OPTAGENT: Optimizing Multi-Agent LLM Interactions Through Verbal Reinforcement Learning for Enhanced Reasoning
作者: Zhenyu Bi, Meng Lu, Yang Li, Swastik Roy, Weijie Guan, Morteza Ziyadi, Xuan Wang
分类: cs.AI, cs.MA
发布日期: 2025-10-20
备注: 8 pages for main content
💡 一句话要点
OPTAGENT:通过语言强化学习优化多智能体LLM交互,提升推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 强化学习 语言模型 协作推理
📋 核心要点
- 现有方法在多智能体LLM协作中,要么预定义结构,要么依赖多数投票,忽略了智能体间交互质量。
- OPTAGENT通过语言强化学习动态构建和优化多智能体协作结构,提升沟通的稳健性和连贯性。
- 实验表明,OPTAGENT在数学、写作、科学推理和排序任务上显著优于单智能体和现有方法。
📝 摘要(中文)
大型语言模型(LLMs)在数学和科学任务中展现了卓越的推理能力。为了增强复杂推理,多智能体系统被提出以利用LLM智能体的集体智慧。然而,现有的协作结构要么是预定义的,要么依赖于多数投票或圆桌辩论,这可能会抑制正确但不太占主导地位的智能体贡献。最近的方法将多智能体系统建模为图网络,但仅针对智能体性能进行优化,忽略了交互质量。我们假设有效的智能体沟通对于多智能体推理至关重要,并且辩论质量起着重要作用。为了解决这个问题,我们提出了OPTAGENT,一种多智能体语言强化学习算法,可以动态构建和改进多智能体协作结构。我们的方法定义了动作空间和一个反馈机制,用于评估整个辩论过程中的沟通稳健性和连贯性。最终决策通过所有智能体的多数投票来实现。我们在各种推理任务(包括数学推理、创意写作、科学推理和数值排序)上评估了OPTAGENT。结果表明,我们的方法在各种任务上显着优于单智能体提示方法和最先进的多智能体框架。
🔬 方法详解
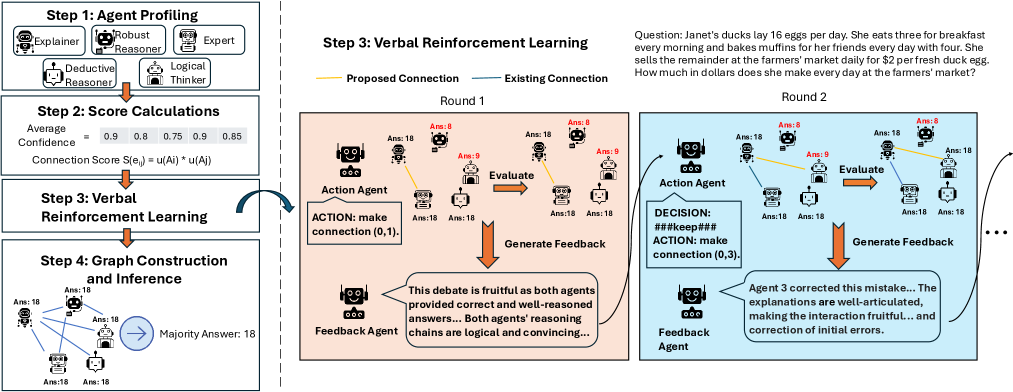
问题定义:论文旨在解决多智能体LLM协作推理中,现有方法忽略智能体间交互质量,导致推理能力受限的问题。现有方法要么采用预定义的协作结构,要么简单地使用多数投票,无法充分利用每个智能体的优势,甚至可能抑制正确但非主流的观点。此外,现有方法通常只关注智能体的个体性能,而忽略了智能体之间的沟通质量,导致协作效率低下。
核心思路:OPTAGENT的核心思路是通过语言强化学习,动态地构建和优化多智能体协作结构。它将智能体之间的交互过程建模为一个马尔可夫决策过程,并使用强化学习算法来学习最佳的协作策略。通过奖励高质量的沟通和惩罚低质量的沟通,OPTAGENT鼓励智能体之间进行更有效、更连贯的辩论,从而提高整体的推理能力。
技术框架:OPTAGENT的整体框架包括以下几个主要模块:1) 智能体初始化:每个智能体配备一个LLM,并赋予其特定的角色和知识。2) 辩论过程:智能体之间进行多轮辩论,每轮辩论中,智能体根据当前状态选择一个动作,例如提出观点、反驳观点、支持观点等。3) 奖励函数:根据辩论的质量,计算每个智能体的奖励。奖励函数考虑了沟通的稳健性和连贯性。4) 策略优化:使用强化学习算法,根据奖励函数更新每个智能体的策略。5) 决策:所有智能体进行多数投票,选出最终的答案。
关键创新:OPTAGENT的关键创新在于:1) 提出了一个基于语言的强化学习框架,用于优化多智能体LLM的交互。2) 设计了一个能够评估沟通稳健性和连贯性的奖励函数。3) 能够动态地构建和优化多智能体协作结构,从而提高整体的推理能力。与现有方法相比,OPTAGENT更加关注智能体之间的沟通质量,并且能够根据任务的特点自适应地调整协作结构。
关键设计:OPTAGENT的关键设计包括:1) 动作空间的设计:定义了智能体可以采取的各种动作,例如提出观点、反驳观点、支持观点等。2) 奖励函数的设计:奖励函数综合考虑了沟通的稳健性和连贯性。稳健性是指智能体提出的观点是否能够经受住其他智能体的质疑。连贯性是指智能体之间的辩论是否能够形成一个逻辑上一致的整体。3) 强化学习算法的选择:可以使用各种强化学习算法,例如Q-learning、SARSA、Policy Gradient等。论文中具体使用的算法未知。
🖼️ 关键图片
📊 实验亮点
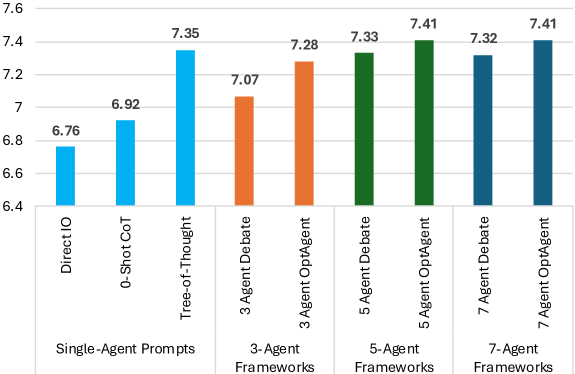
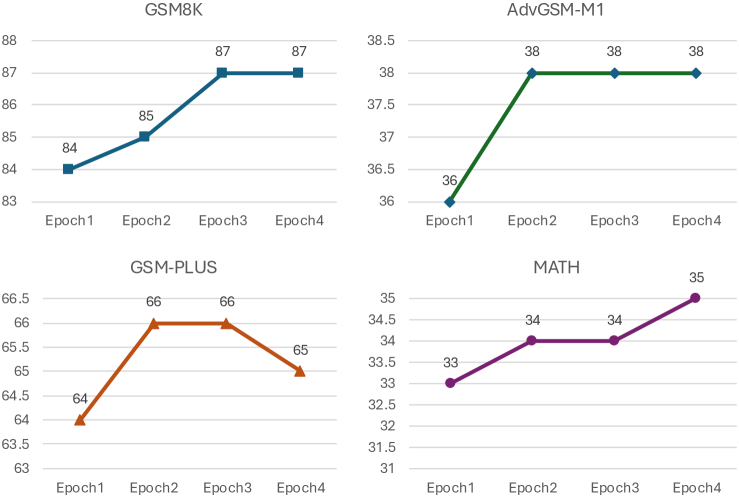
OPTAGENT在数学推理、创意写作、科学推理和数值排序等多种任务上进行了评估,实验结果表明,OPTAGENT显著优于单智能体提示方法和最先进的多智能体框架。具体提升幅度未知,但摘要中明确指出是“显著优于”。
🎯 应用场景
OPTAGENT可应用于需要复杂推理和协作的领域,例如科学研究、政策制定、商业决策等。通过优化多智能体LLM的交互,可以提高决策的质量和效率。未来,该技术有望应用于自动化科研、智能客服、智能投顾等领域,为人类提供更智能、更高效的服务。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable reasoning capabilities in mathematical and scientific tasks. To enhance complex reasoning, multi-agent systems have been proposed to harness the collective intelligence of LLM agents. However, existing collaboration structures are either predefined or rely on majority voting or round-table debates, which can suppress correct but less dominant agent contributions. Recent approaches model multi-agent systems as graph networks but optimize purely for agent performance, neglecting the quality of interactions. We hypothesize that effective agent communication is crucial for multi-agent reasoning and that debating quality plays a significant role. To address this, we propose $\ours$, a multi-agent verbal reinforcement learning algorithm that dynamically constructs and refines multi-agent collaboration structures. Our method defines action spaces and a feedback mechanism that evaluates communication robustness and coherence throughout the debate. The final decision is achieved through a majority vote over all the agents. We assess $\ours$ on various reasoning tasks, including mathematical reasoning, creative writing, scientific reasoning, and numerical sorting. Results demonstrate that our approach significantly outperforms single-agent prompting methods and state-of-the-art multi-agent frameworks on diverse tasks.