术框架:CompactPrompt包含两个主要模块:Prompt压缩和数据压缩。Prompt压缩模块使用自信息评分和基于依赖关系的短语分组来修剪prompt中的低信息量token。数据压缩模块则对附加文档应用n-gram缩写(针对文本数据)和均匀量化(针对数值数据)。这两个模块并行工作,最终将压缩后的prompt和数据输入LLM进行推理。
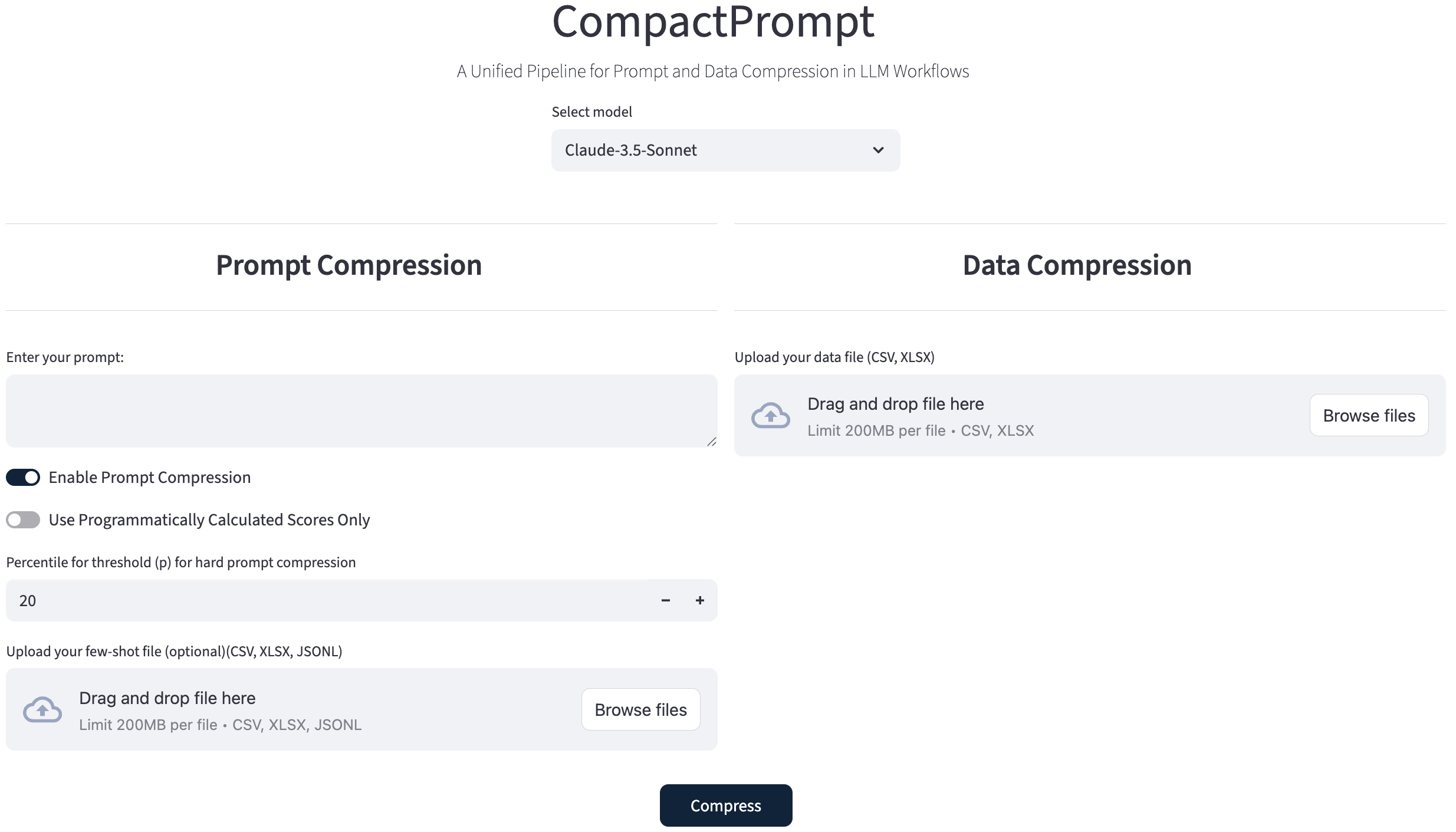
关键创新:CompactPrompt的关键创新在于其统一的压缩pipeline,它同时考虑了prompt和数据的压缩。与传统方法相比,CompactPrompt能够更全面地减少token数量,从而更有效地降低推理成本。此外,CompactPrompt还提供了实时压缩决策的可视化功能,方便用户了解压缩过程和权衡成本-性能。
关键设计:在Prompt压缩模块中,自信息评分用于评估每个token的重要性,并根据设定的阈值进行过滤。基于依赖关系的短语分组则用于确保压缩后的prompt仍然保持语法和语义的连贯性。在数据压缩模块中,n-gram缩写通过识别和替换重复出现的文本模式来减少文本数据的冗余。均匀量化则将数值数据映射到更小的数值范围内,从而减少数值数据的存储空间。
🖼️ 关键图片
📊 实验亮点
CompactPrompt在TAT-QA和FinQA等基准数据集上进行了评估,结果表明,该方法能够减少高达60%的总token使用量和推理成本,同时保持输出质量(Claude-3.5-Sonnet和GPT-4.1-Mini的准确率下降小于5%)。这些实验结果表明,CompactPrompt是一种有效的prompt数据压缩方法,能够显著提高LLM应用的效率。
🎯 应用场景
CompactPrompt可应用于各种需要处理大量prompt和数据的LLM应用场景,例如智能客服、金融分析、文档摘要等。通过降低token使用量和推理成本,CompactPrompt可以提高LLM应用的效率和可扩展性,并降低部署成本。该研究为构建更精简、高效的生成式AI pipeline提供了有价值的思路。
📄 摘要(原文)
Large Language Models (LLMs) deliver powerful reasoning and generation capabilities but incur substantial run-time costs when operating in agentic workflows that chain together lengthy prompts and process rich data streams. We introduce CompactPrompt, an end-to-end pipeline that merges hard prompt compression with lightweight file-level data compression. CompactPrompt first prunes low-information tokens from prompts using self-information scoring and dependency-based phrase grouping. In parallel, it applies n-gram abbreviation to recurrent textual patterns in attached documents and uniform quantization to numerical columns, yielding compact yet semantically faithful representations. Integrated into standard LLM agents, CompactPrompt reduces total token usage and inference cost by up to 60% on benchmark dataset like TAT-QA and FinQA, while preserving output quality (Results in less than 5% accuracy drop for Claude-3.5-Sonnet, and GPT-4.1-Mini) CompactPrompt helps visualize real-time compression decisions and quantify cost-performance trade-offs, laying the groundwork for leaner generative AI pipelines.