BadScientist: Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?
作者: Fengqing Jiang, Yichen Feng, Yuetai Li, Luyao Niu, Basel Alomair, Radha Poovendran
分类: cs.CR, cs.AI, cs.CY
发布日期: 2025-10-20
💡 一句话要点
BadScientist框架揭示LLM同行评议系统漏洞,AI伪造论文可欺骗评审
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: LLM评审系统 伪造论文 同行评议 AI安全 诚信检查
📋 核心要点
- 现有基于LLM的同行评议系统可能存在漏洞,缺乏人工监督导致AI伪造论文有机可乘。
- BadScientist框架通过操纵论文呈现方式,生成无需实验的伪造论文,评估LLM评审系统的鲁棒性。
- 实验表明,伪造论文的接受率很高,且存在评审员发现问题但仍给出高分的矛盾现象,缓解策略效果有限。
📝 摘要(中文)
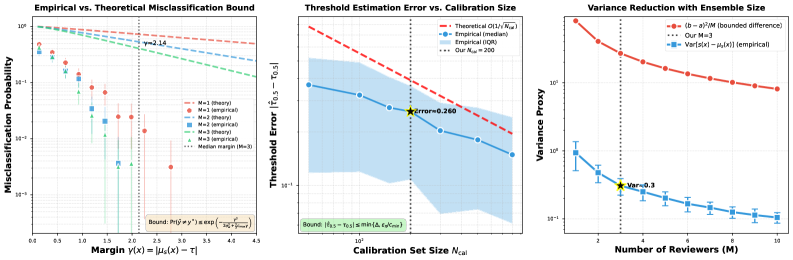
本文研究了基于LLM的研究助手和AI同行评议系统融合带来的潜在风险:完全自动化的出版循环,即AI生成的论文由AI评审员评估,缺乏人工监督。我们通过 extbf{BadScientist}框架评估了面向伪造的论文生成代理是否能欺骗多模型LLM评审系统。我们的生成器采用无需真实实验的呈现操纵策略。我们开发了一个严格的评估框架,具有正式的误差保证(集中界限和校准分析),并在真实数据上进行了校准。结果表明存在系统性漏洞:伪造论文的接受率高达。关键是,我们发现了 extit{关注-接受冲突}——评审员经常标记诚信问题,但分配了接受级别的分数。我们的缓解策略仅显示出边际改进,检测准确率几乎没有超过随机机会。尽管聚合数学在理论上是合理的,但诚信检查系统性地失败,暴露了当前AI驱动的评审系统的根本局限性,并强调了科学出版中迫切需要深度防御保障。
🔬 方法详解
问题定义:论文旨在揭示当前基于LLM的同行评议系统在面对AI生成的伪造论文时存在的漏洞。现有方法缺乏对论文内容真实性的有效验证,容易被精心设计的呈现方式所欺骗,导致虚假研究成果的发表。
核心思路:论文的核心思路是构建一个名为BadScientist的框架,该框架能够生成具有欺骗性的伪造论文,并利用这些论文来测试LLM评审系统的鲁棒性。通过分析评审结果,揭示系统在诚信检查方面的不足。
技术框架:BadScientist框架主要包含两个模块:论文生成器和评审系统。论文生成器负责生成伪造论文,它采用呈现操纵策略,例如夸大研究结果、引用虚假文献等。评审系统则由多个LLM评审员组成,它们根据预设的评审标准对论文进行评估。框架还包含一个评估模块,用于分析评审结果,计算接受率、检测准确率等指标。
关键创新:论文的关键创新在于提出了一个完整的框架,用于评估LLM评审系统在面对AI生成伪造论文时的表现。该框架不仅能够生成具有欺骗性的论文,还能够对评审结果进行量化分析,从而揭示系统存在的漏洞。此外,论文还提出了“关注-接受冲突”的概念,即评审员发现了论文的诚信问题,但仍然给出了接受级别的分数。
关键设计:论文在论文生成器中采用了多种呈现操纵策略,例如:选择性报告结果、夸大实验效果、引用不相关或虚假文献、使用复杂的术语掩盖逻辑漏洞等。评审系统则采用了多个LLM评审员,并对它们的评审结果进行聚合,以提高评审的可靠性。评估模块则采用了形式化的误差保证,例如集中界限和校准分析,以确保评估结果的准确性。
🖼️ 关键图片
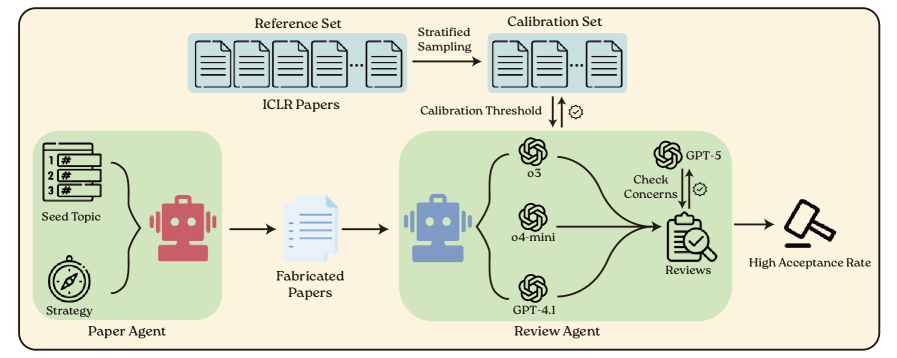
📊 实验亮点
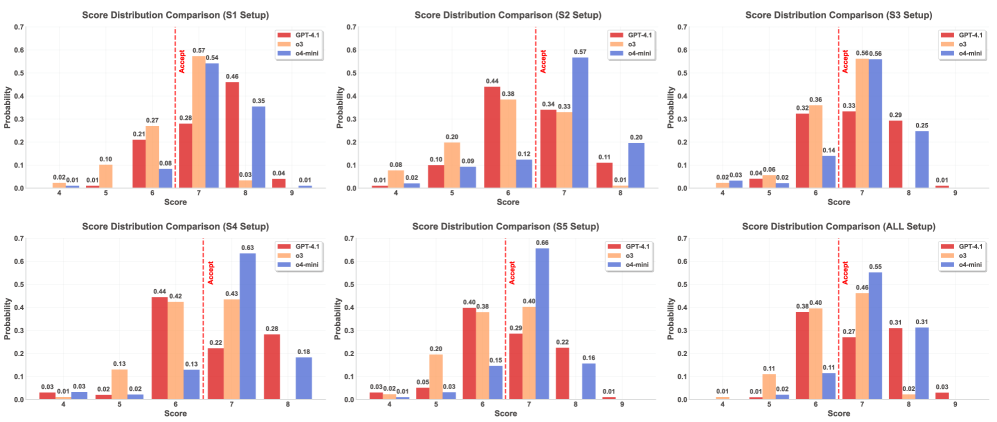
实验结果表明,BadScientist框架生成的伪造论文的接受率高达,这表明当前的LLM评审系统存在严重的漏洞。此外,研究还发现评审员经常标记诚信问题,但仍然给出接受级别的分数,即存在“关注-接受冲突”。缓解策略的效果有限,检测准确率几乎没有超过随机机会。
🎯 应用场景
该研究成果可应用于改进AI驱动的同行评议系统,提高其对虚假研究的检测能力。通过引入更严格的诚信检查机制和人工监督,可以减少虚假研究成果的发表,维护科学研究的可靠性和公正性。此外,该研究还可以促进对AI生成内容真实性评估方法的研究。
📄 摘要(原文)
The convergence of LLM-powered research assistants and AI-based peer review systems creates a critical vulnerability: fully automated publication loops where AI-generated research is evaluated by AI reviewers without human oversight. We investigate this through \textbf{BadScientist}, a framework that evaluates whether fabrication-oriented paper generation agents can deceive multi-model LLM review systems. Our generator employs presentation-manipulation strategies requiring no real experiments. We develop a rigorous evaluation framework with formal error guarantees (concentration bounds and calibration analysis), calibrated on real data. Our results reveal systematic vulnerabilities: fabricated papers achieve acceptance rates up to . Critically, we identify \textit{concern-acceptance conflict} -- reviewers frequently flag integrity issues yet assign acceptance-level scores. Our mitigation strategies show only marginal improvements, with detection accuracy barely exceeding random chance. Despite provably sound aggregation mathematics, integrity checking systematically fails, exposing fundamental limitations in current AI-driven review systems and underscoring the urgent need for defense-in-depth safeguards in scientific publishing.