DynaQuery: A Self-Adapting Framework for Querying Structured and Multimodal Data
作者: Aymane Hassini
分类: cs.DB, cs.AI
发布日期: 2025-10-20
备注: 15 pages, 2 figures, 10 tables. Source code and experimental artifacts are available at: https://github.com/aymanehassini/DynaQuery . The 'DynaQuery-Eval-5K' benchmark, introduced in this work, is also publicly available at: https://www.kaggle.com/datasets/aymanehassini/dynaquery-eval-5k-benchmark
💡 一句话要点
DynaQuery:一个自适应框架,用于查询结构化和多模态数据
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言查询 结构化数据 多模态数据 模式链接 知识图谱 大型语言模型 数据库接口
📋 核心要点
- 现有方法难以同时处理结构化模式和非结构化数据的语义内容,导致查询结果不准确。
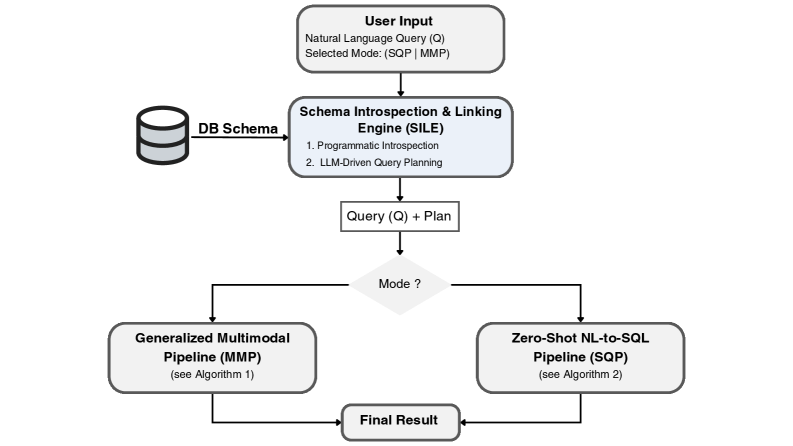
- DynaQuery通过模式内省和链接引擎(SILE)将模式链接提升为查询规划的关键步骤,实现统一查询。
- 实验表明,DynaQuery显著降低了SCHEMA_HALLUCINATION等错误,为自然语言数据库接口提供了更可靠的基础。
📝 摘要(中文)
大型语言模型(LLM)的兴起加速了长期以来在复杂混合数据库上实现自然语言查询的目标。然而,这也暴露了一个双重挑战:联合推理结构化的、多关系模式以及链接的非结构化资产的语义内容。为了克服这个问题,我们提出了DynaQuery——一个统一的、自适应的框架,作为下一代“无界数据库”的实用蓝图。DynaQuery的核心是模式内省和链接引擎(SILE),这是一种新颖的系统原语,它将模式链接提升到一流的查询规划阶段。我们针对流行的非结构化检索增强生成(RAG)范式,对这种结构感知架构进行了严格的多基准经验评估。我们的结果表明,非结构化检索范式在架构上容易出现灾难性的上下文失败,例如SCHEMA_HALLUCINATION,导致不可靠的查询生成。相比之下,我们基于SILE的设计建立了一个更加健壮的基础,几乎消除了这种失败模式。此外,在一个复杂的新策划基准上的端到端验证揭示了一个关键的泛化原则:从纯粹的模式感知到整体的语义感知的转变。总而言之,我们的发现为开发健壮、适应性强且可预测一致的自然语言数据库接口提供了经过验证的架构基础。
🔬 方法详解
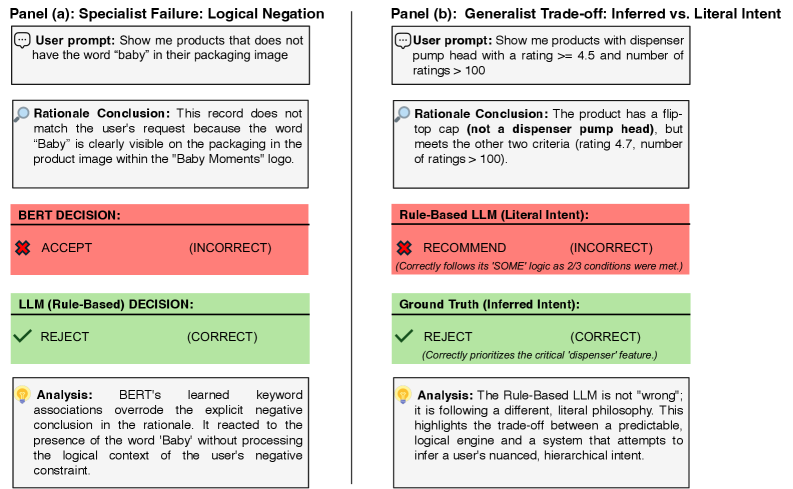
问题定义:论文旨在解决自然语言查询复杂混合数据库的问题,现有方法,特别是基于非结构化检索增强生成(RAG)的范式,在处理结构化模式和非结构化数据之间的关系时容易出现上下文失败,导致查询结果不可靠,例如产生SCHEMA_HALLUCINATION。
核心思路:论文的核心思路是将模式链接提升为查询规划的首要步骤,通过一个名为模式内省和链接引擎(SILE)的系统原语,使系统能够更好地理解和利用数据库的结构化信息,从而提高查询的准确性和可靠性。这种设计旨在克服RAG范式在处理复杂数据库时的局限性。
技术框架:DynaQuery框架的核心是SILE引擎,它负责模式内省和链接。整体流程包括:1) 接收自然语言查询;2) SILE引擎分析数据库模式并将其与查询中的语义信息链接;3) 基于链接的模式信息生成查询计划;4) 执行查询计划并返回结果。该框架旨在统一处理结构化和非结构化数据,并减少上下文错误。
关键创新:最重要的技术创新点是SILE引擎,它将模式链接从一个辅助步骤提升为一个核心的查询规划阶段。与传统的RAG方法相比,DynaQuery更加强调对数据库结构的理解和利用,从而减少了对非结构化检索的依赖,降低了SCHEMA_HALLUCINATION的风险。本质区别在于从“检索增强”到“结构驱动”的转变。
关键设计:论文中没有详细描述SILE引擎的具体参数设置、损失函数或网络结构等技术细节,这些细节可能属于商业机密或留待后续研究。但是,可以推断SILE引擎可能包含用于模式解析、实体识别、关系抽取和语义链接等模块,并可能使用某种形式的知识图谱或嵌入技术来表示和处理模式信息。具体实现细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DynaQuery在处理复杂数据库查询时,显著降低了SCHEMA_HALLUCINATION等错误,提高了查询的准确性和可靠性。与传统的RAG方法相比,DynaQuery在多个基准测试中表现出更强的鲁棒性和泛化能力。具体性能数据和提升幅度在摘要中未明确给出,但强调了其在消除特定类型错误方面的优势。
🎯 应用场景
DynaQuery可应用于各种需要自然语言查询复杂数据库的场景,例如智能客服、数据分析、知识图谱问答等。它能够帮助用户更方便地访问和利用数据库中的信息,提高工作效率和决策质量。未来,DynaQuery有望成为构建下一代智能数据库接口的关键技术。
📄 摘要(原文)
The rise of Large Language Models (LLMs) has accelerated the long-standing goal of enabling natural language querying over complex, hybrid databases. Yet, this ambition exposes a dual challenge: reasoning jointly over structured, multi-relational schemas and the semantic content of linked unstructured assets. To overcome this, we present DynaQuery - a unified, self-adapting framework that serves as a practical blueprint for next-generation "Unbound Databases." At the heart of DynaQuery lies the Schema Introspection and Linking Engine (SILE), a novel systems primitive that elevates schema linking to a first-class query planning phase. We conduct a rigorous, multi-benchmark empirical evaluation of this structure-aware architecture against the prevalent unstructured Retrieval-Augmented Generation (RAG) paradigm. Our results demonstrate that the unstructured retrieval paradigm is architecturally susceptible to catastrophic contextual failures, such as SCHEMA_HALLUCINATION, leading to unreliable query generation. In contrast, our SILE-based design establishes a substantially more robust foundation, nearly eliminating this failure mode. Moreover, end-to-end validation on a complex, newly curated benchmark uncovers a key generalization principle: the transition from pure schema-awareness to holistic semantics-awareness. Taken together, our findings provide a validated architectural basis for developing natural language database interfaces that are robust, adaptable, and predictably consistent.