FABRIC: Framework for Agent-Based Realistic Intelligence Creation
作者: Abhigya Verma, Seganrasan Subramanian, Nandhakumar Kandasamy, Naman Gupta
分类: cs.AI
发布日期: 2025-10-20
备注: 51 Pages, 38 Listings, 5 Figures
💡 一句话要点
FABRIC:提出一个基于LLM的框架,用于生成Agent交互数据,促进Agent智能体的开发。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent智能体 大型语言模型 数据生成 工具使用 交互数据 合成数据 无监督学习
📋 核心要点
- 现有Agent智能体训练依赖人工标注数据,但人工标注成本高昂、耗时且难以扩展。
- FABRIC框架利用LLM自动生成Agent交互数据,无需人工干预,降低数据获取成本。
- 该框架通过模块化流程、约束生成和验证机制,保证生成数据的质量和一致性。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被部署为智能体,需要在动态环境中分解目标、调用工具和验证结果。实现这些能力需要访问智能体交互数据,这些数据需要包含用户意图、工具规范、基于参数的调用以及可验证的执行轨迹。然而,从人工标注者那里收集此类数据成本高昂、耗时且难以扩展。本文提出了一个统一的框架FABRIC,仅使用LLM合成智能体数据,无需人工干预。该框架将生成过程分解为模块化流程,生成完整的交互记录,涵盖任务规范、工具定义、策略伪代码、自然语言交流和执行轨迹。记录符合严格的语法和语义约束,确保机器可解析性以及输入、输出和工具调用之间的忠实对齐。除了单个任务之外,还支持多任务和多轮智能体交互,从而能够构建反映工具使用能力的完整数据集。为了确保质量和一致性,该框架集成了约束生成格式、JSON模式验证和基于判断的过滤。本文形式化了智能体记录的模式,详细介绍了指导生成的提示设计原则,并介绍了用于高质量合成数据的可扩展流程。通过提供一种可复现的、仅使用LLM的替代方案来替代手动收集,从而推进了能够可靠使用工具的智能体LLM的开发。
🔬 方法详解
问题定义:现有Agent智能体的训练依赖于大量高质量的交互数据,这些数据需要包含用户意图、工具规范、参数化调用以及可验证的执行轨迹。然而,人工标注这些数据成本高昂,耗时,并且难以扩展,限制了Agent智能体的快速发展。
核心思路:FABRIC框架的核心思路是利用LLM自身的能力来生成Agent交互数据,从而避免人工标注的成本。通过精心设计的提示和模块化的生成流程,确保生成的数据既符合语法规范,又在语义上与任务目标对齐。
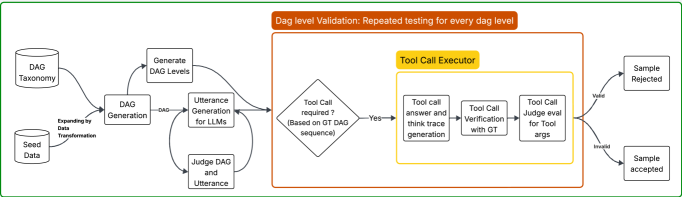
技术框架:FABRIC框架包含以下主要模块:1) 任务规范生成模块:生成Agent需要完成的任务描述。2) 工具定义模块:定义Agent可以使用的工具及其参数。3) 策略伪代码生成模块:生成Agent完成任务的策略伪代码。4) 自然语言交流生成模块:模拟Agent与用户之间的自然语言交互。5) 执行轨迹生成模块:记录Agent执行工具调用的轨迹。这些模块通过管道化的方式连接,最终生成完整的Agent交互记录。
关键创新:FABRIC框架的关键创新在于完全依赖LLM生成Agent交互数据,无需任何人工干预。通过模块化的设计和约束生成机制,保证了生成数据的质量和一致性。此外,该框架还支持多任务和多轮交互,能够生成更复杂和真实的Agent交互数据。
关键设计:FABRIC框架的关键设计包括:1) 约束生成格式:使用JSON Schema定义数据格式,确保生成的数据符合规范。2) 提示工程:精心设计提示,引导LLM生成高质量的数据。3) 基于判断的过滤:使用LLM作为裁判,过滤掉不符合要求的生成结果。4) 模块化设计:将生成过程分解为多个模块,方便定制和扩展。
🖼️ 关键图片


📊 实验亮点
论文提出了一个完全基于LLM的Agent交互数据生成框架,无需人工标注。通过模块化设计和约束生成机制,保证了生成数据的质量和一致性。该框架支持多任务和多轮交互,能够生成更复杂和真实的Agent交互数据。实验结果表明,使用该框架生成的数据可以有效提升Agent智能体的性能。
🎯 应用场景
FABRIC框架可以应用于各种需要Agent智能体的场景,例如智能助手、自动化客服、机器人控制等。通过生成大量的Agent交互数据,可以有效提升Agent智能体的性能和鲁棒性,加速Agent智能体的开发和部署。该框架还可以用于研究Agent智能体的涌现行为和学习机制,为人工智能领域的发展提供新的思路。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed as agents, expected to decompose goals, invoke tools, and verify results in dynamic environments. Realizing these capabilities requires access to agentic data-structured interaction records that couple user intents with tool specifications, argument-grounded calls, and verifiable execution traces. However, collecting such data from human annotators is costly, time-consuming, and difficult to scale. We present a unified framework for synthesizing agentic data using only LLMs, without any human-in-the-loop supervision. This framework decomposes generation into modular pipelines that produce complete interaction records spanning task specifications, tool definitions, policy pseudocode, natural language exchanges, and execution traces. Records conform to strict syntactic and semantic constraints, ensuring machine-parseability and faithful alignment across inputs, outputs, and tool calls. Beyond single tasks, there is support for both multi-task and multi-turn agent interactions, enabling the construction of datasets that reflect the full spectrum of tool-use competencies. To ensure quality and consistency, the framework integrates constrained generation formats, JSON-schema validation, and judge-based filtering. This paper formalizes the schema for agentic records, details the prompt design principles that guide generation, and introduces scalable pipelines for high-quality synthetic data. By providing a reproducible, LLM-only alternative to manual collection, hence advancing the development of agentic LLMs capable of robust tool use.